Clear Sky Science · ja
STHELAR:空間トランスクリプトミクスと組織学を結びつけた細胞タイプ注釈のためのマルチ組織データセット
顕微鏡でがんを観るだけでは不十分な理由
がん医は依然として顕微鏡像――ヘマトキシリン・エオシン(H&E)で染色された薄切り組織のピンクと紫の像――に大きく依存しています。これらの画像は形やパターンを明らかにしますが、各細胞内部でどの遺伝子が活性化しているかを直接示すことはできません。STHELARと呼ばれる新しいリソースは、この二つの世界を結びつけ、組織スライドのなじみ深い視覚情報と遺伝子活性の最先端の“空間”測定を紐付けます。読者にとって重要なのは、この作業がいつか日常的なデジタル画像だけで腫瘍の分子構成を読み取れる、より速く安価なツールの可能性を開く点です。
腫瘍を混み合った近隣として捉える
腫瘍は暴走したがん細胞だけでなく、免疫細胞、血管、支持細胞、正常組織で満たされた混み合った近隣のような存在です。これらの構成要素の混合や配置――腫瘍微小環境――は、がんの成長や治療反応の仕方に影響を与えます。空間トランスクリプトミクスは、細胞ごとにどの遺伝子がオンになっているかを組織内の正確な位置を保持したままマッピングできる新しい技術です。しかし、この種の実験は高コストで技術的に要求が高く、まだ日常診療の一部にはなっていません。一方で、H&Eスライドの高解像度スキャンは現在広く行われており、保存コストも低く、世界中で既に使用されています。STHELARの中心的なアイデアは、限られた数の空間トランスクリプトミクス実験を「教師」として用い、標準的なH&E画像に写る何百万もの細胞に知識を伝えることです。
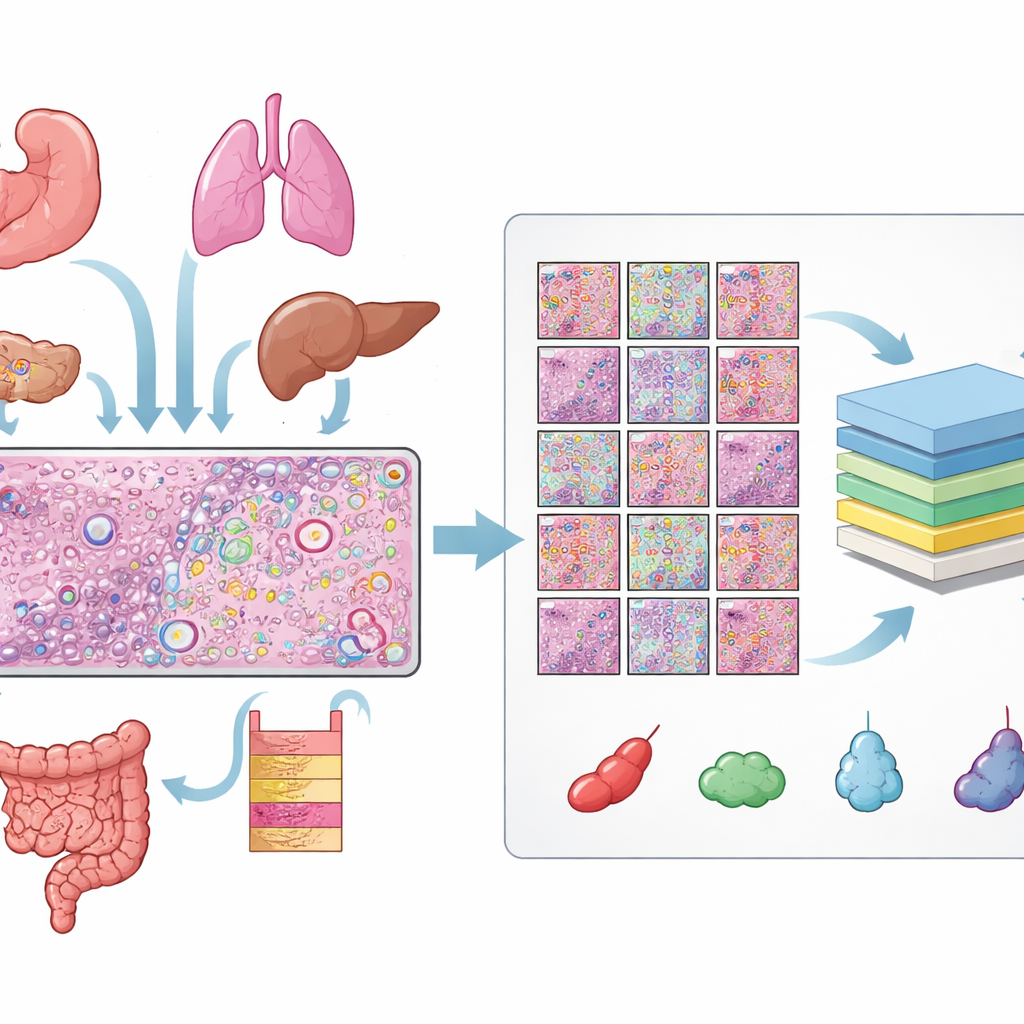
ラベル付き細胞の巨大なライブラリを構築する
著者らは、10x GenomicsのXenium空間トランスクリプトミクスプラットフォームで測定された31枚の組織切片のデータを収集し、16種類のヒト組織と22件のがんサンプル、9件の非がんサンプルを網羅しました。各切片について、H&Eスライド、細胞核を示す蛍光画像、個々のRNA分子のマップという三つの対応するビューを持っていました。これらのビューを整列させるには入念な品質チェックが必要で、多くのスライドでは蛍光画像の各核がH&Eスライドの対応構造と一致するよう手動で微調整が行われました。これらの整列された画像から、1100万を超える個別の細胞と50万を超える小さなH&Eパッチを取得し、それぞれの核の輪郭を正確に取り出しました。
