Clear Sky Science · pt
Acelerando a descoberta de produtos naturais com MS-genômica vinculada e modelos baseados em linguagem/transformer
Por que novos medicamentos se escondem à vista de todos
Muitos dos nossos medicamentos mais importantes, incluindo antibióticos e fármacos contra o câncer, vêm de micróbios minúsculos que produzem compostos naturais complexos. Ainda assim, encontrar novas moléculas nesse “farmacêutico” oculto é lento e caro, porque cientistas precisam vasculhar enormes bibliotecas de microrganismos e adivinhar quais valem a pena testar. Este artigo mostra como combinar inteligência artificial avançada com medições laboratoriais modernas pode acelerar muito essa busca, ajudando pesquisadores a concentrar-se nos micróbios mais promissores antes de realizar experimentos trabalhosos. 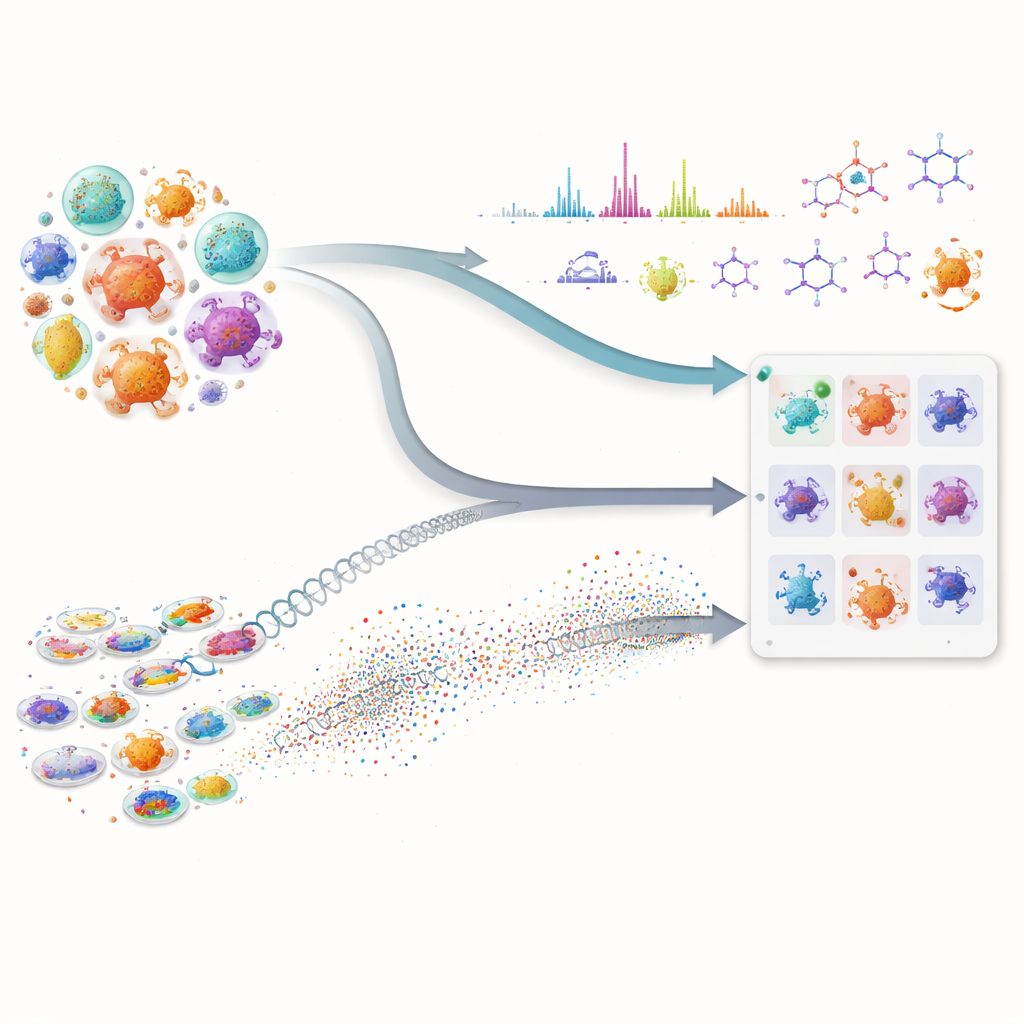
Convertendo o DNA microbiano em um mapa pesquisável
A primeira parte da abordagem examina as “plantas” genéticas dos micróbios. Em vez de usar apenas o pareamento tradicional de DNA, a equipe aplica poderosos modelos de linguagem para proteínas — sistemas de IA que aprenderam padrões em milhões de sequências proteicas. Esses modelos convertem cada proteína biossintética em uma impressão digital numérica de alta dimensão. Isso permite detectar parentes funcionais distantes mesmo quando o DNA subjacente mudou muito ou está fragmentado, um problema comum em genomas de rascunho. Os pesquisadores então pontuam cada microrganismo pelo número de suas proteínas que se assemelham às de uma via conhecida para sintetizar uma molécula alvo, e pela intensidade dessa similaridade no conjunto. Essa pontuação composta destaca cepas cujo conjunto combinado de proteínas parece capaz de construir o composto desejado, ao mesmo tempo em que desacredita micróbios que só possuem uma ou duas enzimas comuns e não especializadas.
