Clear Sky Science · nl
Homogene beeldgebaseerde digitale immunoassays met hoge fouttolerantie
Waarom kleine deeltjes en slimme camera’s ertoe doen
Veel medische tests van vandaag vereisen ofwel een volledig laboratorium met gespecialiseerd personeel, of bieden snelle maar ruwe antwoorden op een eenvoudige strip. Dit artikel presenteert een manier om het beste van beide werelden te krijgen: laboratorium‑kwaliteit nauwkeurigheid uit een kleine bloedmonster met eenvoudige hardware, waarbij het meeste werk door slimme beeldanalyse wordt gedaan. Door te volgen hoe kleine gouddeeltjes zich gedragen in een druppel bloed en machinaal‑lerende software die beelden te laten interpreteren, tonen de auteurs een route naar thuis‑ en kliniektests die zowel gebruiksvriendelijk als moeilijk te misleiden zijn.
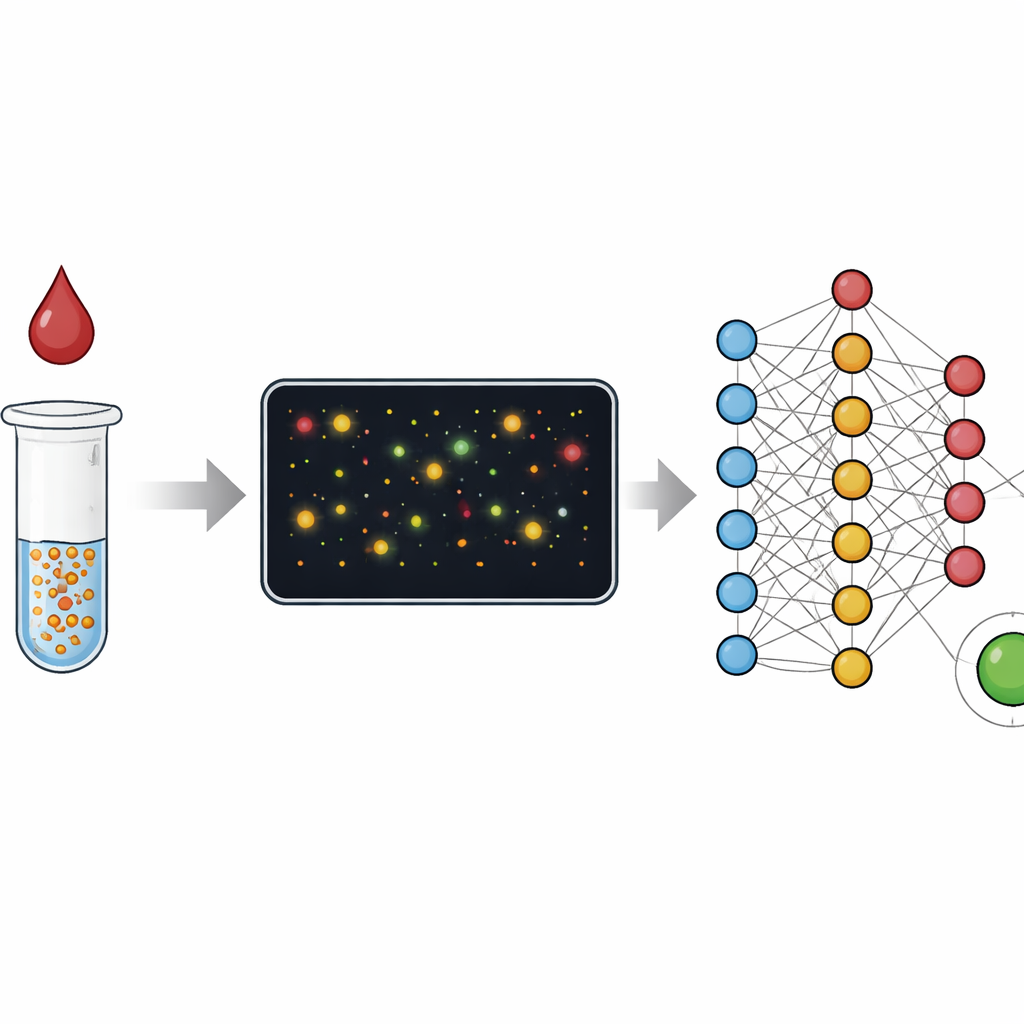
Van kleurveranderingen naar het tellen van deeltjes
Traditionele bloedtesten zoals ELISA registreren een gemiddelde kleurverandering van miljoenen moleculen in een putje, vergelijkbaar met een menigte beoordelen op basis van het totale geluid. Snelle striptests, of lateral flow‑assays, werken met een soortgelijk idee en ruilen nauwkeurigheid in voor snelheid en eenvoud. In deze studie richten de onderzoekers zich in plaats daarvan op individuele goudnanodeeltjes die samenklonteren wanneer ze hun doel in een monster vinden, zoals C‑reactief proteïne gekoppeld aan ontsteking of antilichamen tegen het virus dat COVID‑19 veroorzaakt. In plaats van alleen de bulkleur van de oplossing te meten, gebruiken ze dark‑field microscopie om kleine velden vol deze deeltjes en clusters te fotograferen en analyseren ze elk object afzonderlijk. Deze verschuiving van “analoge” kleur naar “digitale” telling vergroot sterk het concentratiebereik dat de test kan meten en maakt het eenvoudiger om te zien wanneer er iets mis is gegaan.
