Clear Sky Science · zh
将连结的质谱-基因组学与语言/变换器模型用于加速天然产物发现
为什么新的药物隐匿于平常之中
我们许多最重要的药物,包括抗生素和抗癌药,来自产生复杂天然化合物的微小微生物。然而,在这座隐秘药房中发现新分子既缓慢又昂贵,因为科学家必须在庞大的微生物库中筛选并猜测哪些值得进一步测试。本文展示了如何将先进的人工智能与现代实验测量相结合,大幅加速这一搜寻过程,帮助研究人员在进行繁重实验前就锁定最有前景的微生物。 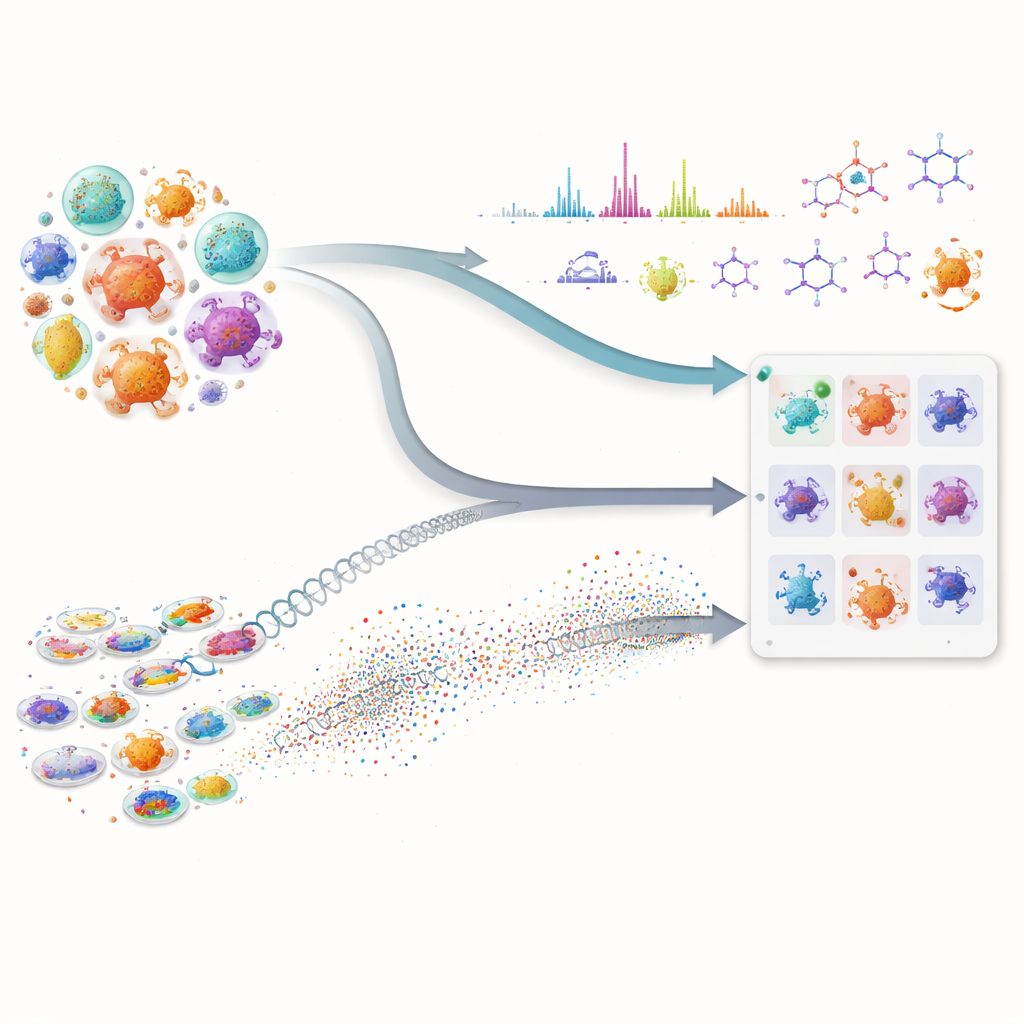
将微生物DNA变成可检索的图谱
该方法的第一部分着眼于微生物的遗传“蓝图”。研究团队不是仅仅使用传统的DNA比对,而是应用强大的蛋白质语言模型——这些AI系统已经从数百万条蛋白质序列中学习到模式。模型将每个生物合成相关的蛋白质转换为高维数值指纹,从而即便底层DNA发生大量变化或分散在片段中(这是粗略草稿基因组的常见问题),也能检测到功能上的远缘亲缘关系。研究者随后对每个微生物进行评分,依据其蛋白质中与已知合成途径蛋白相似的数量以及整体相似性的强度。这个复合评分突出了那些蛋白组合看起来可能构建目标化合物的菌株,同时削弱了仅携带一两个常见、非专一性酶的微生物的权重。
用AI解读复杂的化学混合物
第二部分聚焦于微生物在实验室中实际产生的产物。通过液相色谱-串联质谱,科学家记录发酵培养物中分子的详细“指纹”。作者自研的智能结构解析工作流(Workflow for Intelligent Structural Elucidation,简称WISE)清理这些信号、分离重叠峰,并利用在数百万类天然产物结构上训练的AI模型来猜测哪些分子构型最符合每个谱图。一种基于变换器(transformer)的模型预测候选分子的谱图应有的样式,组合评分则衡量观察到的谱图与预测图样的匹配程度,包括同位素分布和精确质量等细节。通过在标准基准上分析这些评分的分布,团队确定了将可能的真实匹配与噪声或相似诱饵区分开的阈值,从而能够将某些结构猜想标记为高置信度,并过滤掉明显错误的猜测。
将基因与化学证据汇聚
