Clear Sky Science · ru
Интеграция альтернативных методов фрагментации в стандартные LC‑MS рабочие процессы с использованием единой модели глубокого обучения расширяет охват протеома
Увидеть больше белковой механики жизни
Каждая клетка вашего тела содержит тысячи различных белков, каждый из которых выполняет свою задачу. Современная масс‑спектрометрия уже способна прочитать многие из этих белков, дробя их на фрагменты и измеряя массу фрагментов, но важные фрагменты всё ещё остаются невидимыми — особенно нетипичные формы белков и тонкие химические модификации, которые управляют здоровьем и болезнями. В этом исследовании описан новый подход, позволяющий сочетать несколько продвинутых методов фрагментации с одной моделью искусственного интеллекта, благодаря чему учёные могут наблюдать значительно больше белкового мира в рутинном эксперименте.
Как обычно «читают» белки
В большинстве лабораторий белки сначала расщепляют на более короткие фрагменты — пептиды — и затем подают в прибор, который их разделяет и взвешивает. Чтобы определить последовательность пептида, прибор умышленно разрушает эти фрагменты и регистрирует паттерн фрагментов, как если бы разбили вазу и восстанавливали её форму по осколкам. В течение многих лет методом столкновений — когда пептиды ломаются при столкновении с молекулами газа — был основным, потому что он быстрый, надёжный и хорошо поддерживается программным обеспечением. Однако этот стандартный подход плохо удерживает хрупкие химические метки на белке и пропускает части сложных форм белков, оставляя «слепые зоны» в нашем понимании биологии.
Новые способы разламывать белки
Исследователи разработали и другие способы расщепления пептидов: с помощью ультрафиолетового света или пучков электронов, которые разрезают белки по другим путям и часто сохраняют уязвимые особенности. Эти подходы могут давать более богатые и информативные паттерны фрагментов, но они медленнее, технически сложнее и слабее поддерживаются инструментами анализа данных. Чтобы преодолеть это, авторы опирались на специализированный масс‑спектрометр, способный применять методы фрагментации на основе столкновений, электронов и фотонов в одной платформе и в временных рамках, необходимых для стандартных рабочих процессов жидкостной хроматографии–масс‑спектрометрии. Они тщательно настроили условия работы для каждого метода — например, энергию лазера или время облучения электронами — чтобы получить как можно больше полезных спектров из сложных образцов человеческих клеток.
Создание единой модели обучения
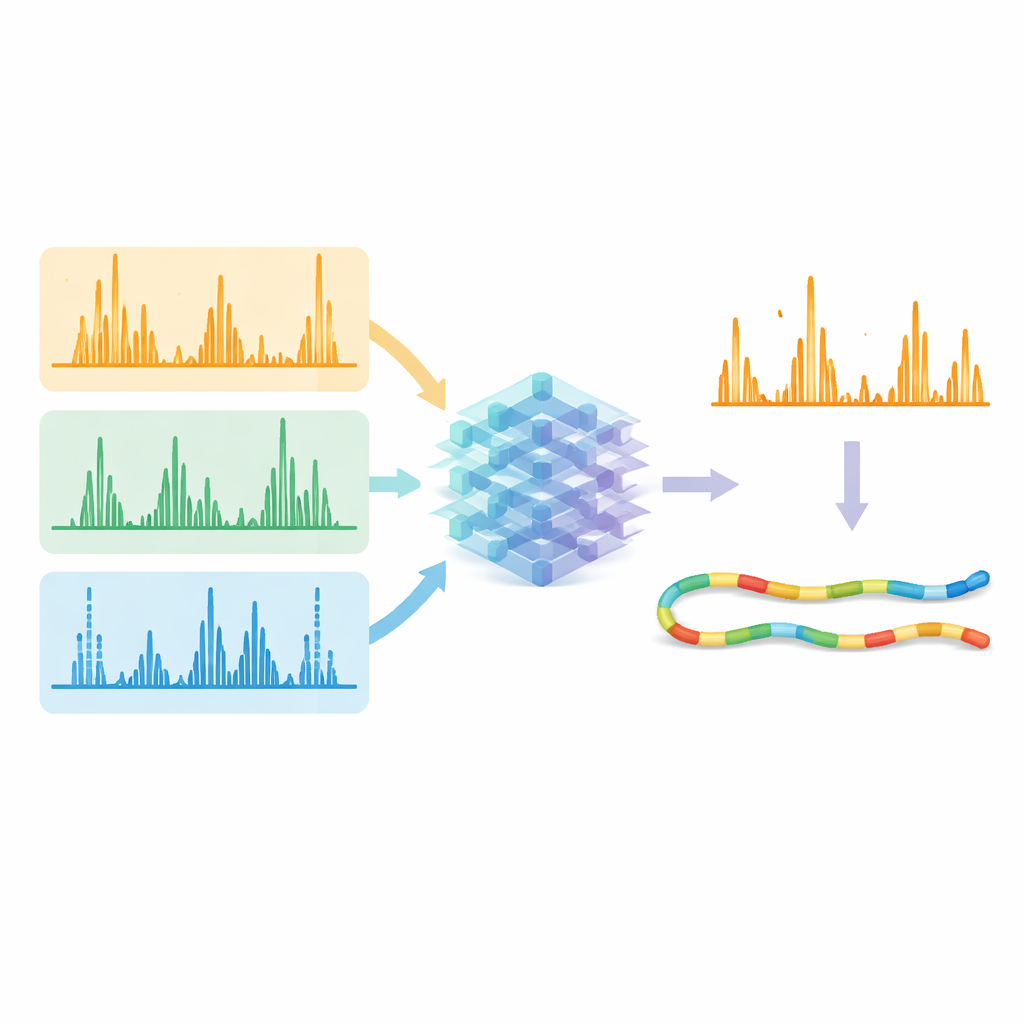
