Clear Sky Science · ja
事前学習済み埋め込みが機械支援型タンパク質設計の限界に挑む:AAVベクター生存性予測のケーススタディ
ウイルスタンパク質のわずかな変化が重要な理由
遺伝子治療はしばしば、アデノ随伴ウイルス(AAV)のような無害なウイルスを用いて治療用遺伝子を細胞に届けます。これらのウイルス“輸送体”をより安全かつ有効にするには、非常に長いタンパク質外殻のごく一部の構成要素をわずかに調整するだけで済むことが多いです。本研究は一見単純な疑問を投げかけます:重要な変化が非常に小さく局所的であるとき、現在の強力な人工知能はそれらを十分に検出してより良い設計を導けるのでしょうか?
コンピュータはタンパク質の“文”をどう読むか
現代のタンパク質設計では、アミノ酸配列を言語の文のように扱う深層学習モデルが頻繁に用いられます。ProtBERTやESM2のようなツールは、何百万もの天然タンパク質から見られるパターンを要約する数値の束、すなわち埋め込みに各タンパク質を変換することを学習します。これらの事前学習済み埋め込みは、追加の実験を要さずに構造や機能に関する豊かな情報を捉えるため魅力的です。しかし、それらは主に全長タンパク質を理解するように設計されており、生物工学者がごく小さな領域に導入する稀だが重要な変異を対象にしているわけではありません。
実際の遺伝子治療ワークホースでAIを試す
著者らは、広く研究されている遺伝子治療ベクターであるAAV2を厳しいテストケースとして用いました。AAV2の外殻(カプシド)は735アミノ酸からなる長いタンパク質ですが、エンジニアは通常、ウイルスの体内挙動を変えるために約20〜50箇所程度の短い領域だけを改変します。研究チームは、変異が28アミノ酸の窓内に限定された293,000を超える実験的に測定されたバリアントを解析しました。各バリアントはウイルス粒子を産生するか失敗するかのいずれかにラベル付けされていました。この大規模で注意深く注釈されたデータセットにより、従来のワンホット符号化とProtBERTやESM2のいくつかの埋め込みの違いが、生物学的信号が非常に小さな領域から来る場合にどう性能を発揮するかを検証できました。
