Clear Sky Science · pl
STHELAR, wielotkankowy zbiór danych łączący transkryptomikę przestrzenną i histologię do anotacji typów komórek
Dlaczego oglądanie raka pod mikroskopem to za mało
Onkolodzy wciąż w dużej mierze polegają na tym, co widzą przez mikroskop: cienko krojone, różowo‑fioletowe tkanki barwione hematoksyliną i eozyną (H&E). Te obrazy ujawniają kształty i wzory, ale nie pokazują bezpośrednio, które geny są aktywne w poszczególnych komórkach. Nowe źródło danych o nazwie STHELAR łączy te dwa światy, powiązując znajomy widok preparatów tkankowych z zaawansowanymi „przestrzennymi” pomiarami aktywności genów. Dla czytelników ma to znaczenie, ponieważ otwiera drogę do szybszych, tańszych narzędzi, które być może w przyszłości będą potrafiły odczytać molekularny skład nowotworów wyłącznie z zwykłych obrazów cyfrowych.
Postrzeganie guza jako zatłoczonej dzielnicy
Guzy to coś więcej niż zbiór wadliwych komórek nowotworowych; to zatłoczone dzielnice wypełnione komórkami układu odpornościowego, naczyniami krwionośnymi, komórkami podporowymi i tkanką prawidłową. Skład i rozmieszczenie tych mieszkańców — mikrośrodowisko guza — może decydować o tym, jak nowotwór rośnie i jak reaguje na leczenie. Transkryptomika przestrzenna, nowa technologia, potrafi mapować, które geny są włączone w pojedynczych komórkach, zachowując jednocześnie ich dokładne położenie w tkance. Jednak te eksperymenty są kosztowne i technicznie wymagające, więc nie są jeszcze rutynowo stosowane w opiece klinicznej. W przeciwieństwie do tego, skany wysokiej rozdzielczości preparatów H&E są już powszechne, tanie w przechowywaniu i używane na całym świecie. Główny pomysł stojący za STHELAR polega na wykorzystaniu ograniczonego zestawu eksperymentów z transkryptomiką przestrzenną jako „nauczyciela” dla milionów komórek widocznych na standardowych obrazach H&E.
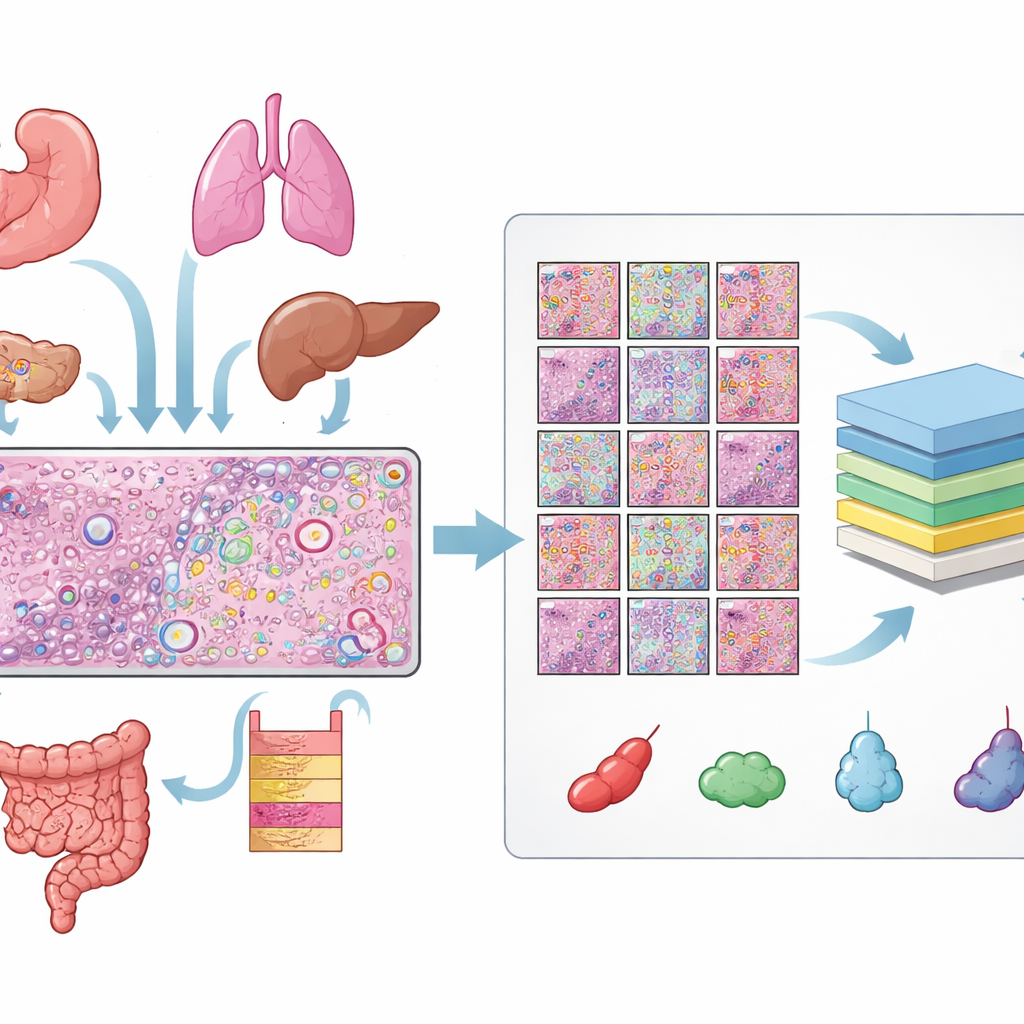
Budowanie ogromnej biblioteki oznakowanych komórek
