Clear Sky Science · sv
Utforska gränserna för förtränade embeddings i maskinstyrd proteindesign: en fallstudie i att förutsäga AAV-vektors livsduglighet
Varför små förändringar i virusproteiner spelar roll
Genterapi förlitar sig ofta på ofarliga virus, såsom adeno-associerat virus (AAV), för att föra terapeutiska gener in i våra celler. Att göra dessa virala ”leveransfordon” säkrare och mer effektiva kräver vanligtvis bara att ett fåtal byggstenar i ett mycket långt proteinskal justeras. I denna studie ställs en bedrägligt enkel fråga: när de viktiga förändringarna är så små och lokala, kan dagens kraftfulla artificiella intelligensverktyg verkligen uppfatta dem tillräckligt väl för att vägleda bättre konstruktioner?
Hur datorer läser protein"meningar"
Modern proteindesign använder ofta djupinlärningsmodeller som behandlar aminosyrasekvenser lite som meningar i ett språk. Verktyg som ProtBERT och ESM2 lär sig att omvandla varje protein till ett paket siffror, kallat ett embedding, som sammanfattar mönster de sett i miljontals naturliga proteiner. Dessa förtränade embeddings är attraktiva eftersom de fångar rik information om struktur och funktion utan att kräva nya experiment. Men de byggdes mest för att förstå hela proteiner, inte de sällsynta men avgörande mutationerna som bioingenjörer inför i bara en liten yta.
Testa AI på ett verkligt arbetsdjur för genterapi
Författarna använde AAV2, en väl studerad vektor för genterapi, som ett strängt testfall. AAV2:s yttre skal, eller kapsid, är ett långt protein på 735 aminosyror, ändå ändrar ingenjörer vanligtvis bara ett kort stycke om cirka 20 till 50 positioner för att påverka hur viruset beter sig i kroppen. Teamet analyserade mer än 293 000 experimentellt mätta varianter vars mutationer var begränsade till ett fönster på 28 aminosyror. Varje variant märktes som antingen producerande livsdugliga viruspartiklar eller som oförmögna att göra det. Denna stora, noggrant annoterade datamängd gjorde det möjligt för forskarna att pröva hur olika sätt att koda sekvenser—traditionella one-hot-kodningar och flera varianter av ProtBERT- och ESM2-embeddings—presterar när den biologiska signalen kommer från en mycket liten region.
