Clear Sky Science · zh
基于均相成像的高容错数字免疫检测
为什么微小颗粒和智能相机很重要
当今许多医学检测要么需要配备熟练人员的完整实验室,要么在一条试纸上提供快速但粗略的结果。本文提出了一种兼顾两者优点的方法:使用简单硬件和一滴血样,借助精巧的图像分析实现实验室级别的准确性。通过观察金纳米颗粒在血滴中的行为并让机器学习软件解释这些图像,作者展示了通向既易用又难以被误导的家庭与门诊检测的路径。
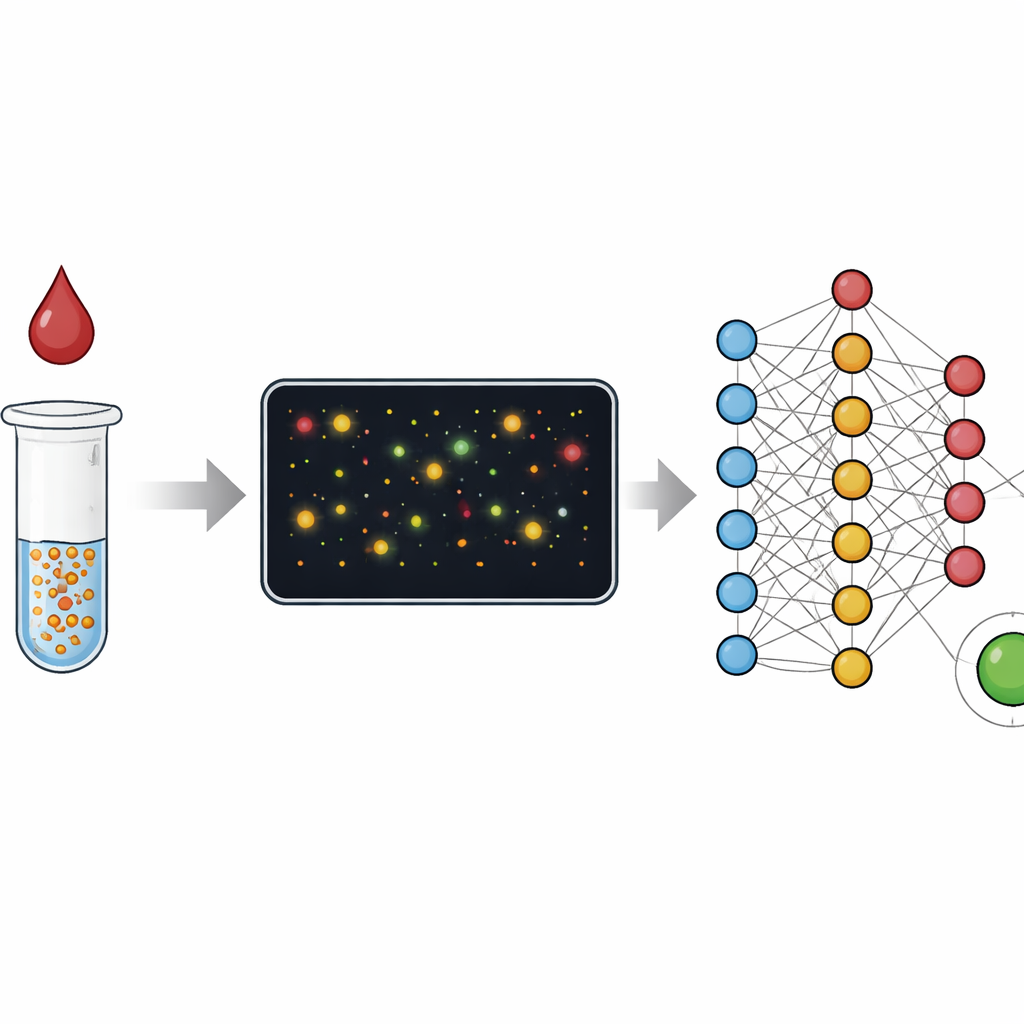
从颜色变化到颗粒计数
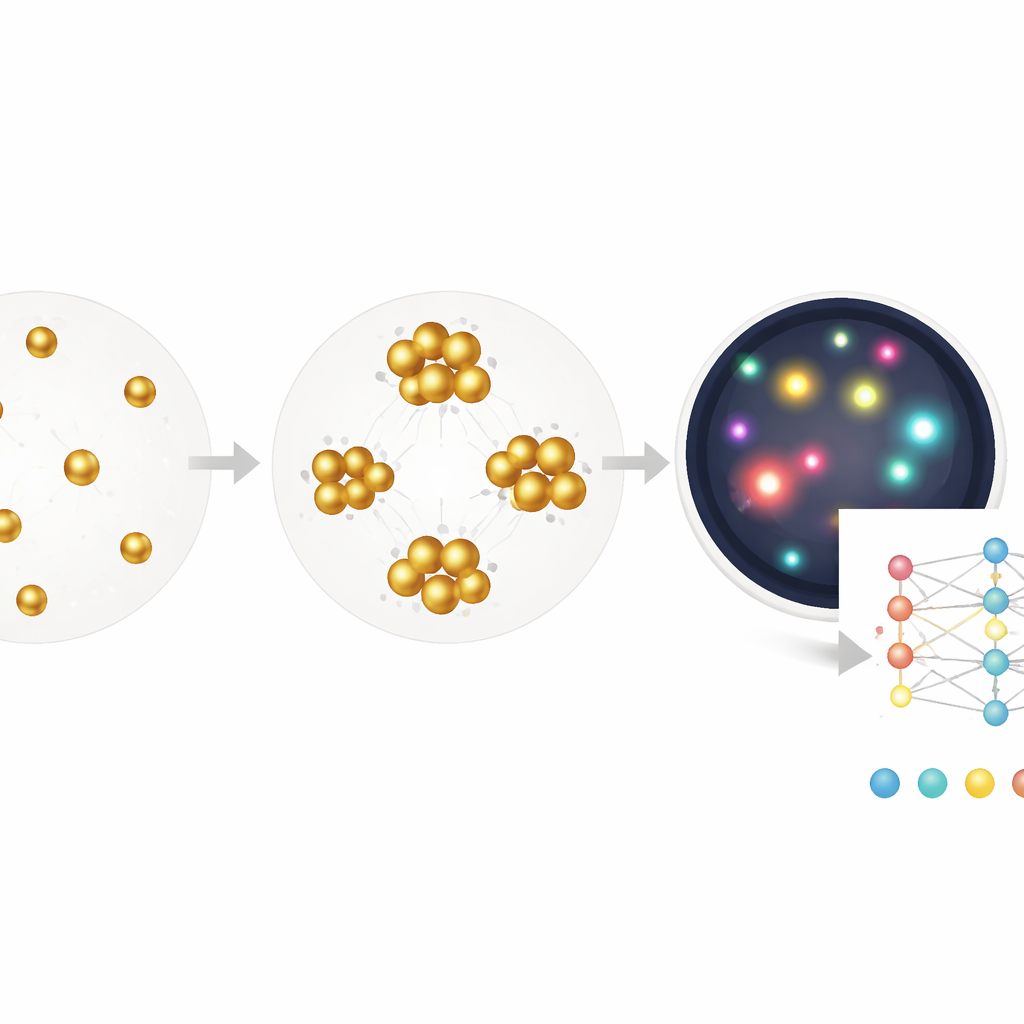
传统血液检测如 ELISA 是从反应孔中数以百万计分子的平均色变读出结果,类似于通过整体噪声来判断人群。快速试纸或侧向流动测定基于类似思路,以速度和简便换取准确性。本研究则聚焦于单个金纳米颗粒:当它们在样本中遇到目标分子(例如与炎症相关的 C‑反应蛋白或针对导致 COVID‑19 的病毒的抗体)时会发生聚集。研究者不是单纯测量溶液的整体颜色,而是用暗场显微镜拍摄充满这些颗粒与簇的微小场景,然后逐一分析每个颗粒。由“模拟”颜色到“数字”计数的转换极大拓宽了检测可测浓度范围,并更容易发现出现问题的情况。
在真实样本的混杂背景中看清目标
真实血样很混乱:含有红细胞、碎片、气泡以及其他会干扰简单图像处理规则的可视杂物。团队首先证明,即使采用调优后的传统算法,也能直接在全血中(无需离心去除细胞)提取出簇大小与 C‑反应蛋白水平之间近似线性的干净关系。为更系统地处理伪影,他们接着训练了一个分割模型,将图像中的每个像素标注为纳米颗粒、细胞、灰尘或背景。过滤掉除真实颗粒外的所有内容后,他们再次使用簇大小作为读出。采用这种混合方法,在故意引入易错采集条件的情况下,他们仍能在储存的患者血清中以 96% 的特异性和 90% 的敏感性正确分类 COVID‑19 抗体状态。
让计算机发现关键线索