Autorzy zgromadzili dane z 31 przekrojów tkanki mierzonych platformą transkryptomiki przestrzennej Xenium firmy 10x Genomics, obejmujących 16 typów tkanki ludzkiej oraz 22 próbki nowotworowe i 9 nienowotworowych. Dla każdego przekroju mieli trzy dopasowane widoki: preparat H&E, obraz fluorescencyjny pokazujący jądra komórkowe oraz mapę pojedynczych cząsteczek RNA. Wyrównanie tych widoków wymagało starannych kontroli jakości i, w przypadku wielu preparatów, ręcznego dopracowania, tak aby każde jądro na obrazie fluorescencyjnym pokrywało się z odpowiadającą strukturą na preparacie H&E. Z tych wyrównanych obrazów uzyskali ponad 11 milionów odrębnych komórek i ponad pół miliona małych fragmentów (patchy) H&E, z precyzyjnym obrysem każdego jądra.
Nauczanie komputera, czym jest każdy typ komórki
Znajomość położenia komórki to za mało; kluczowym krokiem jest ustalenie, jakiego rodzaju jest to komórka. W tym celu zespół połączył dane przestrzenne z dużymi istniejącymi katalogami profilów RNA z pojedynczych komórek. Używając metody zwanej Tangram, najpierw przenieśli prawdopodobne tożsamości komórek z tych referencyjnych atlasów na dane przestrzenne. Następnie poprawili wstępne etykiety, grupując komórki w klastry na podstawie aktywności genów i badając, które geny odróżniają poszczególne klastry. Gdy geny znacznikowe i wyniki Tangramu się zgadzały, etykiety uznawano za zaakceptowane; gdy się nie zgadzały, pierwszeństwo nadawały lokalne wzory ekspresji genów w tkance. Na koniec ujednolicono wyniki ze wszystkich preparatów do dziesięciu szerokich kategorii, takich jak nabłonkowe, naczyniowe, grupy komórek odpornościowych, fibroblasty, melanocyty oraz ogólna kategoria „inne”. Patolog wizualnie sprawdził wyniki na obrazach H&E, aby upewnić się, że etykiety mają sens biologiczny.
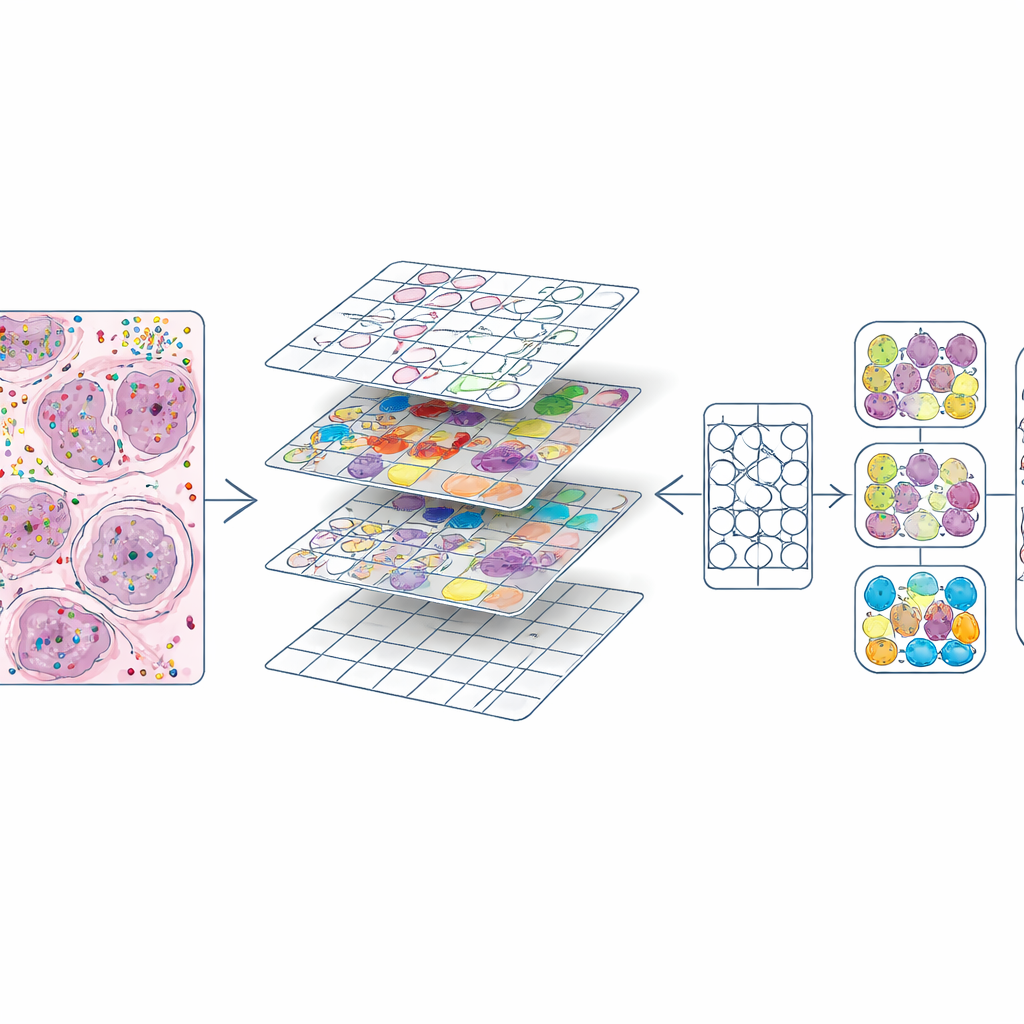
Przekształcanie bogatych map molekularnych w materiał treningowy
Gdy każda komórka miała zarówno pozycję, jak i typ, autorzy pocięli każdy preparat H&E na małe kwadraty, podobne do płytek obrazów w programie do edycji zdjęć. Dla każdej płytki wytworzyli dwa kluczowe składniki: maskę obrysowującą każde jądro oraz kod kolorystyczny wskazujący jego typ komórkowy. To dało około 587 000 płytek w wysokim powiększeniu i nieco mniejszy zestaw w niższym powiększeniu. Porównali też swoje obrysy jąder z tymi wygenerowanymi automatycznie przez istniejący model uczenia głębokiego (CellViT) i obliczyli wskaźniki zgodności, co pozwala przyszłym użytkownikom odsiewać regiony o niższej jakości. Wszystkie te informacje — obrazy, maski, zliczenia genów, etykiety komórek i wskaźniki jakości — zostały zapakowane w ustandaryzowane obiekty danych, tak aby badacze mogli łatwo eksplorować lub ponownie użyć zbiór danych.
