Clear Sky Science · pl
Adaptacyjny wybór cech z wykorzystaniem relewancji opartej na gradiencie dla systemów wykrywania włamań
Dlaczego ukryte ataki w sieciach energetycznych mają znaczenie
Nowoczesne sieci elektroenergetyczne i przemysłowe systemy energetyczne polegają na ciągłych strumieniach danych cyfrowych, aby zapewnić bezpieczne i efektywne dostarczanie energii. Aby chronić wrażliwe informacje, niemal cały ten ruch jest szyfrowany — zamknięty w rodzaj cyfrowej koperty. Jednak to samo szyfrowanie, które chroni zwykłych użytkowników, może też ukrywać ślady hakerów próbujących wstrzykiwać fałszywe polecenia lub kraść dane. W artykule przedstawiono nowy sposób szybkiego i dokładnego wykrywania tych ukrytych ataków w zaszyfrowanym ruchu, bez otwierania kopert i bez spowalniania sieci.
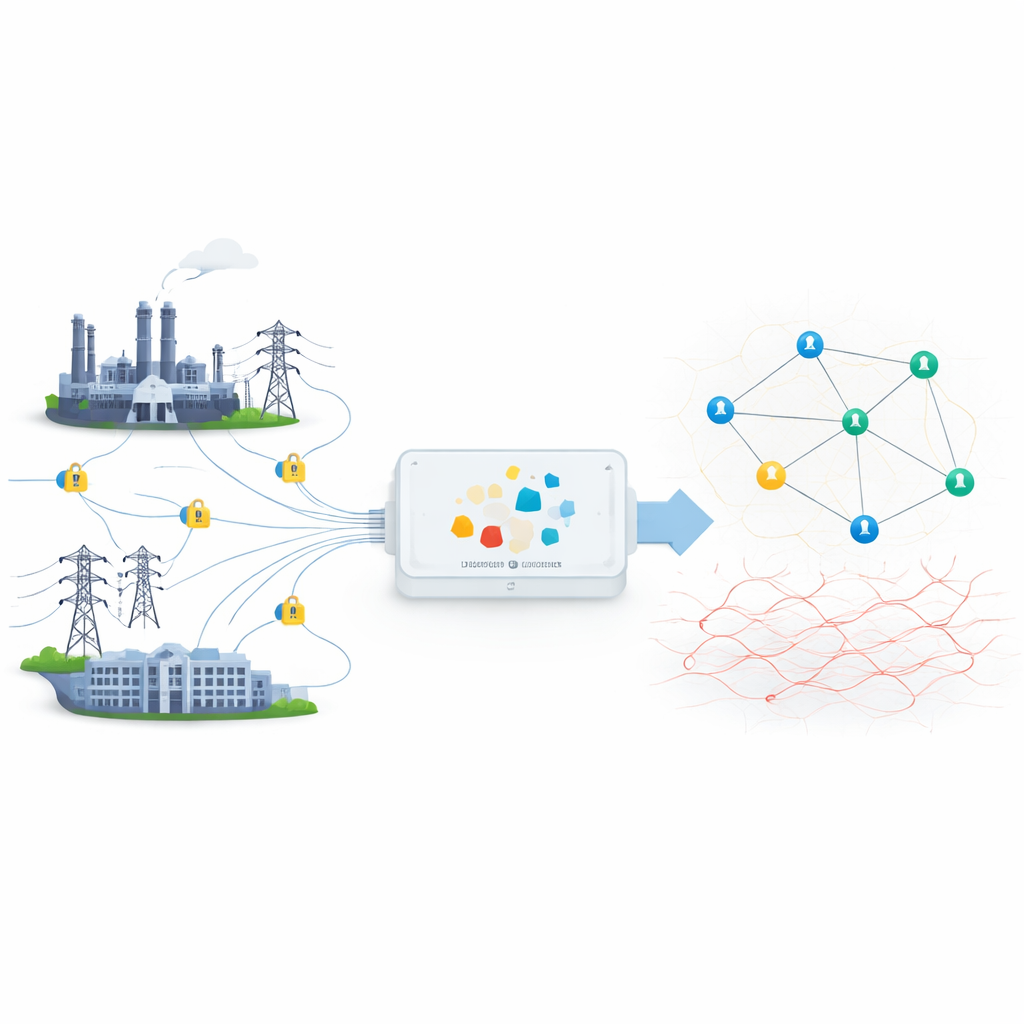
Wyzwaniem jest przejrzeć przez cyfrowe zamki
Tradycyjne narzędzia wykrywania włamań często analizują zawartość pakietów sieciowych, porównując ją ze znanymi wzorcami złośliwych zachowań. Szyfrowanie czyni to podejście praktycznie niemożliwym, ponieważ zawartość jest zaszyfrowana i musi pozostać prywatna. Jednocześnie napastnicy nauczyli się tunelować swoje działania przez zaszyfrowane kanały, wtapiając się w normalny ruch użytkowników. Dotychczasowe prace próbowały zastosować sztuczną inteligencję do analizy zaszyfrowanego ruchu, ale wiele metod wymaga intensywnych obliczeń, ma trudności z działaniem w czasie rzeczywistym lub zawodzą przy hałasie czy celowej manipulacji danymi. To jest szczególnie niebezpieczne w systemach energetycznych, takich jak inteligentne sieci (smart grid) i sieci SCADA, gdzie nawet niewielkie błędy klasyfikacji mogą powodować niestabilność zasilania lub błędne działania sterujące.
