Clear Sky Science · nl
STHELAR, een multi-weefsel dataset die ruimtelijke transcriptomics en histologie koppelt voor celtype-annotatie
Waarom kijken naar kanker onder de microscoop niet genoeg is
Oncologen vertrouwen nog steeds sterk op wat ze door de microscoop zien: dunne, roze‑paarse weefselplakjes gekleurd met hematoxyline en eosine (H&E). Deze beelden onthullen vormen en patronen, maar tonen niet rechtstreeks welke genen in elke cel actief zijn. Een nieuwe bron genaamd STHELAR brengt deze twee werelden samen, door de vertrouwde aanblik van weefselplakjes te koppelen aan geavanceerde “ruimtelijke” metingen van genactiviteit. Voor lezers is dit belangrijk omdat het de deur opent naar snellere, goedkopere hulpmiddelen die op den duur de moleculaire samenstelling van tumoren mogelijk alleen uit gewone digitale beelden kunnen aflezen.
De tumor zien als een drukke buurt
Tumoren bestaan niet alleen uit kwaadaardige kankercellen; ze zijn drukke buurten vol immuuncellen, bloedvaten, steuncellen en normaal weefsel. De samenstelling en ordening van deze bewoners — de tumormicro‑omgeving — kan bepalen hoe een kanker groeit en hoe deze op behandelingen reageert. Ruimtelijke transcriptomics, een recente technologie, kan in kaart brengen welke genen in individuele cellen aanstaan terwijl hun exacte locatie in het weefsel behouden blijft. Deze experimenten zijn echter kostbaar en technisch veeleisend, en behoren nog niet tot de routinematige zorg. Daarentegen zijn hoge‑resolutie scans van H&E‑plakjes inmiddels gebruikelijk, goedkoop op te slaan en wereldwijd al in gebruik. Het centrale idee achter STHELAR is om een beperkte set ruimtelijke transcriptomics‑experimenten te gebruiken als “leraar” voor miljoenen cellen die zichtbaar zijn op standaard H&E‑beelden.
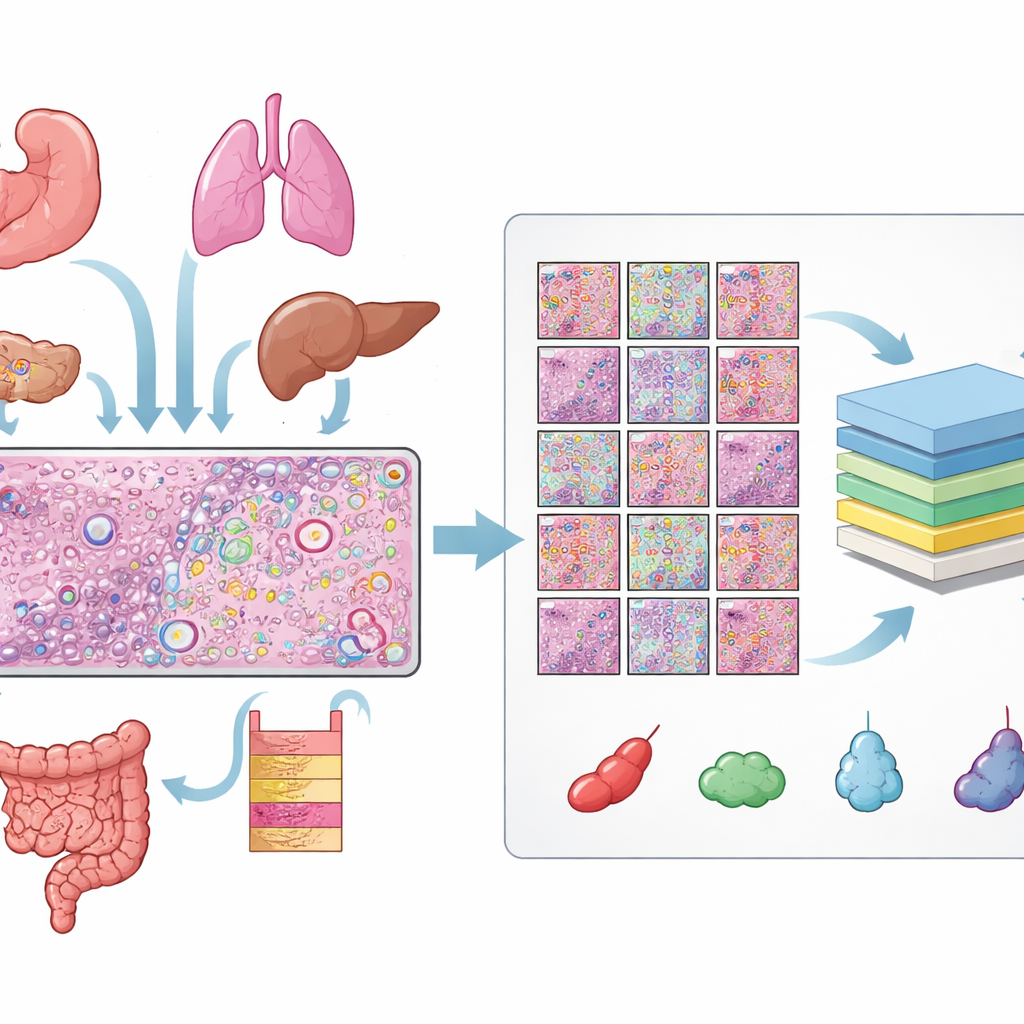
Een enorme bibliotheek van gelabelde cellen opbouwen
De auteurs verzamelden gegevens van 31 weefselsneden gemeten met het Xenium‑platform van 10x Genomics voor ruimtelijke transcriptomics, die 16 typen menselijk weefsel en 22 kankervoorbeelden en 9 niet‑kanker voorbeelden besloegen. Voor elke sectie hadden ze drie bijpassende weergaven: een H&E‑plakje, een fluorescentiebeeld dat celkernen toont, en een kaart van individuele