Clear Sky Science · pt
Seleção adaptativa de características com relevância baseada em gradiente para sistemas de detecção de intrusões
Por que ataques ocultos em redes de energia importam
Redes elétricas modernas e sistemas industriais de energia hoje dependem de fluxos constantes de dados digitais para manter o fornecimento de eletricidade de forma segura e eficiente. Para proteger informações sensíveis, quase todo esse tráfego é criptografado—preso em uma espécie de envelope digital. Mas a mesma criptografia que protege clientes comuns também pode ocultar os rastros de invasores que tentam injetar comandos falsos ou roubar dados. Este artigo apresenta uma nova forma de detectar rapidamente e com precisão esses ataques ocultos em tráfego criptografado, sem abrir os envelopes nem desacelerar a rede.
O desafio de ver através de fechaduras digitais
Ferramentas tradicionais de detecção de intrusões costumam inspecionar pacotes de rede, comparando seus conteúdos com padrões conhecidos de comportamento malicioso. A criptografia torna essa abordagem quase impossível, já que o conteúdo fica embaralhado e deve permanecer privado. Ao mesmo tempo, atacantes aprenderam a canalizar suas atividades por canais criptografados, misturando-se ao tráfego legítimo. Trabalhos anteriores tentaram aplicar inteligência artificial ao tráfego criptografado, mas muitos métodos exigem grande poder computacional, têm dificuldade em tempo real ou falham quando os dados são ruidosos ou manipulados intencionalmente. Isso é particularmente perigoso em sistemas de energia, como redes inteligentes e SCADA, onde até pequenos erros de classificação podem causar instabilidade de fornecimento ou comandos incorretos de controle.
Escolher as pistas certas em vez de todos os dados
Os autores focam em uma ideia-chave: nem todo aspecto mensurável do tráfego de rede é igualmente útil para detectar ataques. Em vez de alimentar dezenas de medidas brutas em um algoritmo de aprendizado, eles propõem um método de seleção adaptativa de características (AFS) que escolhe automaticamente as pistas mais informativas. Primeiro, utilizam uma ferramenta estatística padrão, análise de componentes principais (PCA), para ranquear características do tráfego—como tamanhos de pacotes, variações de tempo e atrasos de resposta—pela variabilidade e correlação. Em seguida, em vez de confiar apenas nesse ranqueamento, testam as características uma a uma em um classificador e acompanham quanto a qualidade da detecção melhora a cada inclusão. Isso cria uma curva de desempenho que revela quais características realmente fazem diferença.
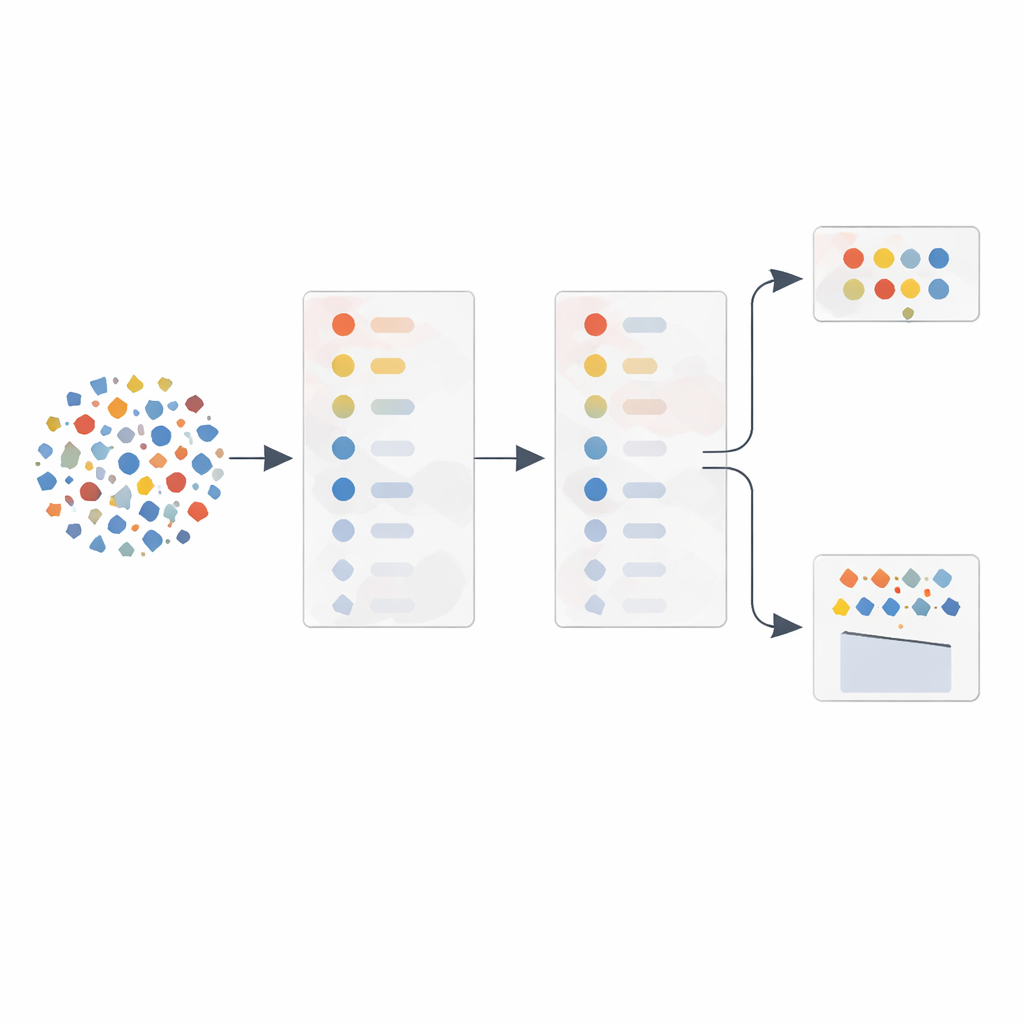
Deixar o gradiente dos dados guiar a busca
