Clear Sky Science · ja
リンクされたMS-ゲノミクスと言語/トランスフォーマーベースモデルによる天然物探索の加速
新薬は身近に潜んでいる理由
抗生物質や抗がん剤を含む私たちの重要な薬の多くは、複雑な天然化合物を作る微小な微生物から生まれます。しかし、この隠れた薬局から新しい分子を見つける作業は遅く高価です。研究者は膨大な微生物ライブラリをふるいにかけ、どれを試験に回すかを推測しなければなりません。本論文は、高度な人工知能と最新の実験測定を組み合わせることで探索が大幅に速まり、手間のかかる実験の前に最も有望な微生物を絞り込めることを示します。 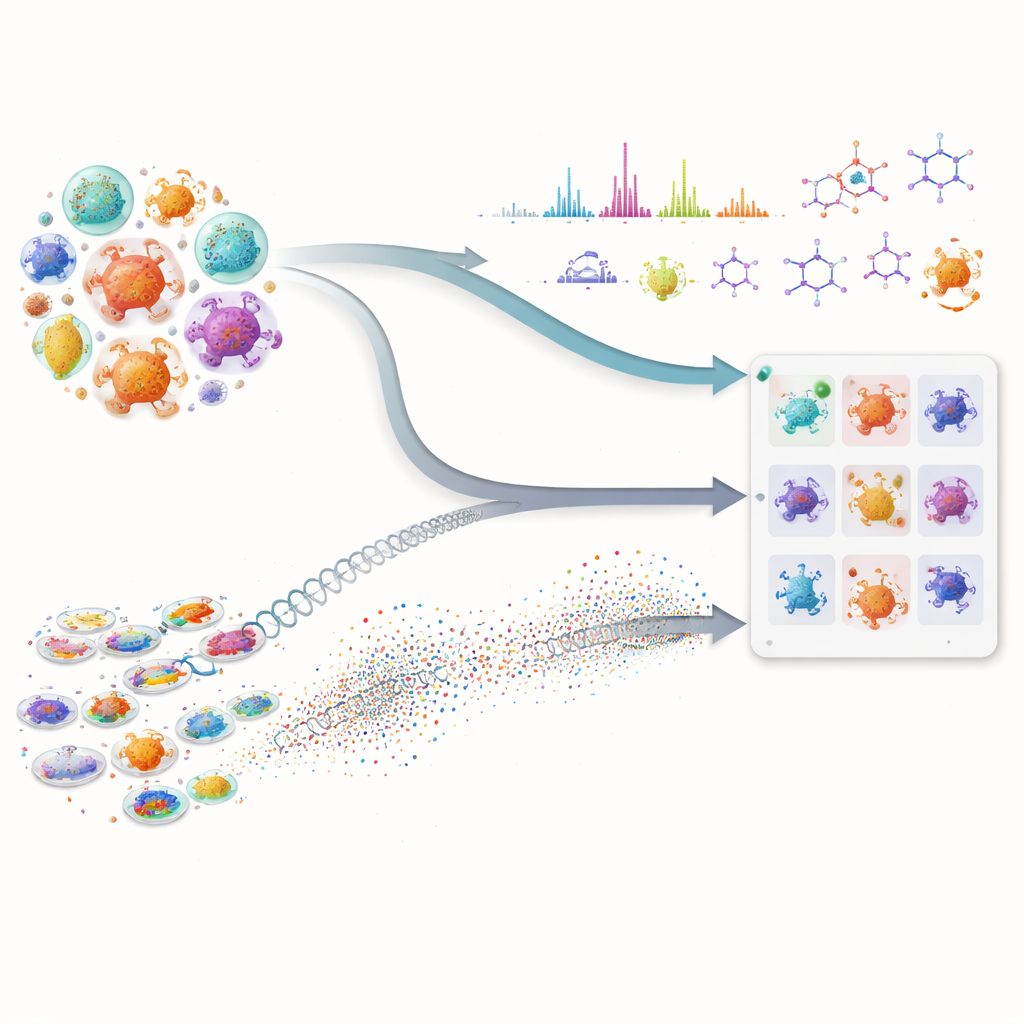
微生物のDNAを検索可能な地図に変える
アプローチの第一部は微生物の遺伝的「設計図」を調べます。従来のDNA照合だけでなく、研究チームは数百万のタンパク質配列から学習した強力なタンパク質言語モデルを適用します。これらのモデルは各生合成タンパク質を高次元の数値的フィンガープリントに変換します。その結果、基礎となるDNAが大きく変化していたり断片化されていたりする、ラフドラフトゲノムでよく起きる状況でも遠縁の機能的な類縁を検出できるようになります。研究者は次に、既知の標的分子を作る経路に似たタンパク質がどれだけあるか、そして全体の類似性がどれほど強いかで各微生物をスコア化します。この複合スコアにより、目的の化合物を構築できそうなタンパク質群を持つ株が浮き上がり、一般的で非特殊的な酵素を1、2個だけ持つ微生物は低く評価されます。
AIで複雑な化学混合物を読み解く
第二部は微生物が実際に実験室で生産するものに焦点を当てます。液体クロマトグラフィーとタンデム質量分析を用いて、発酵培地中の分子の詳細な「フィンガープリント」を記録します。