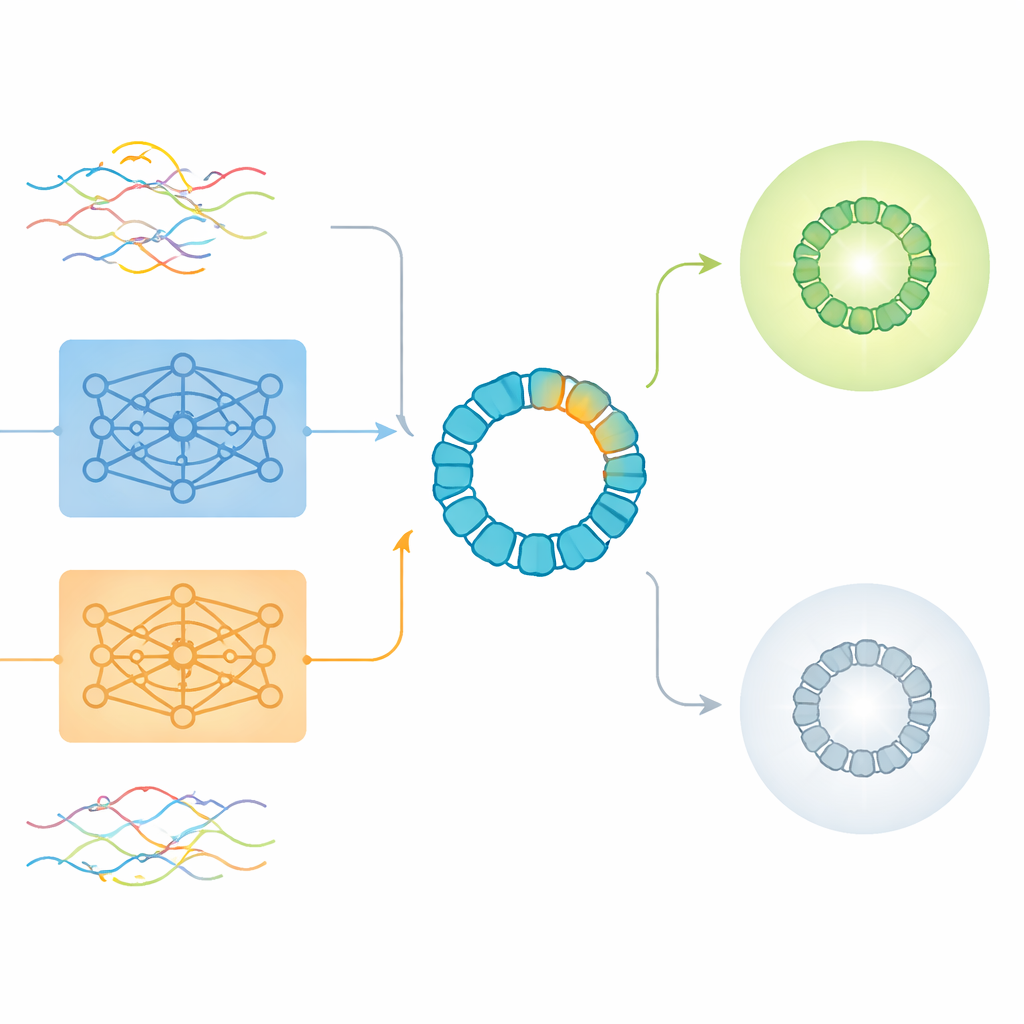
生の埋め込みが見落とすもの、そして役立つ場面
まず研究は教師なし解析を行い、アルゴリズムがどの配列が機能するかを教えられずに類似性で配列をクラスタリングする場合を見ました。ここでは、言語モデルから得られるグローバルな配列レベルの埋め込みは設計上の違いによって合理的なグルーピングを生み出しましたが、可溶性(生存性があるかどうか)で明瞭に分離することはできませんでした。従来のワンホット符号化は代わりにタンパク質の長さでグループ化する傾向があり、長さは生存性と弱くしか関連しないことが判明しました。研究者らが教師あり課題、すなわち明示的に生存性を予測するモデル訓練に移ったとき、残基レベルの埋め込み(全残基の情報を平均化したもの)は一般にグローバルな配列埋め込みより優れていました。驚くべきことに、単純なワンホット符号化を圧縮したバージョンが、特にニューラルネットワークと組み合わせた場合に、全体的な精度で事前学習埋め込みをわずかに上回ることがありました。
変異パターンが見えにくい理由
こうした混合した結果を理解するために、著者らは全モデルが一致して正しく分類したバリアントと、一貫して混同したバリアントを調べました。分類が容易な配列はほとんど常に生存性があり、ある「立ち入り禁止」領域を明確に示していました:成功するバリアントは特定の位置間の埋もれた構造セグメントでの変異を避けるか、微妙な置換にとどめる傾向がありました。対照的に、分類が難しいケースは、変異の位置や数が外見上は似ていても非生存性であることがありました。研究チームはさらに、変異をタンパク質全体に広げたり集中させたりした合成例を構築しました。標準的な埋め込みは数百箇所が変わる場合にようやくグループを明瞭に分離し始め、これは実際の生物工学で実用的または典型的な変化量よりはるかに多いことが分かりました。これは、一般目的のタンパク質埋め込みが、しばしば設計の成否を分ける稀で局所的な変異に対して比較的鈍感であることを示しています。
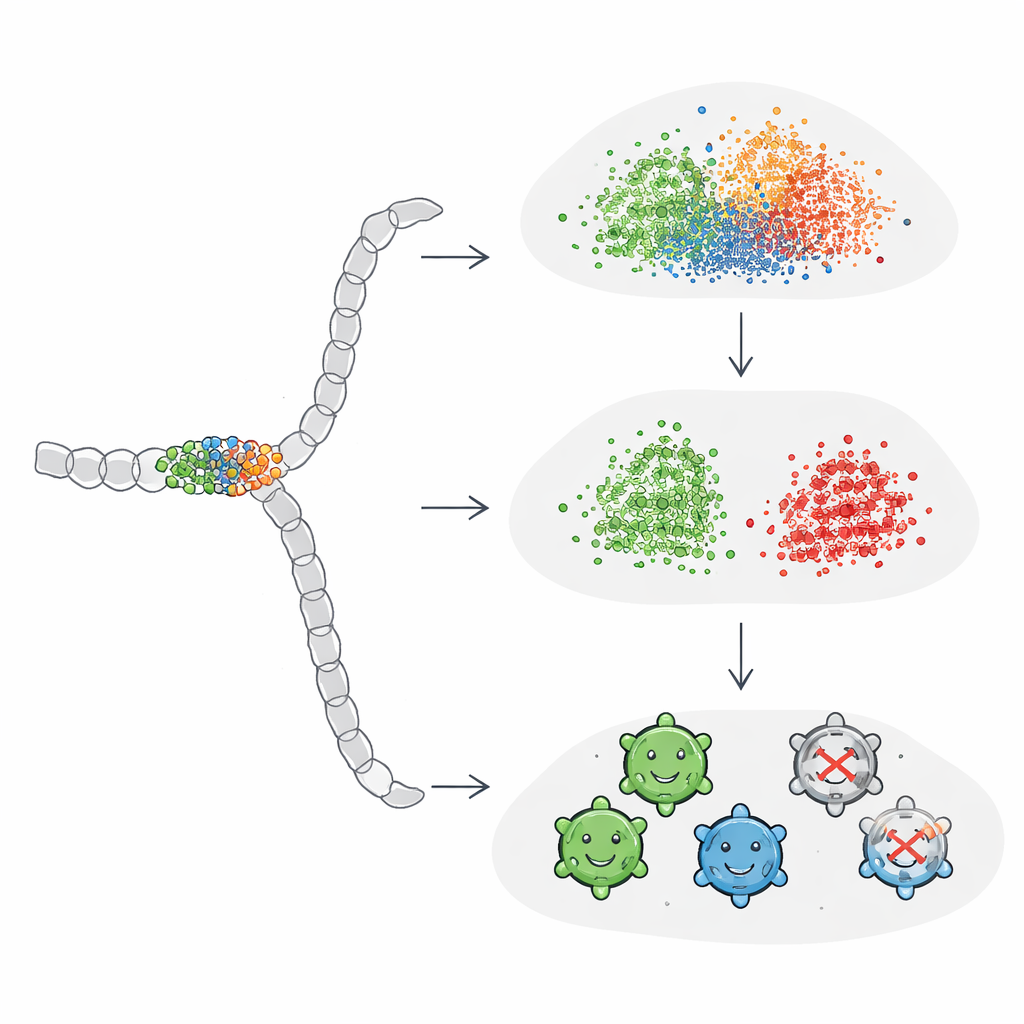
重要な部分に注目させるためのAIの調整
