Clear Sky Science · de
Adaptive Merkmalsauswahl mit gradientenbasierter Relevanz für Intrusion-Detection-Systeme
Warum versteckte Angriffe in Energienetzen wichtig sind
Moderne Stromnetze und industrielle Energiesysteme sind mittlerweile auf kontinuierliche digitale Datenströme angewiesen, damit die Energieversorgung sicher und effizient bleibt. Zum Schutz sensibler Informationen ist fast der gesamte Datenverkehr verschlüsselt – in einer Art digitalem Umschlag. Dieselbe Verschlüsselung, die gewöhnliche Kundendaten schützt, kann jedoch auch die Spuren von Angreifern verbergen, die gefälschte Befehle einschleusen oder Daten abziehen wollen. Diese Arbeit stellt eine neue Methode vor, solche versteckten Angriffe in verschlüsseltem Verkehr schnell und genau zu erkennen, ohne die Umschläge zu öffnen oder das Netz zu verlangsamen.
Die Herausforderung, digitale Schlösser zu durchschauen
Traditionelle Intrusion-Detection-Werkzeuge blicken oft in Netzpakete hinein und vergleichen ihre Inhalte mit bekannten Mustern bösartiger Aktivitäten. Verschlüsselung macht dieses Vorgehen nahezu unmöglich, da der Inhalt unlesbar bleibt und vertraulich bleiben muss. Gleichzeitig haben Angreifer gelernt, ihre Aktivitäten durch verschlüsselte Kanäle zu tunneln und sich unter normalen Nutzern zu verstecken. Bisherige Arbeiten versuchten, künstliche Intelligenz auf verschlüsselten Verkehr anzuwenden, doch viele Methoden sind rechenintensiv, kommen in Echtzeit an ihre Grenzen oder versagen, wenn die Daten verrauscht oder absichtlich manipuliert sind. Das ist besonders riskant in Energiesystemen wie Smart Grids und SCADA-Netzen, wo schon kleine Klassifikationsfehler zu Instabilitäten oder falschen Steuerbefehlen führen können.
Die richtigen Hinweise auswählen statt aller Daten
Die Autoren konzentrieren sich auf eine zentrale Idee: Nicht jeder messbare Aspekt des Netzwerkverkehrs ist gleichermaßen nützlich zur Erkennung von Angriffen. Statt Dutzende von Rohmessungen in einen Lernalgorithmus zu speisen, schlagen sie eine adaptive Merkmalsauswahl (AFS) vor, die automatisch die informativsten Hinweise auswählt. Zunächst verwenden sie ein gängiges statistisches Werkzeug, die Hauptkomponentenanalyse (PCA), um Merkmale des Verkehrs – wie Paketgrößen, Zeitvariationen und Antwortverzögerungen – danach zu ordnen, wie stark sie variieren und wie stark sie zusammenhängen. Statt dieser Reihenfolge blind zu vertrauen, testen sie dann Merkmale nacheinander in einem Klassifikator und verfolgen, wie stark sich die Erkennungsleistung verbessert, wenn ein Merkmal hinzugefügt wird. So entsteht eine Leistungskurve, die zeigt, welche Merkmale tatsächlich Gewicht haben.
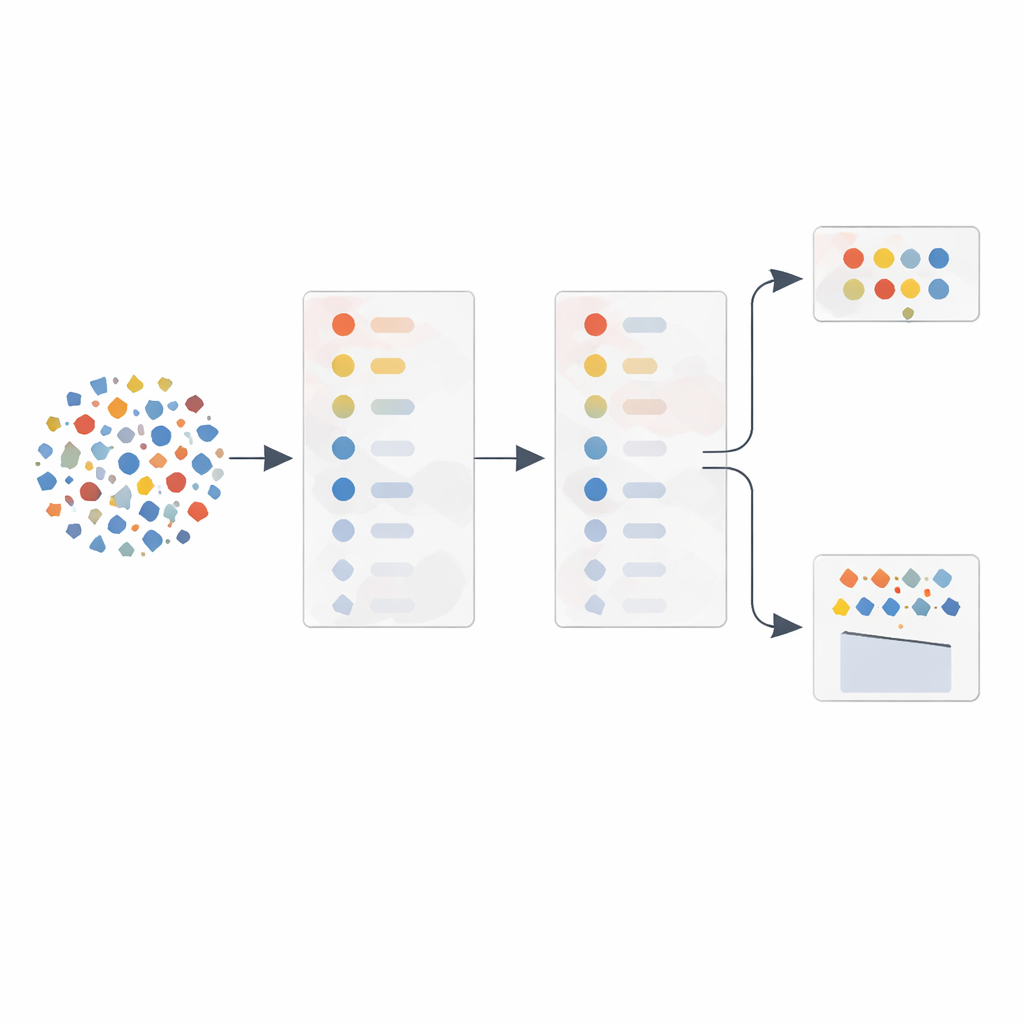
Den Gradienten der Daten die Suche überlassen