虽然分割方法有帮助,但它仍依赖人为选择要测量的特征——例如簇需要多大或多亮才算有效。作者进一步训练了一个深度神经网络,使其直接从原始图像预测抗病毒抗体浓度,训练时仅以已知浓度作为标签,不使用像素级注释。这个端到端模型基于标准 ResNet 架构,有效地学习到自身的线索组合:颜色的细微变化、密度、簇形状、空隙等。当在新样本上测试时,它能在超过三点五个数量级的范围内估计抗体水平,检测下限接近临床 ELISA 试剂盒,同时仅需 30 分钟的一次孵育并适用于微量样本。
设计可像显微镜一样调节的检测
除了展示可行的检测,研究还探讨了这种数字颗粒计数在理论上能走多远。通过数学和模拟框架,作者表明此类检测的灵敏度并非固定不变;它取决于所用颗粒数量、颗粒的一致性以及通过亮度分辨单颗粒与成对颗粒的能力。通过调整这些“旋钮”——尤其是颗粒数量及其质量——他们认为理论上可以达到极低的可检测浓度,其主要限制来自基本的计数统计。机器学习提供了额外提升,可增加可自信使用的颗粒数量并改善真结合事件与随机噪声之间的辨别。
迈向更智能、更宽容的血液检测
总体而言,这项工作表明将简单光学与先进图像分析配对,能够在容忍真实世界使用变异性的前提下,提供媲美金标准实验室方法的检测。与其开发愈加精密的硬件,这种方法更依赖图像中已经存在的丰富信息,并让软件从杂乱中分辨信号。对患者和卫生系统来说,这可能意味着针对常见血液标志物和传染病的更可靠的现场和自我检测,而无需复杂仪器或专业操作人员。
引用: McAffee, D.B., Hu, Q., Arnob, A. et al. Homogeneous image-based digital immunoassays with high error tolerance. npj Imaging 4, 30 (2026). https://doi.org/10.1038/s44303-026-00164-9
关键词: 数字免疫检测, 纳米颗粒成像, 机器学习诊断, 现场检测, SARS-CoV-2 抗体