Clear Sky Science · nl
Hoogwaardige metagenoomassemblage van nanopore-lezingen met nanoMDBG
Verborgen leven lezen in een lepeltje aarde
Elke snuf aarde of druppel darmvloeistof bulkt van duizenden microbiele soorten, waarvan de meesten niet in het laboratorium gekweekt kunnen worden. Om te begrijpen wat ze zijn en wat ze doen, lezen wetenschappers hun DNA rechtstreeks uit het milieu — een vakgebied dat bekendstaat als metagenomica. Dit artikel introduceert nanoMDBG, een nieuwe computationele methode die ruwe signalen van een draagbare DNA-sequencer omzet in hoogwaardige voorlopige genomen, waardoor het mogelijk wordt om complexe microbiële werelden sneller, goedkoper en veel gedetailleerder in kaart te brengen dan voorheen.
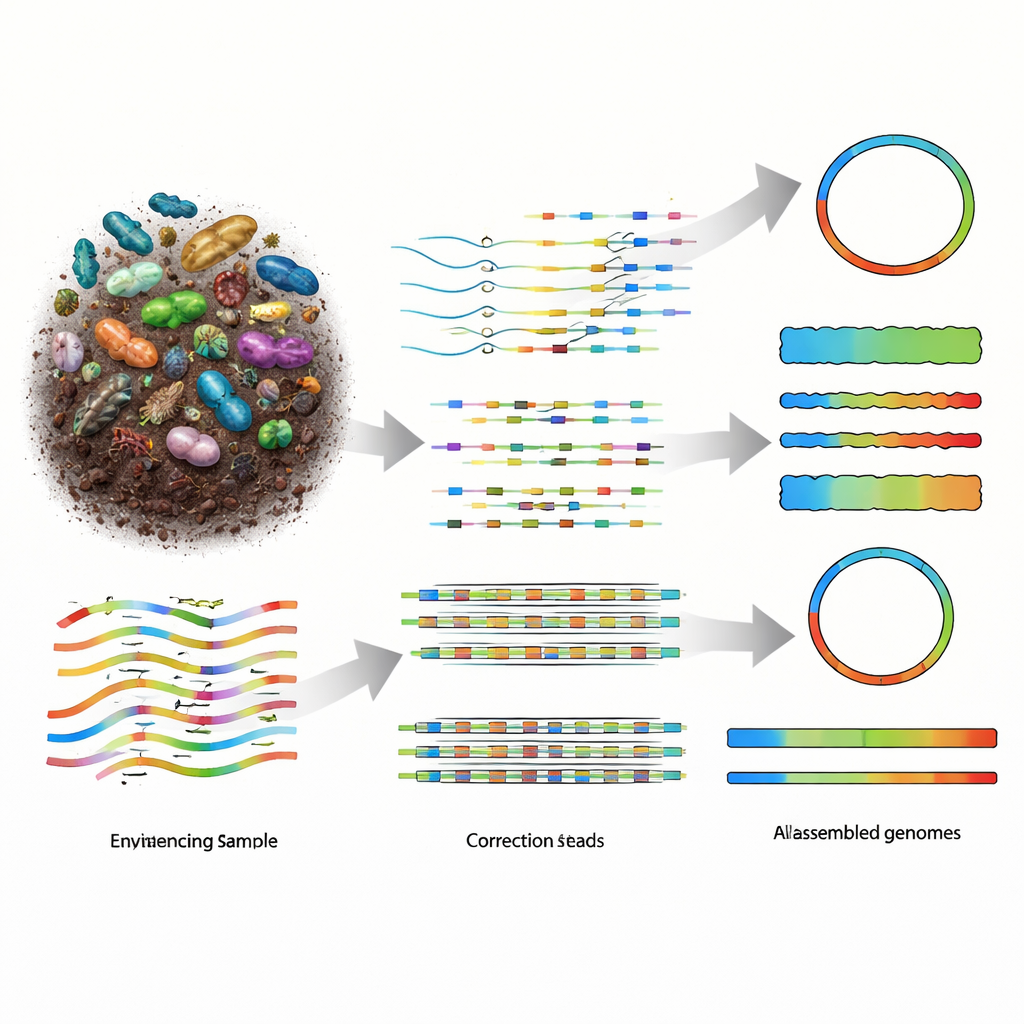
Waarom het herbouwen van genomen uit de natuur zo moeilijk is
Metagenomica werkt door al het DNA in een monster in stukken te breken, die fragmenten te sequencen en vervolgens software te gebruiken om ze weer samen te voegen tot de genomen van de aanwezige organismen. Oudere short-read-technologieën leverden veel kleine stukjes, maar de resulterende puzzels waren sterk versnipperd, vooral in diverse gemeenschappen zoals bodem. Long-read sequencingplatforms, waaronder PacBio HiFi en Oxford Nanopore Technologies (ONT), produceren veel langere DNA-fragmenten, wat reconstructie eenvoudiger zou moeten maken. PacBio-lezingen zijn extreem nauwkeurig maar duurder, terwijl ONT-apparaten betaalbaarder en zeer draagbaar zijn, maar historisch gezien ruisvollere data opleverden. Naarmate ONT-chemie verbeterde tot ongeveer één fout per honderd DNA-basen, ontstond de behoefte aan assemblers die dit nieuwe compromis tussen lengte, nauwkeurigheid en kosten volledig konden benutten.
