Clear Sky Science · ru
Исследование пределов предобученных эмбеддингов в машинно-управляемом дизайне белков: кейс предсказания жизнеспособности векторов AAV
Почему маленькие изменения в вирусных белках имеют значение
Генная терапия часто опирается на безвредные вирусы, такие как аденоассоциированный вирус (AAV), чтобы доставлять терапевтические гены в наши клетки. Сделать эти вирусные «транспортные средства» безопаснее и эффективнее обычно требуется изменить лишь несколько строительных блоков в очень длинной белковой оболочке. В этом исследовании задается на первый взгляд простая, но важная вопрос: когда значимые изменения настолько небольшие и локальные, могут ли современные мощные инструменты искусственного интеллекта действительно уловить их достаточно хорошо, чтобы направлять более удачный дизайн?
Как компьютеры читают «предложения» из белков
Современный дизайн белков часто использует глубокие модели, которые обращаются с последовательностями аминокислот как с предложениями в языке. Инструменты, такие как ProtBERT и ESM2, учатся преобразовывать каждый белок в набор чисел, называемый эмбеддингом, который резюмирует паттерны, обнаруженные в миллионах естественных белков. Эти предобученные эмбеддинги привлекательны тем, что содержат богатую информацию о структуре и функции без необходимости новых экспериментов. Однако они в основном создавались для понимания целых белков, а не редких, но ключевых мутаций, которые био-инженеры вводят в небольшой локальный участок.
Тестирование ИИ на реальном рабочем инструменте генной терапии
Авторы использовали AAV2, широко изучаемый вектор для генной терапии, в качестве строгого тестового случая. Внешняя оболочка AAV2, или капсид, представляет собой длинный белок из 735 аминокислот, однако инженеры обычно меняют лишь короткий фрагмент примерно в 20–50 позиций, чтобы изменить поведение вируса в организме. Команда проанализировала более 293 000 экспериментально измеренных вариантов, чьи мутации были ограничены 28–аминокислотным окном. Каждый вариант был помечен как либо образующий жизнеспособные вирусные частицы, либо не образующий. Этот большой, тщательно аннотированный набор данных позволил исследователям проверить, как разные способы кодирования последовательностей — традиционные one-hot представления и несколько вариантов эмбеддингов ProtBERT и ESM2 — справляются, когда биологический сигнал исходит из очень небольшой области.
Чего не видят сырые эмбеддинги и где они всё ещё полезны
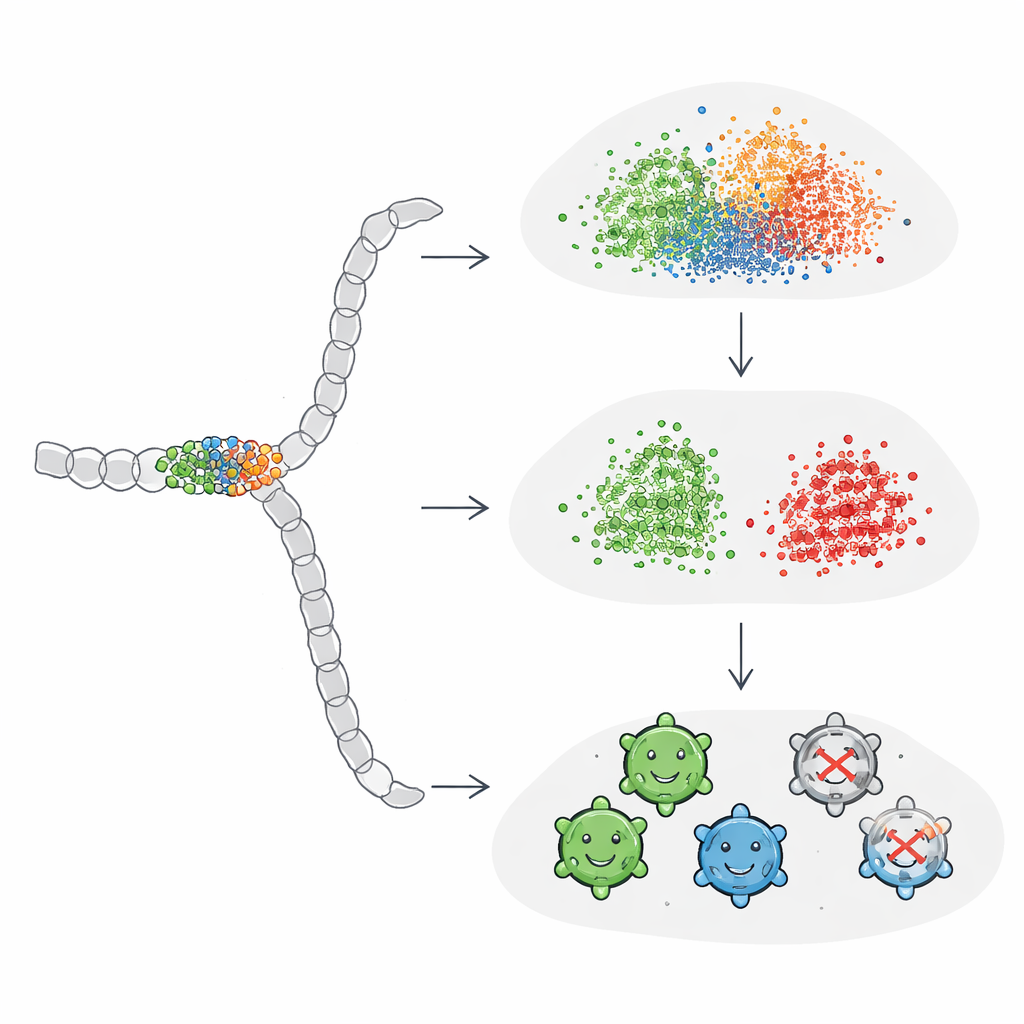
Сначала в исследовании рассмотрели несупервизируемый анализ, в котором алгоритмы просто группируют последовательности по сходству, не зная, какие из них функциональны. Здесь глобальные эмбеддинги последовательностей из языковых моделей давали разумные группировки в соответствии с тем, как были спроектированы последовательности, но они не явно разделяли жизнеспособные и нежизнеспособные варианты. Традиционные one-hot кодировки, напротив, склонны были группировать белки по длине — свойству, которое оказалось лишь слабо связанным с жизнеспособностью. При переходе к супервизируемым задачам — явной тренировке моделей для предсказания жизнеспособности — исследователи обнаружили, что эмбеддинги на уровне аминокислот, усредняющие информацию по всем остаткам, в целом превосходят глобальные эмбеддинги последовательностей. Удивительно, но сжатая версия простой one-hot кодировки немного превосходила предобученные эмбеддинги по общей точности, особенно в сочетании с нейронными сетями.
