Clear Sky Science · fr
Combiner xQTL et études d’association pangénomique issues de populations diverses améliore la découverte de gènes « druggables »
Pourquoi les gènes comptent pour les médicaments de demain
La génétique moderne a mis au jour des milliers de marqueurs d’ADN liés à des maladies courantes, mais transformer ces indices en cibles médicamenteuses concrètes a été frustrantement lent. Cette étude s’attaque à un goulot d’étranglement central : nos méthodes habituelles d’analyse des grandes études génétiques ratent souvent les gènes sur lesquels les médicaments peuvent réellement agir. En repensant la manière d’analyser les données génétiques à travers des populations diverses et des niveaux biologiques multiples, les auteurs visent à dévoiler des vulnérabilités cachées mais « druggables » dans des maladies comme la maladie d’Alzheimer, la dépression, la schizophrénie et le diabète de type 2.
Des signaux d’ADN dispersés aux gènes entiers
La plupart des études d’association pangénomique (GWAS) examinent des millions de variations d’ADN une par une pour déterminer si chacune est liée à une maladie. Les chercheurs supposent en général que la variation la plus fortement associée à proximité d’un gène indique ce gène. Mais ce raccourci est souvent trompeur : seule une petite fraction de ces variants « lead » cause réellement la maladie, et ils peuvent influencer des gènes distants. De ce fait, les corrections statistiques strictes appliquées à des millions de tests diluent le signal, rendant difficile la découverte des vrais gènes impliqués dans la maladie, notamment ceux que des traitements existants ou potentiels pourraient cibler.
Un nouvel ensemble d’outils pour lire la carte génétique
Les auteurs présentent une famille de tests « basés sur les gènes », menée par une méthode appelée GenT. Plutôt que d’évaluer les variations d’ADN isolément, GenT groupe toutes les variantes pertinentes autour de chaque gène et les teste conjointement. De manière cruciale, l’équipe a développé la mathématique sous-jacente pour savoir précisément comment GenT doit se comporter en l’absence de signal réel, évitant ainsi les fausses alertes qui peuvent affecter des approches antérieures. Des extensions de ce cadre—MuGenT pour les données multi-ancestrales ou multi-traits, et xGenT pour intégrer des lectures moléculaires comme l’expression génique ou les niveaux protéiques—permettent de combiner des informations entre populations et niveaux biologiques tout en travaillant à partir de statistiques sommaires largement disponibles.
Découvrir des cibles médicamenteuses cachées dans le cerveau et le corps
En appliquant GenT à de grandes études génétiques sur la maladie d’Alzheimer, la sclérose latérale amyotrophique, la dépression majeure et la schizophrénie, les auteurs ont analysé plus de 18 000 gènes. Ils ont mis au jour 415 gènes dont les produits protéiques peuvent être ciblés par des composés existants ou expérimentaux, dont beaucoup avaient été manqués par les méthodes GWAS standard. Des dizaines de ces gènes « druggables » se trouvent dans des régions du génome qui ne montraient aucun signal fort au niveau d’un variant unique, ce qui suggère que le risque est réparti sur de nombreux effets modestes qui ne deviennent visibles qu’au niveau du gène. Parmi les exemples notables figurent SYK pour la maladie d’Alzheimer et THRB pour la schizophrénie, tous deux soutenus par des travaux biologiques antérieurs mais auparavant restés sous le radar des analyses conventionnelles.
La puissance de la diversité et des couches moléculaires
MuGenT étend cette stratégie en combinant des données génétiques de personnes d’ascendances européenne, africaine, est-asiatique, sud-asiatique et hispanique pour le diabète de type 2. Parce que de nombreux variants de risque sont partagés mais varient en fréquence et en intensité selon les groupes, les regrouper au niveau du gène augmente fortement la puissance statistique. MuGenT a identifié 269 gènes associés au diabète sans aucun variant d’ADN significatif individuellement, dont 45 codent des protéines « druggables » dans des régions jusque-là insoupçonnées. Pour relier les gènes à la biologie réelle, la méthode xGenT superpose la génétique de la maladie aux mesures de l’effet des variants sur l’activité génique et l’abondance protéique dans les tissus cérébraux. Pour la maladie d’Alzheimer, xGenT a mis en lumière 26 gènes « druggables » en dehors des régions de risque connues, dont NTRK1 et RIPK2, et a indiqué des régions cérébrales et des types cellulaires spécifiques où ils sont actifs.