С этими оптимизированными методами команда сгенерировала обширные наборы данных, используя пять разных ферментов расщепления белков, что дало огромное разнообразие последовательностей пептидов. Затем они использовали эти наборы данных для обучения единой модели глубокого обучения — усовершенствованной версии системы под названием Prosit — чтобы предсказывать подробный паттерн и интенсивности пиков фрагментов для всех типов фрагментации одновременно. Вместо того чтобы обрабатывать каждый метод отдельно, модель принимает на вход последовательность пептида, его заряд и использованный метод фрагментации, а на выходе выдаёт ожидаемые интенсивности для сотен возможных типов фрагментов. Предсказанные спектры очень хорошо соответствовали экспериментальным данным во всех методах, показывая, что модель эффективно выучила характерные «отпечатки» света, электронов и столкновений.
Позволяя ИИ очищать сигнал
Реальное испытание заключалось в том, могут ли эти предсказания повысить число пептидов, уверенно идентифицируемых из сырых данных. Исследователи подали как измеренные спектры, так и предсказанные ИИ паттерны в существующие инструменты поиска и перерасчёта оценок. Когда программное обеспечение сосредотачивалось на фрагментах, которые модель считала сильными и ожидаемыми, правильные совпадения стали заметнее на фоне ложных. По данным, собранным с помощью разных методов фрагментации и ферментов, число уверенно идентифицированных совпадений пептид–спектр обычно выросло более чем на 10%, а в некоторых сложных случаях — более чем на 30%. Важно, что альтернативные методы с применением электронов и ультрафиолета теперь достигли эффективности идентификации, сопоставимой со стандартным методом столкновений, при этом обеспечивая более широкий охват последовательностей и дополнительную уникальную информацию о белках.
Внедрение продвинутых методов в повседневную практику
Поскольку модель ИИ доступна бесплатно и интегрирована в популярное программное обеспечение для масс‑спектрометрии, её можно использовать не только для традиционных целевых измерений, но и для новых стратегий сбора данных без предварительного отбора (data‑independent acquisition), которые сканируют широкие участки образца одновременно. Испытания на смесях человеческих, растительных и бактериальных клеток показали, что модель хорошо обобщается между видами. В практическом плане эта работа устраняет ключевой барьер, который держал мощные, но малоиспользуемые методы фрагментации в пределах специалистов. Объединив разные способы разламывания белков в одну предсказательную модель, исследование проложило путь к повседневному, высокоохватному анализу сложных белковых ландшафтов, облегчая учёным обнаружение редких вариантов, картирование модификаций и, в конечном счёте, получение более полной картины поведения белков в здоровье и болезни.
Цитирование: Levin, N., Saylan, C.C., Lapin, J. et al. Integration of alternative fragmentation techniques into standard LC-MS workflows using a single deep learning model enhances proteome coverage. Nat Methods 23, 805–814 (2026). https://doi.org/10.1038/s41592-026-03042-9
Ключевые слова: протеомика, масс-спектрометрия, глубокое обучение, фрагментация белков, спектральное предсказание