该方法的真正威力来自于把这两类信息流合并。对于任何感兴趣的分子,只有当微生物同时表现出遗传潜力——其蛋白质类似于已知途径中的蛋白——和化学证据——其产生的谱图特征符合预期结构时,才会升至名单前列。这种交叉验证减少了在单一数据类型中看起来很有说服力但实际为假线索的情况。作者在大量放线菌株及其突变体上测试了框架,聚焦于三种截然不同的抗微生物化合物:缬氨酰内酯(valinomycin)、表面活性肽(surfactin)和抗生素新霉素B。在不依赖完美基因组或完整谱图库的情况下,该系统在数据混乱或不完整(这是早期发现工作中常见的现实情况下)仍能良好运作。 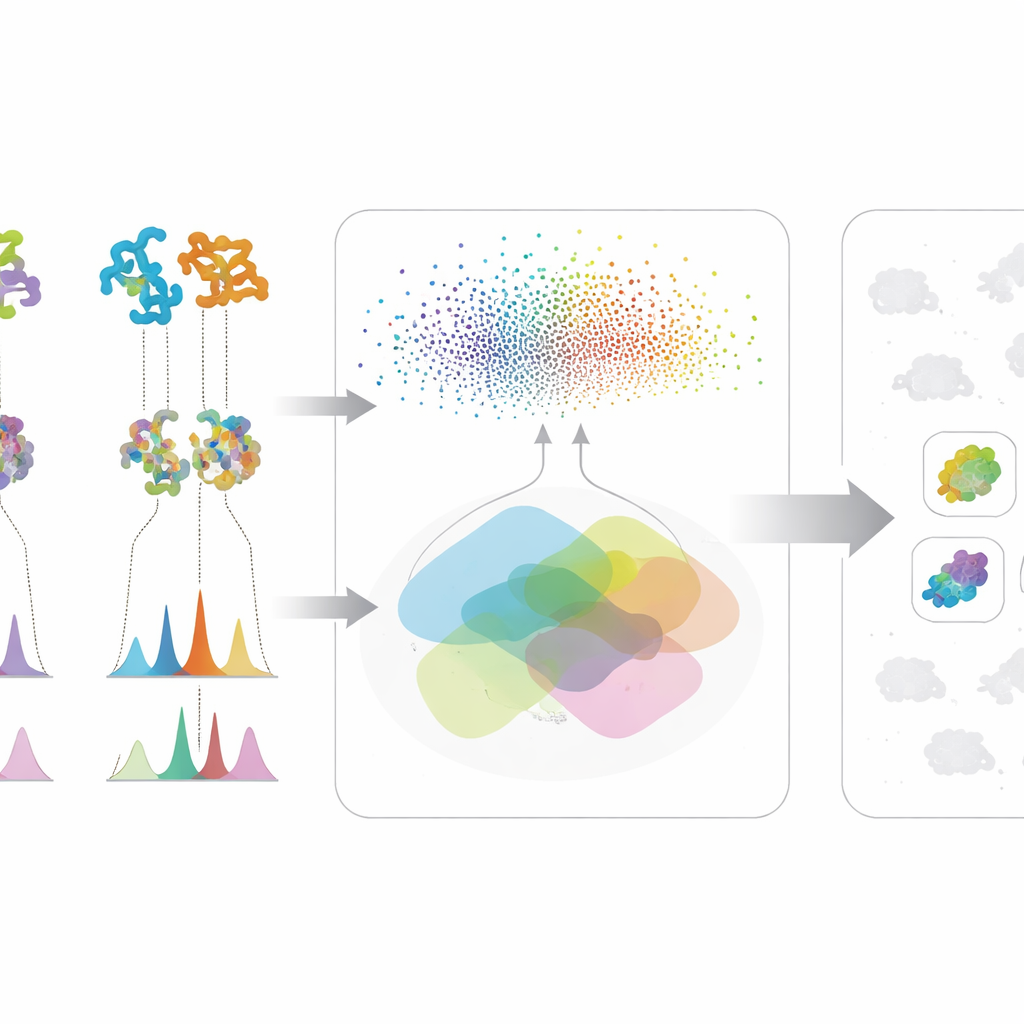
将框架付诸考验
在新霉素B的案例研究中,AI首先寻找其蛋白看起来像已知新霉素途径的微生物,然后检查这些菌株的质谱是否暗示存在新霉素类分子。四个菌株通过了两重筛选;其中三个通过实验确认能产生新霉素B,包括两个先前未被识别的生产者。对于缬氨酰内酯和表面活性肽,该框架也以高精度定位了生产菌株,而将评分随机打乱的对照测试表现则差得多。这些结果表明,模型捕捉的是真实的生物学关系,而不仅仅是数据中的随机巧合,并且它能够在拥挤的搜索空间中成功引导研究者找到最可能的命中对象。
这对未来药物发现意味着什么
通俗地说,作者构建了一个面向天然产物发现的智能推荐引擎。科学家们无需以蛮力测试每种微生物和每个化学信号,而可以将注意力集中在那些遗传潜力与化学产出一致的短名单菌株上。这大大减少了浪费的工作量,同时仍保留发现尚未被任何参考书收录的意外分子的可能性。随着AI模型和数据集的持续改进,这种整合基因组与代谢组的推理能力可能打开微生物化学学的广阔未知领域,潜在地在社会最需要的时候揭示新的抗生素和其他有用化合物。
引用: Tay, D.W.P., Koh, W., Ang, S.J. et al. Accelerating natural product discovery with linked MS-genomics and language/transformer-based models. npj Antimicrob Resist 4, 31 (2026). https://doi.org/10.1038/s44259-026-00206-7
关键词: 天然产物发现, 微生物代谢产物, 质谱, 蛋白质语言模型, 人工智能在药物发现中的应用