Почему схемы мутаций трудно заметить
Чтобы понять эти смешанные результаты, авторы изучили, на каких вариантах все модели сходились во мнении, а какие систематически их сбивали с толку. Легко классифицируемые последовательности почти всегда были жизнеспособными и показывали ясную «запретную» зону: успешные варианты, как правило, избегали мутаций в погруженном структурном сегменте между определёнными позициями или ограничивались тонкими заменами. Сложные случаи, наоборот, внешне выглядели похоже по расположению и числу мутаций, но оказывались нежизнеспособными. Команда затем создала синтетические примеры, где они растягивали или концентрировали мутации по всему белку. Они обнаружили, что стандартные эмбеддинги начинали чётко разделять группы только когда изменялись сотни позиций — значительно больше, чем практично или обычно в реальных инженерных кампаниях. Это указывает на то, что универсальные эмбеддинги белков относительно нечувствительны к редким или сильно локализованным мутациям, которые часто определяют успех или провал проектируемых белков.
Настройка ИИ, чтобы фокусироваться на важном
Далее исследователи изучили, можно ли «научить» ProtBERT и ESM2 уделять больше внимания маленькому окну мутаций, дообучив модели напрямую на метках жизнеспособности AAV. Они прикрепили к каждой модели простой классификационный слой и обучили всю систему насквозь. После дообучения производительность улучшилась до уровня лучших моделей на основе one-hot или превзошла их, а полученные эмбеддинги наконец показали чёткое разделение жизнеспособных и нежизнеспособных последовательностей на визуализациях. Примечательно, что глобальные эмбеддинги последовательностей выиграли от этого процесса больше всего: будучи направлены задачей, они научились усиливать влияние ключевых позиций вместо того, чтобы позволять им теряться на фоне остальной последовательности.
Что это означает для будущего дизайна белков
Для тех, кого интересует, как ИИ будет формировать следующее поколение генной терапии и ферментов, вывод сложен, но обнадёживает. Стандартные языковые модели белков, какими бы мощными они ни были, могут упускать из виду тонкие изменения, часто определяющие работоспособность проектируемого белка. Простые кодировки и методы уменьшения размерности всё ещё держат марку в таких задачах. Тем не менее, дообучая эти модели на качественных экспериментальных данных — даже когда мутаций немного и они тесно сгруппированы — исследователи могут перенастроить их на те участки последовательности, которые имеют наибольшее значение. Практически это означает, что сочетание больших предобученных моделей с задачеспецифичным дообучением предлагает надёжный путь к более точному машинно-управляемому дизайну вирусных векторов и других инженерных белков.
Цитирование: Rodrigues, A.F., Ferraz, L., Balbi, L. et al. Exploring the limits of pre-trained embeddings in machine-guided protein design: a case study on predicting AAV vector viability. Sci Rep 16, 10974 (2026). https://doi.org/10.1038/s41598-026-45458-5
Ключевые слова: языковые модели белков, дизайн капсида AAV, векторы генной терапии, эмбеддинги белков, машинно-управляемая инженерия белков