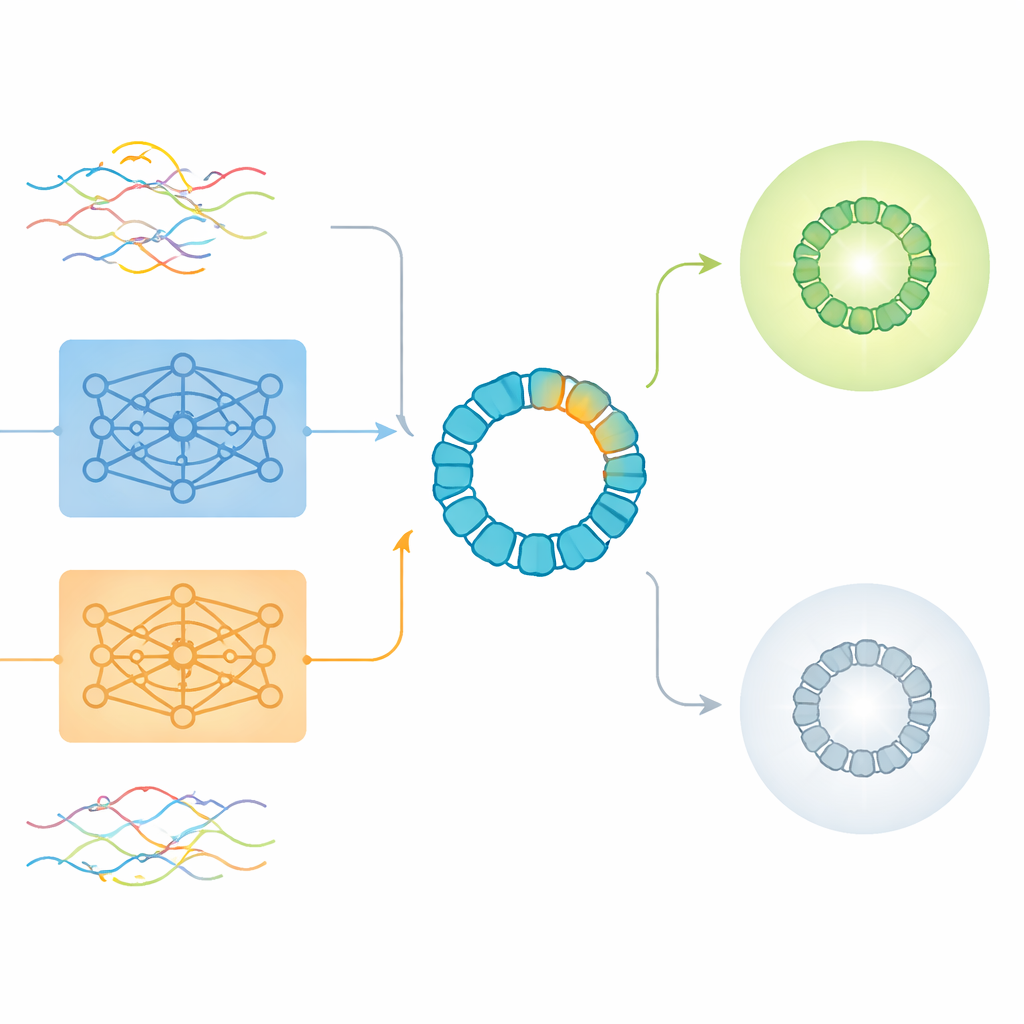
Vad råa embeddings missar och var de ändå hjälper
Studien undersökte först osuperviserade analyser, där algoritmer helt enkelt grupperar sekvenser efter likhet utan att få veta vilka som fungerar. Här gav globala sekvensnivå-embeddings från språkmodellerna rimliga grupperingar utifrån hur sekvenserna hade konstruerats, men de separerade inte tydligt livsdugliga från icke-livsdugliga varianter. Traditionella one-hot-kodningar tenderade istället att gruppera proteiner efter längd, en egenskap som visade sig ha endast svag koppling till livsduglighet. När forskarna gick över till övervakade uppgifter—att uttryckligen träna modeller för att förutsäga livsduglighet—fann de att aminosyra-nivå-embeddings, som genomsnittar information över alla rester, generellt överträffade globala sekvens-embeddings. Förvånande nog slog dock en komprimerad version av enkel one-hot-kodning marginellt de förtränade embeddings i total noggrannhet, särskilt när de användes med neurala nätverk.
Varför mutationsmönster är svåra att se
För att förstå dessa blandade resultat undersökte författarna vilka varianter som alla modeller var överens om och vilka som konsekvent förvirrade dem. Lättklassificerade sekvenser var nästan alltid livsdugliga och visade en tydlig "no-go"-zon: framgångsrika varianter tenderade att undvika mutationer i ett begravt strukturellt segment mellan vissa positioner, eller begränsa dem till subtila substitutioner. Svåra fall, däremot, såg utåt sett likartade ut vad gäller var och hur många mutationer de bar men visade sig vara icke-livsdugliga. Teamet byggde sedan syntetiska exempel där de spred eller koncentrerade mutationer längs hela proteinet. De fann att standardembeddings först började skilja grupper tydligt när hundratals positioner förändrades—mycket mer än vad som är praktiskt eller typiskt i verkliga bioingenjörskampanjer. Detta indikerar att allmänna proteinembeddings är relativt okänsliga för sparsamma eller starkt lokaliserade mutationer som ofta avgör om ett konstruerat protein fungerar.