Lendo misturas químicas complexas com IA
A segunda parte foca no que os microrganismos realmente produzem em laboratório. Usando cromatografia líquida e espectrometria de massa em tandem, os cientistas registram “impressões digitais” detalhadas das moléculas nos caldos de fermentação. O Workflow for Intelligent Structural Elucidation dos autores, ou WISE, limpa esses sinais, separa picos sobrepostos e então usa modelos de IA treinados em milhões de estruturas semelhantes a produtos naturais para inferir quais formas moleculares melhor correspondem a cada espectro. Um modelo baseado em transformer prevê como os espectros de moléculas candidatas deveriam parecer, e uma pontuação combinada avalia quão bem os padrões observados e previstos se alinham, incluindo detalhes finos como padrões isotópicos e massa exata. Ao analisar como essas pontuações se distribuem em um benchmark padrão, a equipe identifica limiares que separam prováveis correspondências reais de ruído ou disfarces semelhantes, permitindo rotular alguns palpites estruturais como de alta confiança e filtrar os obviamente errados.
Unindo genes e químicos
O real poder do método vem de mesclar essas duas correntes de informação. Para qualquer molécula de interesse, um micróbio sobe ao topo da lista apenas se mostrar tanto potencial genético — suas proteínas se assemelharem às de uma via conhecida — quanto evidência química — ele produzir sinais espectrais compatíveis com a estrutura esperada. Essa checagem cruzada reduz falsos positivos que parecem convincentes em apenas um tipo de dado. Os autores testaram sua estrutura em uma grande coleção de cepas e mutantes de actinobactérias, concentrando-se em três compostos antimicrobianos bem distintos: valinomicina, surfactina e o antibiótico neomicina B. Em vez de depender de genomas perfeitos ou bibliotecas espectrais completas, o sistema funciona bem mesmo quando os dados são confusos ou incompletos, uma realidade comum em campanhas de descoberta em estágio inicial. 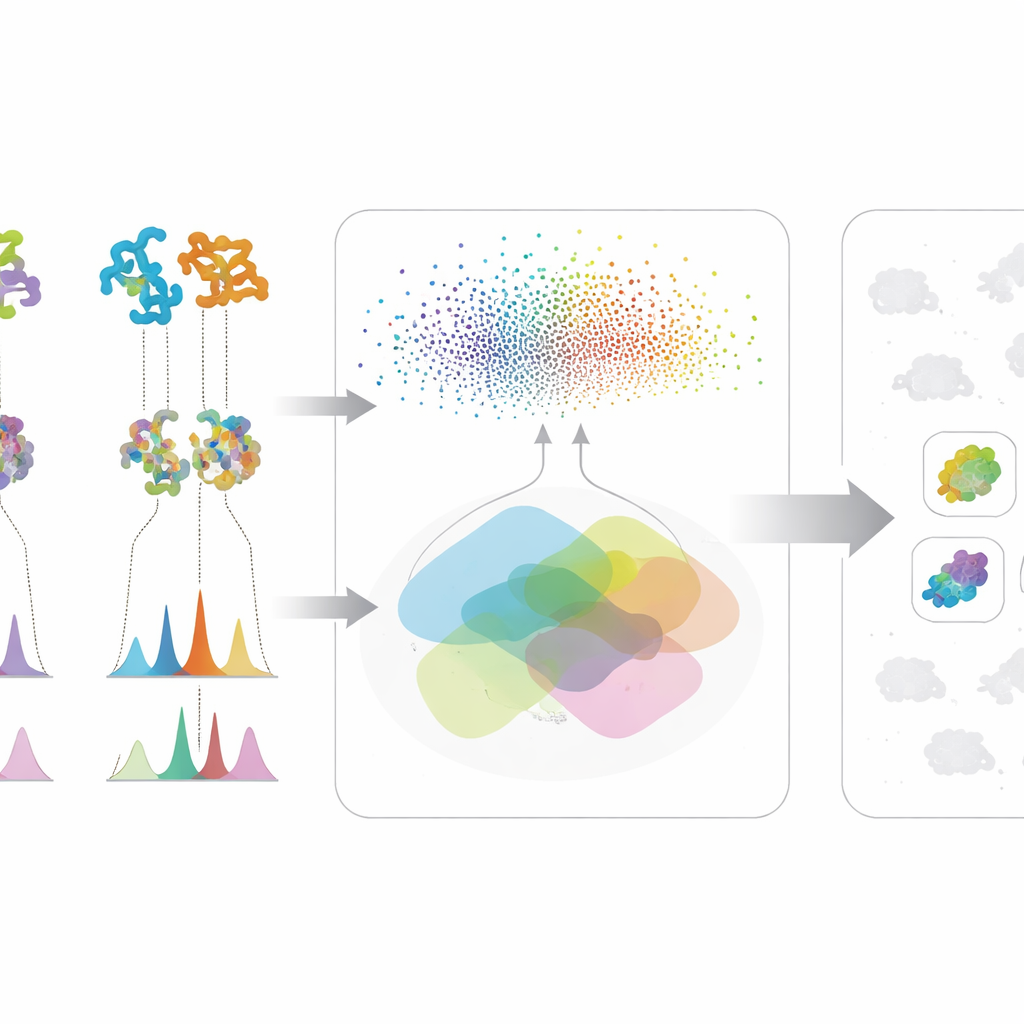
Colocando a estrutura à prova