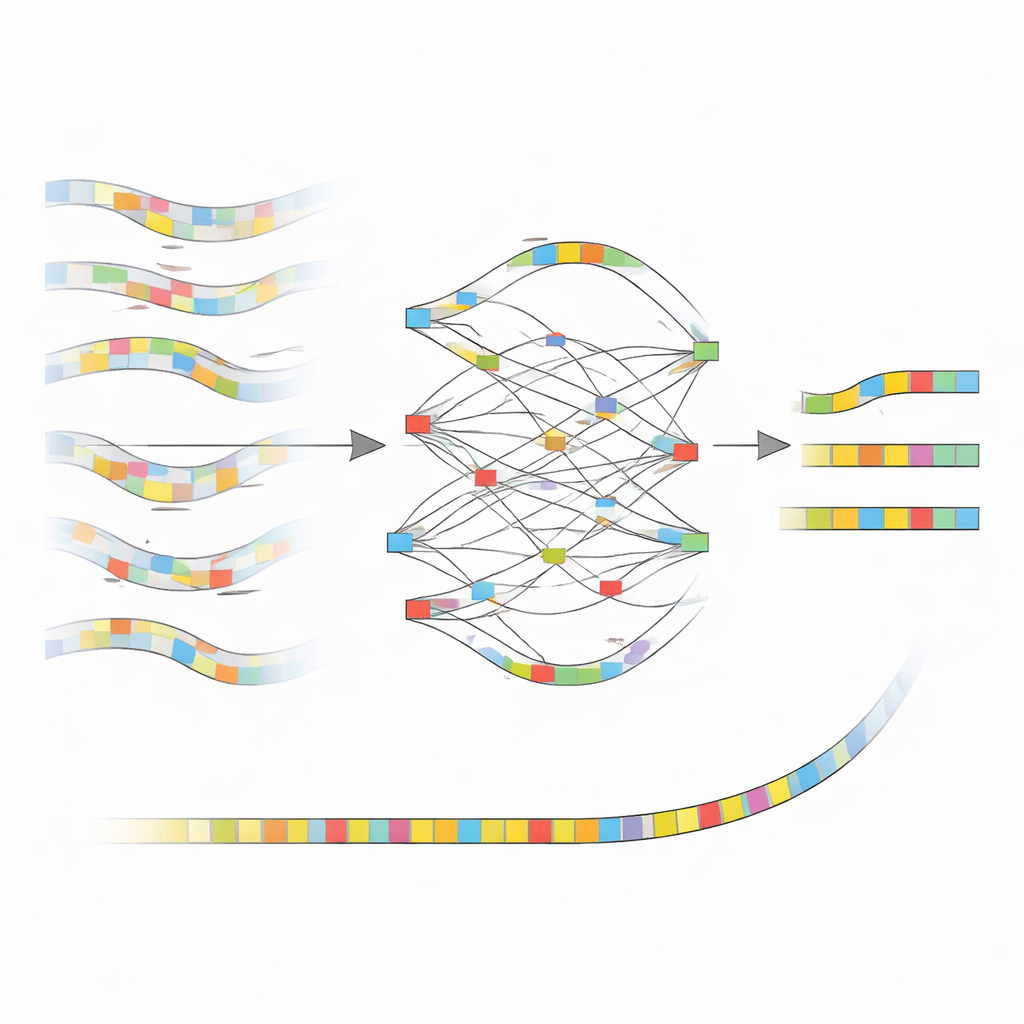
Van luidruchtige signalen naar schone bouwstenen
Het kernidee achter nanoMDBG is te werken met een compact schets van elk DNA-fragment in plaats van met elke individuele base. De methode selecteert een spars set korte DNA-patronen, zogenaamde minimizers, uit elke read en behandelt de geordende lijst van deze patronen als een lichtgewicht vingerafdruk. Eerdere software van dezelfde groep, metaMDBG, gebruikte deze minimizer-vingerafdrukken al om zeer nauwkeurige PacBio-lezingen efficiënt te assembleren. De resterende fouten in ONT-data braken echter vaak deze vingerafdrukken, wat leidde tot gaten en foutieve samenvoegingen. NanoMDBG pakt dit aan door eerst ONT-lezingen te corrigeren in deze gereduceerde “minimizer-ruimte.” Voor elke doelread werft het algoritme snel een handvol van de meest vergelijkbare reads met zeer spaarzame vingerafdrukken, en herbekijkt ze vervolgens met dichtere vingerafdrukken om foutieve overeenkomsten met ongerelateerde soorten uit te sluiten.