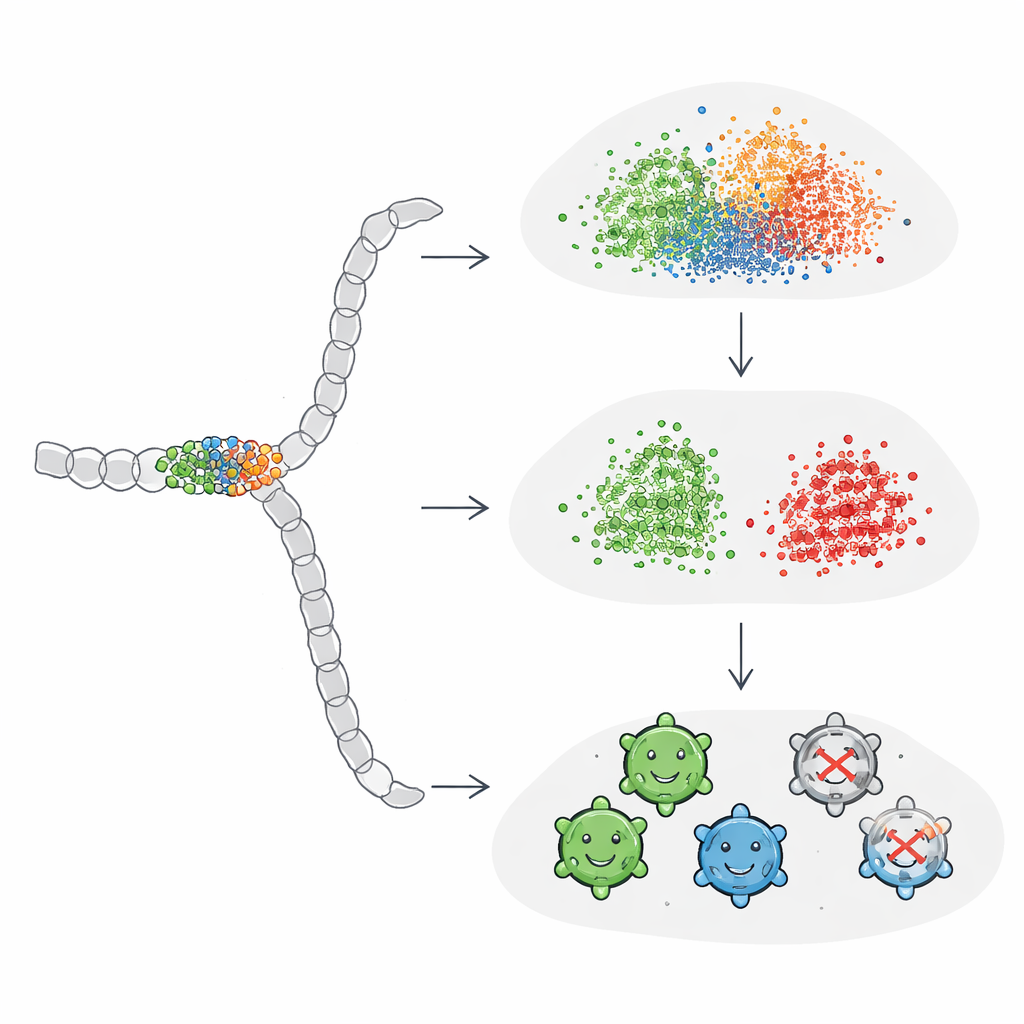
Finjustera AI för att fokusera på det som betyder något
Forskarna undersökte därefter om de kunde "lära" ProtBERT och ESM2 att uppmärksamma det lilla mutationsfönstret genom att finjustera modellerna direkt på AAV-livsduglighetsetiketterna. De kopplade ett enkelt klassifikationslager till varje modell och tränade hela systemet änd-till-änd. Efter finjustering förbättrades prestandan så att den matchade eller överträffade de bästa one-hot-baserade modellerna, och de resulterande embeddings visade äntligen en tydlig separation mellan livsdugliga och icke-livsdugliga sekvenser i visualiseringsdiagram. Intressant nog gynnades globala sekvensembeddings mest av denna process: när de vägleddes av uppgiftsspecifik återkoppling lärde de sig att förstärka inflytandet från de avgörande positionerna istället för att låta dem drunkna i resten av sekvensen.
Vad detta betyder för framtida proteindesign
För läsare som är intresserade av hur AI kommer att forma nästa generations genterapier och enzymer är budskapet nyanserat men hoppfullt. Färdiga proteinspråksmodeller, hur kraftfulla de än är, kan förbise de finmaskiga förändringar som ofta avgör om ett designat protein fungerar. Enkla kodningar och dimensionsreduktion håller fortfarande jämna steg i sådana situationer. Ändå kan man genom att finjustera dessa modeller på högkvalitativa experimentdata—även när mutationerna är få och tätt klustrade—rikta om dem mot de delar av sekvensen som betyder mest. I praktiska termer antyder detta arbete att kombinera stora förtränade modeller med uppgiftsspecifik reträning erbjuder en robust väg mot mer pålitlig, maskinstyrd design av virusvektorer och andra konstruerade proteiner.
Citering: Rodrigues, A.F., Ferraz, L., Balbi, L. et al. Exploring the limits of pre-trained embeddings in machine-guided protein design: a case study on predicting AAV vector viability. Sci Rep 16, 10974 (2026). https://doi.org/10.1038/s41598-026-45458-5
Nyckelord: proteinspråksmodeller, AAV-kapsiddesign, vektorer för genterapi, proteinembeddings, maskinstyrd proteinengineering