RNA‑moleculen. Het uitlijnen van deze weergaven vergde zorgvuldige kwaliteitscontroles en, voor veel plakjes, handmatige nabewerking zodat elke kern in het fluorescentiebeeld overeenkwam met de corresponderende structuur in het H&E‑beeld. Uit deze uitgelijnde beelden verkregen ze meer dan 11 miljoen onderscheiden cellen en ruim een half miljoen kleine H&E‑patches, elk met precieze omtrekken van elke kern.
De computer leren wat elk celtype is
Weten waar elke cel zich bevindt is niet voldoende; de cruciale stap is bepalen wat voor type cel het is. Daartoe combineerde het team ruimtelijke transcriptomics met grote bestaande catalogi van single‑cell RNA‑profielen. Met een methode genaamd Tangram droegen ze eerst waarschijnlijke celidentiteiten uit deze referentieatlassen over op de ruimtelijke data. Ze verbeterden deze voorlopige labels vervolgens door cellen te groeperen in clusters op basis van hun genactiviteit en te onderzoeken welke genen elk cluster onderscheidden. Wanneer markergenen en Tangram overeenstemden, werden de labels geaccepteerd; bij onenigheid kregen lokale genpatronen in het weefsel voorrang. Ten slotte harmoniseerden ze de resultaten over alle plakjes tot tien brede categorieën zoals epitheliaal, bloedvat, immuuncelgroepen, fibroblasten, melanocyten en een verzamelcategorie “overig”. Een patholoog controleerde visueel de resultaten op de H&E‑beelden om te verzekeren dat de labels biologisch zinvol waren.
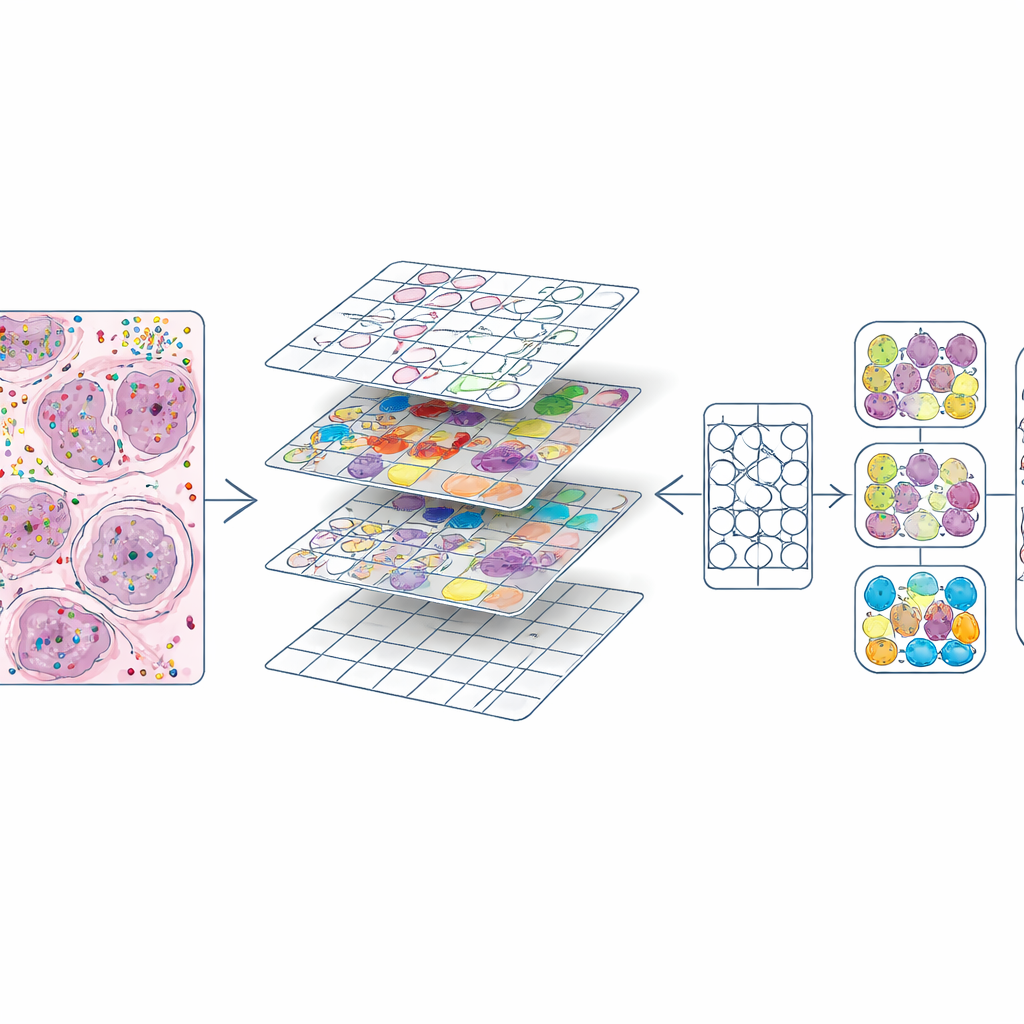
Rijke moleculaire kaarten omzetten in trainingsmateriaal
Zodra elke cel zowel een positie als een type had, knipten de auteurs elk H&E‑plakje in kleine vierkantjes, vergelijkbaar met beeldtegels in een fotobewerkingsprogramma. Voor elke tegel produceerden ze twee cruciale ingrediënten: een maskering die elke kern omlijnt en een kleurcode die het celtype aangeeft. Dit leverde ongeveer 587.000 tegels op bij hoge vergroting en een iets kleinere set bij lagere vergroting. Ze vergeleken ook hun kernomtrekken met die automatisch gegenereerd door een bestaand deep‑learningmodel (CellViT) en berekenden overeenstemmingsscores, zodat toekomstige gebruikers laagkwalitatieve regio’s kunnen filteren. Al deze informatie — beelden, maskers, genaantallen, cellabels en kwaliteitscores — is gebundeld in gestandaardiseerde data‑objecten zodat onderzoekers de dataset eenvoudig kunnen verkennen of hergebruiken.