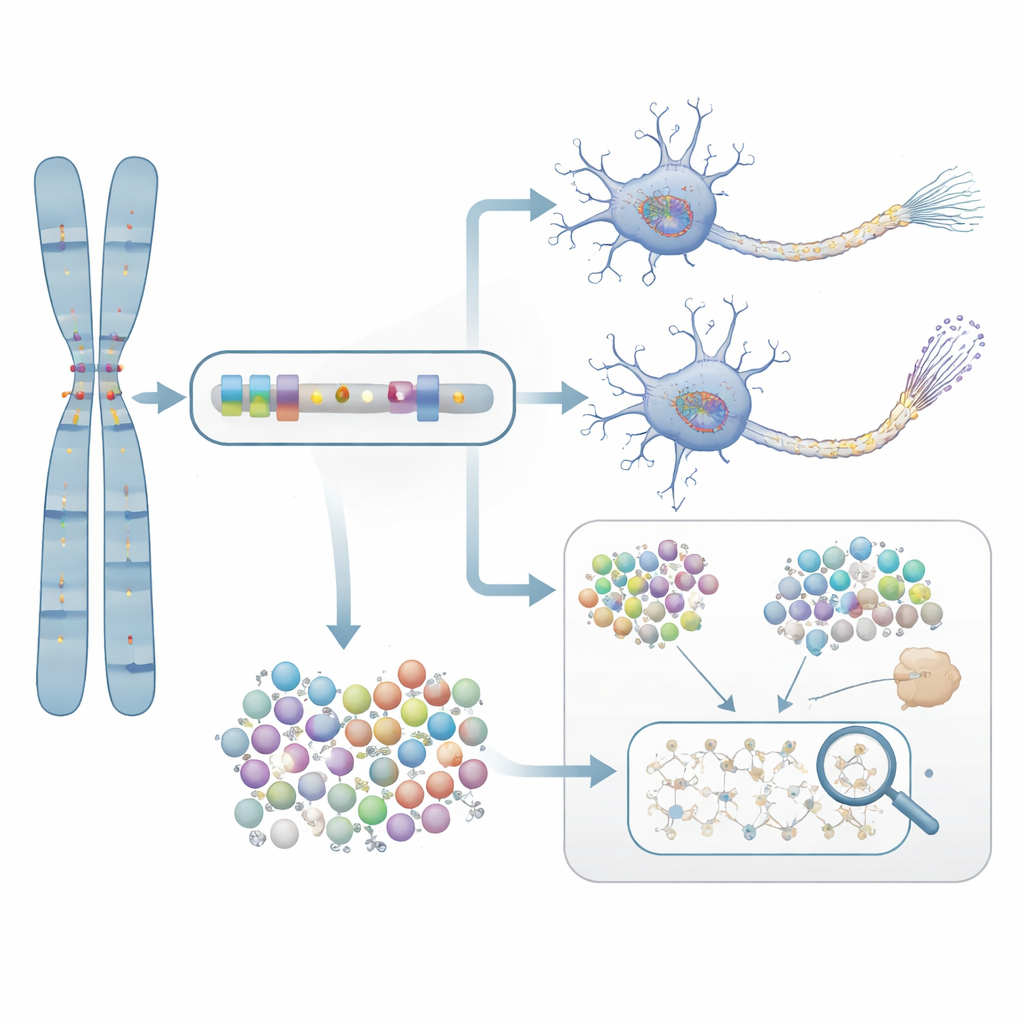
De la prédiction à la preuve expérimentale
Pour vérifier si ces gènes identifiés statistiquement ont réellement un rôle dans la maladie, les chercheurs se sont concentrés sur NTRK1, un gène impliqué dans la survie des neurones. Ils ont traité des neurones issus des cellules de patients atteints d’Alzheimer avec un composé sélectif bloquant NTRK1. Dans ces neurones cultivés, l’inhibition de NTRK1 a réduit des marques chimiques anormales sur la protéine tau—des modifications étroitement liées aux amas protéiques observés dans les cerveaux d’Alzheimer. Cette expérience fournit un pont mécaniste entre les statistiques basées sur les gènes et un processus biologique qui, en principe, peut être ciblé par des médicaments.
Ce que cela signifie pour les traitements futurs
Dans l’ensemble, ce travail montre que passer de marqueurs d’ADN isolés à des gènes entiers, tout en s’appuyant sur des données de populations diverses et sur plusieurs couches moléculaires, peut révéler beaucoup plus de cibles médicamenteuses plausibles pour les maladies complexes. Les auteurs soutiennent que de nombreux gènes réellement importants influencent la maladie via des réseaux d’effets modestes et distribués, mal captés par les balayages GWAS traditionnels. Leur cadre GenT, ainsi que ses extensions multi-ancestrales et moléculaires, offre une manière statistiquement rigoureuse de dévoiler ces signaux cachés et de prioriser des gènes pour des tests expérimentaux approfondis. Bien que des études supplémentaires en laboratoire et cliniques soient nécessaires avant qu’un traitement n’atteigne les patients, cette approche élargit significativement les points de départ génétiques pour la découverte de médicaments dans des affections qui ont urgemment besoin de meilleures thérapies.
Citation: Lorincz-Comi, N., Song, W., Chen, X. et al. Combining xQTL and genome-wide association studies from diverse populations improves druggable gene discovery. Nat Commun 17, 2801 (2026). https://doi.org/10.1038/s41467-026-69236-z
Mots-clés: association basée sur les gènes, maladie d’Alzheimer, diabète de type 2, cibles médicamenteuses, génétique multi-ancestrale