O cerne do método é o que os autores chamam de relevância baseada em gradiente. À medida que vão adicionando características na ordem fornecida pela PCA, medem o quanto a pontuação de detecção salta ou se estabiliza. Características que causam melhorias acentuadas nessa curva são tratadas como especialmente valiosas, mesmo que sua importância estatística inicial parecesse modesta. Características que trazem pouco ou nenhum benefício—frequentemente por serem redundantes com as anteriores—são deixadas de lado. A partir desse processo constroem-se dois conjuntos flexíveis de características: um com apenas as que provocam saltos acentuados para operação enxuta, e outro que complementa esse conjunto com algumas das principais características para maior robustez. Um componente separado monitora quão ruidosos ou adulterados parecem os dados de treinamento e escolhe automaticamente entre o conjunto menor ou maior ao classificar novo tráfego.
Comprovando a ideia em tráfego criptografado real
Para testar a abordagem, os pesquisadores usaram um conjunto de dados público de fluxos DNS-over-HTTPS criptografados, que mistura navegação normal com túneis maliciosos projetados para contrabandear dados. Treinaram um modelo de regressão logística—um classificador relativamente simples—em tráfego sumarizado por até 27 diferentes características de tempo e tamanho. Aplicando a seleção adaptativa de características, conseguiram reduzir o número de características ativas para apenas quatro em condições de alto ruído, ou onze em ruído menor, mantendo ou melhorando a acurácia. Em milhares de experimentos repetidos, o método adaptativo aumentou a taxa média de detecção em cerca de um quarto em comparação com uma abordagem baseada apenas em PCA e ainda mais em comparação com o uso de todas as características sem seleção. Ao mesmo tempo, reduziu o tempo de treinamento em aproximadamente um terço e cortou significativamente o uso de memória.
O que isso significa para redes mais seguras e inteligentes
Em termos práticos, o estudo mostra que escolher com cuidado quais "pistas" alimentar um detector de intrusões pode torná-lo mais preciso e mais rápido, mesmo ao trabalhar com tráfego criptografado que deve permanecer privado. Em vez de bisbilhotar pacotes, o sistema baseia-se em como padrões de tamanhos e tempos mudam quando ataques estão presentes, e adapta-se automaticamente quando os dados ficam mais ruidosos ou mais protegidos. Para redes de energia que precisam equilibrar segurança, privacidade e resposta em tempo real, esse tipo de filtragem adaptativa e leve pode se tornar um componente fundamental. Embora os resultados até agora venham de experimentos controlados em um conjunto de dados, os autores argumentam que a mesma estratégia pode ser integrada em ferramentas de monitoramento existentes e estendida a outros ambientes criptografados, ajudando infraestruturas críticas a se manterem um passo à frente de ciberataques cada vez mais furtivos.
Citação: Lee, YR., Jeon, SE., Lee, SJ. et al. Adaptive feature selection with gradient-based relevance for intrusion detection systems. Sci Rep 16, 14308 (2026). https://doi.org/10.1038/s41598-026-42295-4
Palavras-chave: tráfego criptografado, detecção de intrusão, segurança de redes inteligentes, seleção de características, detecção de ciberataques