Hoe de nieuwe methode het beeld opschoont
Wanneer nanoMDBG een betrouwbare groep vergelijkbare vingerafdrukken heeft verzameld, legt het deze over elkaar om een eenvoudige graaf te bouwen die bijhoudt waar de patronen overeenkomen, afwijken of inserties en deleties tonen. In plaats van naar elke base te kijken, werkt het alleen met deze geselecteerde patronen, wat de rekencapaciteit sterk vermindert. Het sterkst ondersteunde pad door deze graaf wordt de consensusvingerafdruk voor de read en strijkt zo veel van de oorspronkelijke sequencerfouten glad. Alle gecorrigeerde vingerafdrukken worden vervolgens in de bestaande metaMDBG-assembler gevoerd, die ze aan elkaar rijgt tot langere DNA-stukken en ze uiteindelijk terugzet naar volledige sequenties, gevolgd door een polijststap om resterende kleine fouten te verfijnen.
nanoMDBG aan de tand voelen in echte microbiomen
De onderzoekers evalueerden nanoMDBG op meerdere testcases: een gedefinieerde mix van 21 bekende microben, een menselijk darmmonster, een referentiemix van menselijke fecale stof en een zeer complexe landbouwbodem. Ze vergeleken de prestatie met toonaangevende long-read-assemblers, met name metaFlye en de eerdere metaMDBG, en keken naar hoeveel bijna-volledige genomen — bekend als metagenoom-geassembleerde genomen, of MAGs — ze konden terugwinnen en hoeveel daarvan als enkele continue stukken werden gevangen. In alle drie de echte gemeenschappen produceerde nanoMDBG aanzienlijk meer hoogwaardige MAGs dan concurrerende tools, en veel meer volledige, single-contig genomen. In de 400-miljard-basen bodemdataset, bijvoorbeeld, herstelde het 201 meer bijna-volledige genomen dan metaMDBG en 144 meer dan metaFlye, terwijl het slechts een fractie van het geheugen gebruikte en in ongeveer zes dagen klaar was in plaats van bijna een maand.
Kostbare nauwkeurigheid evenaren met goedkopere reads
Aangezien ONT- en PacBio-sequencers op dezelfde monsters en met vergelijkbare dieptes werden gebruikt, kon het team de technologieën direct vergelijken. Voor darm- en gestandaardiseerde fecale gemeenschappen had PacBio HiFi nog steeds een voorsprong in het totale aantal topkwaliteitgenomen, vooral bij hogere sequentiedieptes. Toch kwam ONT-data geassembleerd met nanoMDBG verrassend dichtbij en overtrof HiFi zelfs onder sommige laagdieptevoorwaarden. Voor het bodemmonster, waar duizenden soorten samenleven, waren de aantallen bijna-volledige genomen van ONT en HiFi bij hoge diepte in wezen vergelijkbaar, hoewel HiFi vaker volledig continue single-contig genomen bereikte. Gedetailleerde foutanalyses toonden aan dat nanoMDBG misassemblages en gebieden met ontbrekende dekking relatief laag hield en meer volledige eiwitten coderende genen behield dan concurrerende ONT-assemblers, vooral in de uitdagende bodemdataset.
Wat dit betekent voor het verkennen van onzichtbare ecosystemen
Voor niet-specialisten is de kernboodschap dat goedkope, veldinzetbare DNA-sequencers nu microbiële genomen uit complexe omgevingen kunnen reconstrueren met een kwaliteit die in de buurt komt van grotere, duurdere instrumenten. NanoMDBG bereikt dit door de data slim te vereenvoudigen tot herbruikbare patronen, fouten in die compacte representatie te corrigeren en vervolgens genomen te assembleren uit de opgeschoonde patronen met hoge efficiëntie. Hierdoor wordt het haalbaar om veel monsters te onderzoeken, microbiële stammen te volgen tussen mensen of locaties en de enorme, nog grotendeels onontdekte diversiteit van leven in bodems en andere habitats te verkennen, alles zonder supercomputer-schaal middelen. Naarmate algoritmen blijven verbeteren, zullen dergelijke tools ons steeds dichter brengen bij routinematige, genoomniveau-kaarten van volledige microbiële gemeenschappen.
Bronvermelding: Benoit, G., James, R., Raguideau, S. et al. High-quality metagenome assembly from nanopore reads with nanoMDBG. Nat Commun 17, 3556 (2026). https://doi.org/10.1038/s41467-026-69760-y
Trefwoorden: metagenomica, nanopore-sequencing, genoomassemblage, microbioom, bio-informatica