各細胞タイプをコンピュータに教える
各細胞の位置が分かっても、それだけでは不十分で、重要なのはその細胞がどの種類かを判定することです。そのために、研究チームは空間トランスクリプトミクスと既存の大規模な単一細胞RNAプロファイルのカタログを組み合わせました。Tangramと呼ばれる手法を用いて、まずこれらの参照アトラスから空間データへと見込みのある細胞同定を転写しました。次に、遺伝子発現に基づいて細胞をクラスタリングし、各クラスタを特徴づける遺伝子を調べることで、初期ラベルを改良しました。マーカー遺伝子とTangramが一致する場合はラベルを受け入れ、不一致の場合は組織内の局所的な遺伝子パターンが優先されました。最後に、結果を全スライドで調和させ、上皮、血管、免疫細胞群、線維芽細胞、メラノサイト、およびその他の「その他」グループなど10の大まかなカテゴリにまとめました。病理医がH&E画像上で結果を目視検査し、ラベルが生物学的に妥当であることを確認しました。
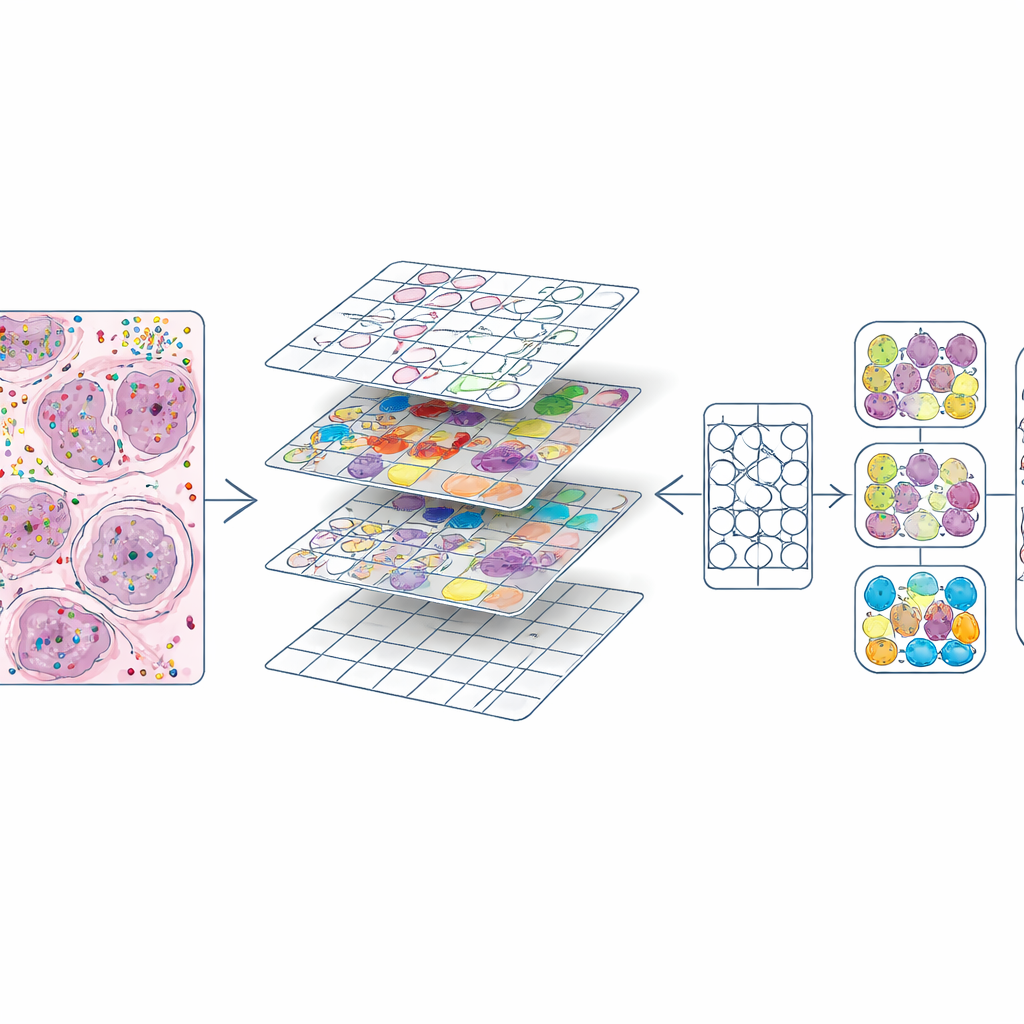
豊富な分子マップを学習素材に変える
すべての細胞が位置とタイプを持つようになると、著者らは各H&Eスライドを写真編集ソフトの画像タイルのような小さな正方形に切り分けました。各タイルについて、二つの重要な要素を作成しました:すべての核を囲むマスクと、その核の細胞タイプを示す色コードです。これにより、高倍率で約587,000枚のタイルと、やや低倍率のセットが作られました。また、核輪郭を既存の自動深層学習モデル(CellViT)が生成したものと比較し、一致度スコアを算出することで、将来の利用者が低品質領域を除外できるようにしました。画像、マスク、遺伝子カウント、細胞ラベル、品質スコアといったすべての情報は標準化されたデータオブジェクトにまとめられ、研究者がデータセットを簡単に探索・再利用できるようにしています。
コンピュータが新しいアトラスから学べることを示す