No estudo de caso da neomicina B, a IA primeiro buscou microrganismos cujas proteínas se parecessem com as da via conhecida da neomicina e, em seguida, verificou se seus espectros de massa sugeriam a presença de moléculas semelhantes à neomicina. Quatro cepas passaram em ambos os filtros; três delas foram confirmadas experimentalmente como produtoras de neomicina B, incluindo duas produtoras antes não reconhecidas. Para valinomicina e surfactina, a estrutura também identificou produtores com alta precisão, enquanto um teste de controle que embaralhou aleatoriamente as pontuações teve desempenho muito inferior. Esses resultados mostram que o modelo captura relações biológicas reais, não apenas coincidências aleatórias nos dados, e que ele pode orientar com sucesso os pesquisadores para as ocorrências mais prováveis em um espaço de busca denso.
O que isso significa para a descoberta de medicamentos no futuro
Em termos práticos, os autores construíram um motor de recomendação inteligente para descoberta de produtos naturais. Em vez de testar todos os microrganismos e todos os sinais químicos por força bruta, os cientistas podem agora concentrar-se em uma lista curta de cepas onde potencial genético e produção química concordam. Isso reduz muito o esforço desperdiçado, ao mesmo tempo em que deixa espaço para descobrir moléculas inesperadas que ainda não estão em nenhum livro de referência. À medida que modelos de IA e conjuntos de dados continuarem a melhorar, esse tipo de raciocínio integrado genômico e metabolômico pode desbloquear vastas regiões da química microbiana que permanecem inexploradas, potencialmente revelando novos antibióticos e outros compostos úteis quando a sociedade mais precisar.
Citação: Tay, D.W.P., Koh, W., Ang, S.J. et al. Accelerating natural product discovery with linked MS-genomics and language/transformer-based models. npj Antimicrob Resist 4, 31 (2026). https://doi.org/10.1038/s44259-026-00206-7
Palavras-chave: descoberta de produtos naturais, metabólitos microbianos, espectrometria de massa, modelos de linguagem para proteínas, IA na descoberta de medicamentos