Pokazanie, że komputery potrafią uczyć się z nowego atlasu
Aby zademonstrować możliwości STHELAR, zespół dostroił model CellViT, potężny transformer wizjonerski zaprojektowany do segmentacji i klasyfikacji komórek na obrazach H&E. Używając etykiet STHELAR jako danych referencyjnych, wytrenowali model do rozpoznawania dziewięciu szczegółowych klas komórek, a w drugim eksperymencie — pięciu szerszych grup (na przykład łącząc kilka typów komórek odpornościowych). Model po dostrojeniu utrzymał wysoką wydajność w wykrywaniu i obrysowywaniu jąder oraz osiągnął dobrą dokładność dla wizualnie wyróżniających się komórek, takich jak komórki nabłonkowe i melanocyty, podczas gdy bardziej subtelne podtypy immunologiczne pozostały wyzwaniem. Sprawdzili też swoje anotacje względem niezależnej metody etykietowania (SingleR) i alternatywnych modeli opartych na RNA, znajdując ogólnie dobrą zgodność.
Co to oznacza dla przyszłej diagnostyki raka
STHELAR to raczej atlas referencyjny niż pojedynczy algorytm: otwarta, wielkoskalowa więź między tym, co patolodzy widzą na standardowych preparatach H&E, a tym, co transkryptomika przestrzenna ujawnia o aktywności genów w każdej komórce. Dla osób spoza specjalności najważniejsze jest to, że to źródło danych ułatwia trenowanie i testowanie modeli komputerowych, które potrafią wnioskować o składzie komórkowym guzów bezpośrednio z rutynowych obrazów, bez konieczności wykonywania drogich badań molekularnych u każdego pacjenta. W miarę poprawy takich modeli mogą one pomagać lekarzom odczytywać niewidzialną molekularną „rozmowę” wewnątrz guzów z zwykłych preparatów, wspierając precyzyjniejsze diagnozy i lepiej dopasowane terapie.
Cytowanie: Giraud-Sauveur, F., Blampey, Q., Benkirane, H. et al. STHELAR, a multi-tissue dataset linking spatial transcriptomics and histology for cell type annotation. Sci Data 13, 665 (2026). https://doi.org/10.1038/s41597-026-06937-6
Słowa kluczowe: mikrośrodowisko guza, transkryptomika przestrzenna, obrazowanie histopatologiczne, anotacja typów komórek, uczenie głębokie w nowotworach