Door de rommel heen kijken in monstervoorbeelden uit de praktijk
Werkelijke bloedmonsters zijn rommelig: ze bevatten rode bloedcellen, vuil, bellen en andere visuele prikkels die eenvoudige beeldverwerkingsregels kunnen verwarren. Het team toont eerst aan dat ze, zelfs met afgestemde conventionele algoritmen, een schoon, bijna lineair verband kunnen extraheren tussen clustergrootte en C‑reactief proteïnegehalte, en dat ze dit rechtstreeks in vol bloed kunnen doen zonder de cellen uit te centrifugeren. Om artefacten systematischer aan te pakken, trainen ze vervolgens een segmentatiemodel dat elke pixel in een afbeelding labelt als nanodeeltje, cel, stof of achtergrond. Na het filteren van alles behalve de echte deeltjes gebruiken ze opnieuw clustergrootte als uitlezing. Met deze hybride aanpak klassificeren ze correct de COVID‑19‑antilichaamstatus in bewaarde patiëntsera met 96% specificiteit en 90% sensitiviteit, zelfs hoewel de beelden onder opzettelijk foutgevoelige omstandigheden zijn verzameld.
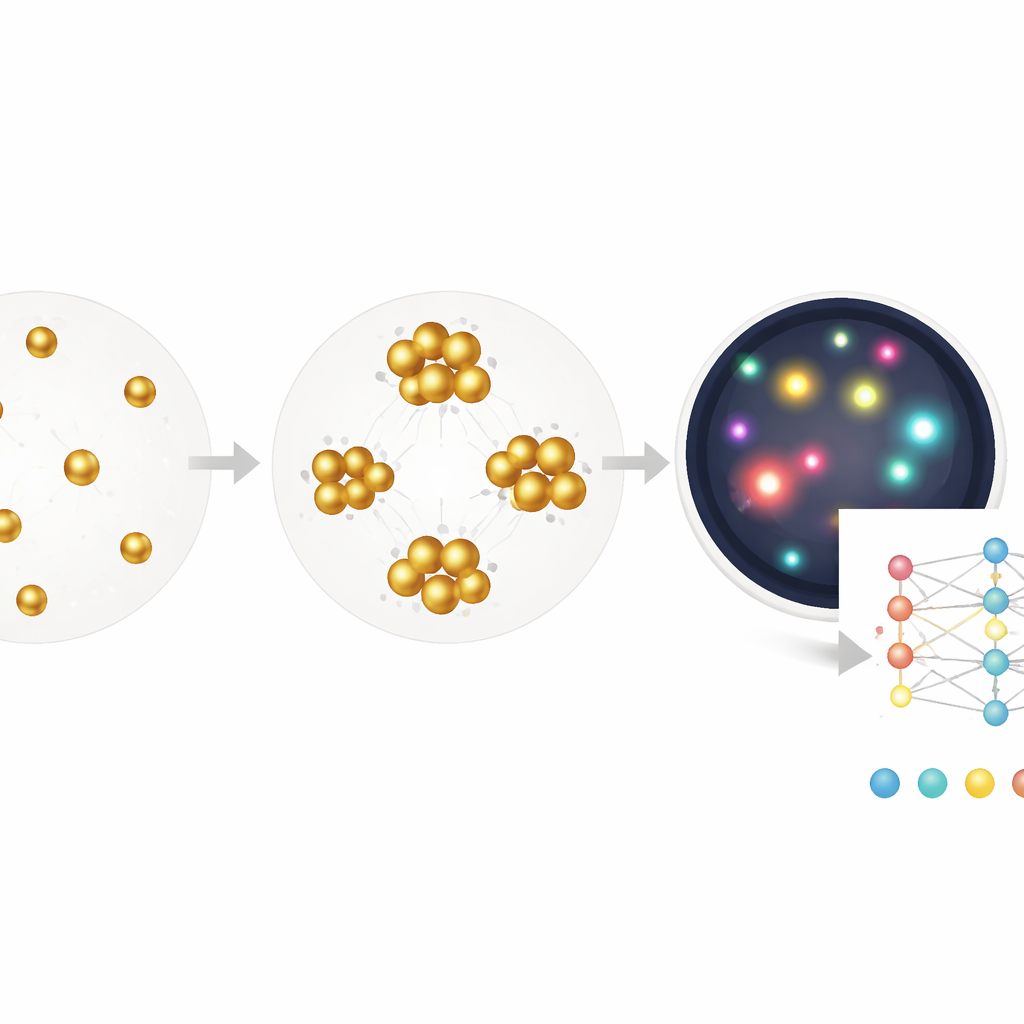
Het de computer laten ontdekken wat telt
Hoewel de segmentatiemethode helpt, berust deze nog op menselijke keuzes over welke kenmerken te meten zijn—zoals hoe groot of hoe helder een cluster moet zijn. De auteurs gaan verder door een diep neuraal netwerk te trainen dat direct van een ruwe afbeelding naar de concentratie antivirale antilichamen gaat, gebruikmakend van alleen de bekende concentratie als label en zonder pixel‑niveau annotaties. Dit end‑to‑end model, gebouwd op een standaard ResNet‑architectuur, leert effectief zijn eigen combinatie van aanwijzingen: subtiele kleurverschuivingen, dichtheid, clustervorm, lege ruimtes en meer. Getest op nieuwe monsters schat het de antilichaamniveaus over een bereik van meer dan drie en een halve orde van grootte, met een detectiegrens die het klinische ELISA‑kit benadert, terwijl het slechts één incubatie van 30 minuten nodig heeft en op zeer kleine volumes werkt.