Der Kern der Methode ist das, was die Autoren gradientenbasierte Relevanz nennen. Während sie Merkmale schrittweise in PCA-Reihenfolge hinzufügen, messen sie, wie steil die Erkennungskennzahl ansteigt oder abflacht. Merkmale, die starke Verbesserungen in dieser Kurve bewirken, werden als besonders wertvoll betrachtet, selbst wenn ihre anfängliche statistische Wichtigkeit nur mäßig war. Merkmale, die wenig oder keinen Nutzen bringen – oft weil sie mit früheren redundant sind – werden verworfen. Aus diesem Prozess entstehen zwei flexible Merkmalssets: eines mit nur den starken Sprungmerkmalen für einen schlanken Betrieb und ein weiteres, das diese um einige top‑gereihte Merkmale für zusätzliche Robustheit ergänzt. Eine separate Komponente überwacht, wie verrauscht oder manipuliert die Trainingsdaten erscheinen, und wählt dann beim Klassifizieren neuen Verkehrs automatisch zwischen dem kleineren oder größeren Satz.
Die Idee an echtem verschlüsselten Verkehr belegen
Zur Prüfung ihres Ansatzes nutzten die Forscher einen öffentlichen Datensatz von verschlüsselten DNS-over-HTTPS-Flows, der normales Browsen mit bösartigen Tunneln mischt, die Daten einschmuggeln sollen. Sie trainierten ein logistisches Regressionsmodell – einen vergleichsweise einfachen Klassifikator – auf Verkehrsdatensätzen, die durch bis zu 27 verschiedene Zeit- und Größenmerkmale zusammengefasst waren. Mit ihrer adaptiven Merkmalsauswahl konnten sie die Zahl aktiver Merkmale unter starken Rauschbedingungen auf nur vier und bei geringerem Rauschen auf elf reduzieren, während die Genauigkeit erhalten blieb oder sich verbesserte. Über tausende wiederholte Versuche steigerte die adaptive Methode die durchschnittliche Erkennungsrate um etwa ein Viertel gegenüber einem reinen PCA-Ansatz und noch stärker im Vergleich zur Nutzung aller Merkmale ohne Auswahl. Gleichzeitig verkürzte sich die Trainingszeit um rund ein Drittel und der Speicherbedarf sank deutlich.
Was das für sicherere, intelligentere Netze bedeutet
Einfach gesagt zeigt die Studie, dass ein sorgfältiges Auswählen der „Hinweise“, die einem Intrusion-Detektor zugeführt werden, diesen sowohl schärfer als auch schneller machen kann, selbst bei verschlüsseltem Verkehr, der privat bleiben muss. Statt Pakete aufzubrechen, stützt sich das System darauf, wie sich Muster von Größen und Zeitpunkten verändern, wenn Angriffe stattfinden, und es passt sich automatisch an, wenn die Daten verrauschter oder stärker geschützt werden. Für Energiesysteme, die Sicherheit, Privatsphäre und Echtzeitreaktion ausbalancieren müssen, könnte diese Art leichtgewichtiger, adaptiver Filterung ein wichtiges Bauelement werden. Obwohl die bisherigen Ergebnisse aus kontrollierten Experimenten mit einem Datensatz stammen, argumentieren die Autoren, dass dieselbe Strategie in bestehende Überwachungswerkzeuge integriert und auf andere verschlüsselte Umgebungen übertragen werden kann, um kritische Infrastrukturen gegenüber immer heimlicheren Cyberangriffen einen Schritt voraus zu halten.
Zitation: Lee, YR., Jeon, SE., Lee, SJ. et al. Adaptive feature selection with gradient-based relevance for intrusion detection systems. Sci Rep 16, 14308 (2026). https://doi.org/10.1038/s41598-026-42295-4
Schlüsselwörter: verschlüsselter Datenverkehr, Intrusion Detection, Sicherheit von Smart Grids, Merkmalsauswahl, Erkennung von Cyberangriffen