Wybieranie właściwych wskazówek zamiast wszystkich danych
Autorzy skupiają się na kluczowej idei: nie każdy mierzalny aspekt ruchu sieciowego jest tak samo użyteczny do wykrywania ataków. Zamiast podawać dziesiątki surowych pomiarów do algorytmu uczącego się, proponują metodę adaptacyjnego wyboru cech (AFS), która automatycznie wybiera najbardziej informatywne wskazówki. Najpierw stosują standardowe narzędzie statystyczne — analizę głównych składowych (PCA) — aby uszeregować cechy ruchu, takie jak rozmiary pakietów, zmiany czasu i opóźnienia odpowiedzi, według ich zmienności i wzajemnych powiązań. Następnie, zamiast polegać wyłącznie na tym rankingu, testują cechy pojedynczo w klasyfikatorze i śledzą, jak bardzo poprawia się jakość wykrywania za każdym dodaniem cechy. Powstaje w ten sposób krzywa wydajności pokazująca, które cechy rzeczywiście mają znaczenie.
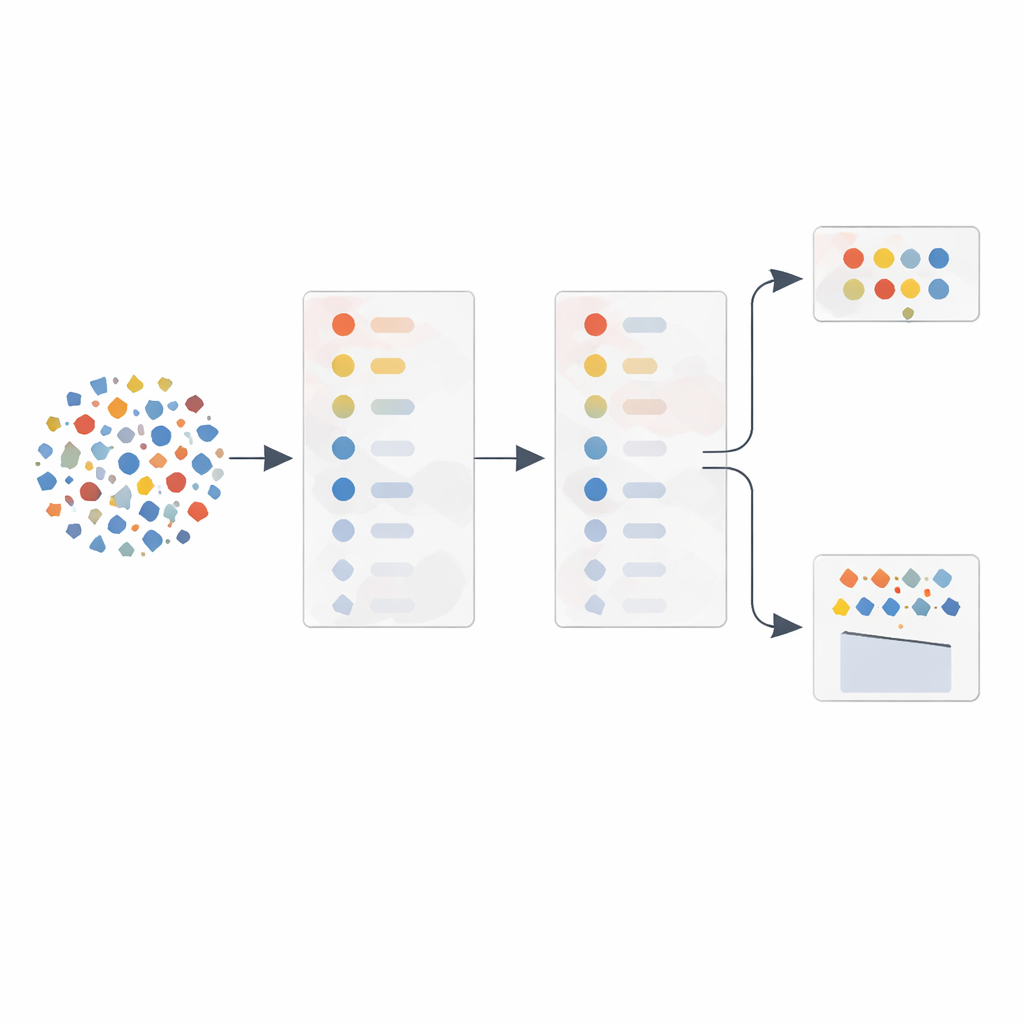
Pozwolenie gradientowi danych kierować poszukiwaniem
Rdzeniem metody jest to, co autorzy nazywają relewancją opartą na gradiencie. W miarę dodawania cech w kolejności PCA mierzą, jak gwałtownie wzrasta lub wygładza się wynik wykrywania. Cechy powodujące strome poprawy na tej krzywej traktowane są jako szczególnie wartościowe, nawet jeśli ich początkowa ważność statystyczna wydawała się umiarkowana. Cechy, które wnoszą niewielką lub żadną korzyść — często dlatego, że są redundantne wobec wcześniejszych — są odsuwane na bok. Z tego procesu budują dwa elastyczne zbiory cech: jeden zawierający tylko cechy powodujące strome skoki dla lekkiej, wydajnej pracy, oraz drugi, który uzupełnia je kilkoma najwyżej ocenionymi cechami dla większej odporności. Osobny komponent monitoruje, jak zaszumione lub zmanipulowane wydają się dane treningowe, i automatycznie wybiera między mniejszym a większym zbiorem przy klasyfikacji nowego ruchu.
Weryfikacja pomysłu na rzeczywistym zaszyfrowanym ruchu