Tests ontwerpen die af te stemmen zijn als een microscoop
Naast het demonstreren van werkende assays onderzoekt de studie ook hoe ver dit soort digitale deeltjestelling in principe kan worden gedreven. Met een wiskundig en simulatiekader laten de auteurs zien dat de gevoeligheid van dergelijke tests niet vastligt; ze hangt af van hoeveel deeltjes worden gebruikt, hoe uniform ze zijn en hoe goed enkele en gepaarde deeltjes te onderscheiden zijn op basis van helderheid. Door aan deze knoppen te draaien—vooral het aantal deeltjes en hun kwaliteit—betogen ze dat men in theorie extreem lage detecteerbare concentraties kan bereiken, hoofdzakelijk beperkt door fundamentele telstatistieken. Machinaal leren geeft een extra impuls door te verhogen hoeveel deeltjes betrouwbaar kunnen worden gebruikt en door de discriminatie tussen echte bindingsgebeurtenissen en willekeurige ruis te verbeteren.
Op weg naar slimmere, meer tolerante bloedtesten
Al met al suggereert het werk dat het koppelen van eenvoudige optiek aan geavanceerde beeldanalyse tests kan opleveren die concurreren met goudstandaard laboratoriummethoden terwijl ze de variabiliteit van gebruik in de echte wereld verdragen. In plaats van steeds preciezere hardware te bouwen, leunt de aanpak op de rijke informatie die al in beelden aanwezig is en laat software signaal van rommel scheiden. Voor patiënten en zorgsystemen kan dit betrouwbaardere point‑of‑care‑ en zelfuitgevoerde tests betekenen voor veelvoorkomende bloedmarkers en infectieziekten, zonder de noodzaak van complexe instrumenten of deskundige operators.
Bronvermelding: McAffee, D.B., Hu, Q., Arnob, A. et al. Homogeneous image-based digital immunoassays with high error tolerance. npj Imaging 4, 30 (2026). https://doi.org/10.1038/s44303-026-00164-9
Trefwoorden: digitale immunoassay, nanodeeltje‑imaging, machinaal leren diagnostiek, point‑of‑care testen, SARS‑CoV‑2 antilichamen