Aantonen dat computers van het nieuwe atlas kunnen leren
Om te laten zien wat STHELAR mogelijk maakt, verfijnde het team het CellViT‑model, een krachtige vision transformer ontworpen voor het segmenteren en classificeren van cellen in H&E‑beelden. Met de labels van STHELAR als grondwaarheid trainden ze het model om negen gedetailleerde celklassen te herkennen en, in een tweede experiment, vijf bredere groepen (bijvoorbeeld door meerdere immuunceltypen samen te voegen). Het fijn afgestelde model behield sterke prestaties bij het detecteren en omlijnen van kernen en behaalde goede nauwkeurigheid voor visueel onderscheidende cellen zoals epitheliale cellen en melanocyten, terwijl subtielere immuunsubtypen uitdagend bleven. Ze controleerden hun annotaties ook met een onafhankelijke labelmethode (SingleR) en alternatieve RNA‑gebaseerde modellen, en vonden over het algemeen goede overeenstemming.
Wat dit betekent voor toekomstige kankerdiagnostiek
STHELAR is minder een enkel algoritme dan een referentie‑atlas: een open, grootschalige koppeling tussen wat pathologen zien op standaard H&E‑plakjes en wat ruimtelijke transcriptomics onthult over genactiviteit in elke cel. Voor leken is de belangrijkste conclusie dat deze bron het veel eenvoudiger maakt om computermodellen te trainen en te testen die rechtstreeks uit routinematige beelden de cellulaire samenstelling van tumoren kunnen afleiden, zonder voor elke patiënt dure moleculaire testen te hoeven uitvoeren. Naarmate zulke modellen verbeteren, zouden ze artsen kunnen helpen de onzichtbare moleculaire “conversatie” binnen tumoren uit gewone plakjes af te lezen, en daarmee preciezere diagnoses en beter afgestemde behandelingen te ondersteunen.
Bronvermelding: Giraud-Sauveur, F., Blampey, Q., Benkirane, H. et al. STHELAR, a multi-tissue dataset linking spatial transcriptomics and histology for cell type annotation. Sci Data 13, 665 (2026). https://doi.org/10.1038/s41597-026-06937-6
Trefwoorden: tumormicro-omgeving, ruimtelijke transcriptomics, histopathologische beeldvorming, celtype-annotatie, deep learning bij kanker