次に研究者らは、ProtBERTやESM2をAAVの生存性ラベルでファインチューニングして、小さな変異ウィンドウにより注意を向けさせられるかどうかを検討しました。各モデルに単純な分類層を付けてシステム全体をエンドツーエンドで訓練しました。ファインチューニング後、性能はワンホットベースの最良モデルと匹敵するか上回るようになり、可視化プロットでは生存性のある配列とない配列が明確に分離されるようになりました。興味深いことに、グローバルな配列埋め込みがこのプロセスから最も恩恵を受けました:タスク固有のフィードバックに導かれることで、重要な位置の影響を増幅し、他の部分に埋もれさせないことを学んだのです。
将来のタンパク質設計にとっての意味
次世代の遺伝子治療や酵素設計にAIがどう関わるかに関心のある読者にとって、メッセージは微妙だが希望を含みます。汎用のタンパク質言語モデルは強力である一方、設計したタンパク質が機能するかどうかを決める細かな変化を見落とすことがあります。こうした状況では、単純な符号化や次元削減が依然として有効です。しかし、高品質な実験データでこれらのモデルをファインチューニングすれば—変異が少なく密集している場合でも—モデルを配列の重要な部分に再び焦点を合わせることができます。実務的には、大規模な事前学習モデルとタスク固有の再学習を組み合わせることが、ウイルスベクターやその他の設計タンパク質の機械支援設計をより信頼できるものにする有望な道だとこの研究は示唆しています。
引用: Rodrigues, A.F., Ferraz, L., Balbi, L. et al. Exploring the limits of pre-trained embeddings in machine-guided protein design: a case study on predicting AAV vector viability. Sci Rep 16, 10974 (2026). https://doi.org/10.1038/s41598-026-45458-5
キーワード: タンパク質言語モデル, AAVカプシド設計, 遺伝子治療ベクター, タンパク質埋め込み, 機械支援型タンパク質工学