Aby przetestować swoje podejście, badacze wykorzystali publiczny zestaw danych przepływów DNS-over-HTTPS, który miesza normalne przeglądanie z złośliwymi tunelami zaprojektowanymi do przemytu danych. Trenowali model regresji logistycznej — stosunkowo prosty klasyfikator — na ruchu podsumowanym przez maksymalnie 27 różnych cech związanych z czasem i rozmiarami. Stosując adaptacyjny wybór cech, zredukowali liczbę aktywnych cech do zaledwie czterech w warunkach wysokiego szumu, lub jedenastu przy niższym poziomie szumów, przy zachowaniu lub poprawie dokładności. W tysiącach powtórzonych prób metoda adaptacyjna zwiększyła średni współczynnik wykrywania o około jedną czwartą w porównaniu ze standardowym podejściem opartym wyłącznie na PCA, a jeszcze bardziej w porównaniu z użyciem wszystkich cech bez selekcji. Jednocześnie skróciła czas treningu o około jedną trzecią i znacznie zmniejszyła zużycie pamięci.
Co to oznacza dla bezpieczniejszych, inteligentniejszych sieci
Mówiąc prosto, badanie pokazuje, że staranny wybór, które „wskazówki” podawać detektorowi włamań, może uczynić go jednocześnie bardziej celowanym i szybszym, nawet przy pracy z zaszyfrowanym ruchem, który musi pozostać prywatny. Zamiast włamywać się do pakietów, system opiera się na tym, jak zmieniają się wzorce rozmiarów i czasów, gdy występują ataki, i automatycznie dostosowuje się, gdy dane stają się bardziej zaszumione lub lepiej chronione. Dla sieci energetycznych, które muszą równoważyć bezpieczeństwo, prywatność i reakcję w czasie rzeczywistym, tego rodzaju lekkie, adaptacyjne filtrowanie może stać się kluczowym elementem. Choć wyniki pochodzą na razie z kontrolowanych eksperymentów na jednym zbiorze danych, autorzy twierdzą, że tę samą strategię można włączyć do istniejących narzędzi monitorujących i rozszerzyć na inne zaszyfrowane środowiska, pomagając infrastrukturze krytycznej wyprzedzać coraz bardziej ukryte cyberataki.
Cytowanie: Lee, YR., Jeon, SE., Lee, SJ. et al. Adaptive feature selection with gradient-based relevance for intrusion detection systems. Sci Rep 16, 14308 (2026). https://doi.org/10.1038/s41598-026-42295-4
Słowa kluczowe: zaszyfrowany ruch, wykrywanie włamań, bezpieczeństwo sieci energetycznych, selekcja cech, wykrywanie cyberataków