STHELARが可能にすることを実証するため、チームはCellViTモデルをファインチューニングしました。CellViTはH&E画像での細胞のセグメンテーションと分類に設計された強力なビジョントランスフォーマーです。STHELARのラベルを正解ラベルとして用い、モデルに九つの詳細な細胞クラスと、別の実験では五つのより大まかなグループ(例えば複数の免疫細胞タイプをまとめたもの)を認識させるよう訓練しました。ファインチューニング後のモデルは核の検出と輪郭抽出で高い性能を維持し、上皮細胞やメラノサイトのような視覚的に特徴的な細胞では良好な精度を達成しましたが、より微妙な免疫サブタイプの識別は依然として難しいままでした。彼らはまた、独立した注釈手法(SingleR)やRNAベースの代替モデルと照合し、概ね良好な一致を確認しました。
将来のがん診断にとっての意義
STHELARは単一のアルゴリズムというよりも参照アトラスです:病理医が標準的なH&Eスライドで見る像と、空間トランスクリプトミクスが各細胞の遺伝子活性について明らかにする情報との間に開かれた大規模な連結を提供します。非専門家への要点は、このリソースが日常的な画像だけから腫瘍の細胞構成を推定するコンピュータモデルの訓練と評価を格段に容易にするということです。すべての患者に高価な分子アッセイを実施する必要がなくなれば、こうしたモデルが進歩するにつれて、病理医は通常のスライドから腫瘍内部の見えない分子的“会話”を読み取り、より精密な診断や個別化された治療の支援が可能になるでしょう。
引用: Giraud-Sauveur, F., Blampey, Q., Benkirane, H. et al. STHELAR, a multi-tissue dataset linking spatial transcriptomics and histology for cell type annotation. Sci Data 13, 665 (2026). https://doi.org/10.1038/s41597-026-06937-6
キーワード: 腫瘍微小環境, 空間トランスクリプトミクス, 組織病理学イメージング, 細胞タイプ注釈, がんにおけるディープラーニング