著者らの社内ワークフローであるWorkflow for Intelligent Structural Elucidation(WISE)は、これらの信号を整え、重なり合うピークを分離し、次に数百万の天然物類似構造で訓練されたAIモデルを使って各スペクトルに最も適合する分子形状を推定します。トランスフォーマーベースのモデルは候補分子のスペクトルがどのように見えるべきかを予測し、観測されたパターンと予測パターンの整合性を、同位体パターンや正確質量などの細部も含めて総合的に評価するスコアを作ります。標準ベンチマーク上でこれらのスコア分布を解析することで、実際の一致とノイズや類似デコイを分けるしきい値を特定し、いくつかの構造推定を高信頼度とラベル付けし、明らかに誤ったものを除外できます。
遺伝子と化学情報の統合
この手法の真の威力は、これら二つの情報の流れを統合することで発揮されます。興味のある任意の分子について、ある微生物がリストの上位に上がるのは、遺伝的潜在力—そのタンパク質群が既知の経路に似ていること—と化学的証拠—期待される構造に合致するスペクトル特徴を産生していること—の両方が揃っている場合のみです。この相互照合により、片方のデータだけでは説得力があっても誤導となる候補を減らせます。著者らはアクチノバクテリア株とその変異体の大規模コレクションでフレームワークを検証し、バリノマイシン、サーファクチン、および抗生物質ネオマイシンBという性質の異なる三つの抗菌化合物に注目しました。完全なゲノムや完全なスペクトルライブラリに依存するのではなく、データが散らばっていたり不完全であったりする、初期探索では普通に起きる状況でもシステムは良好に機能しました。 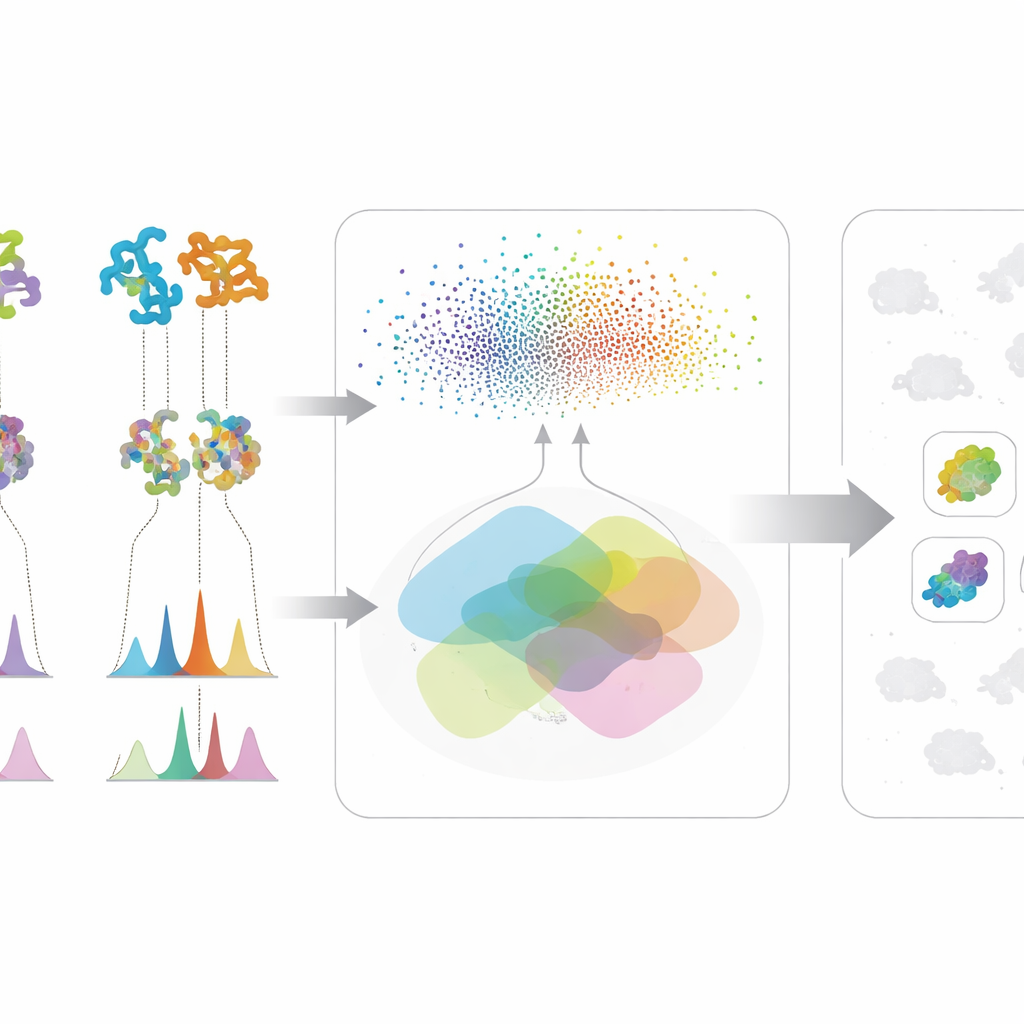
フレームワークの実地検証
ネオマイシンBのケーススタディでは、AIはまず既知のネオマイシン経路のタンパク質に似たタンパク質を持つ微生物を探し、次に彼らの質量スペクトルがネオマイシン類似分子の存在を示唆しているかを確認しました。四つの株が両方のフィルタを通過し、そのうち三つは実験的にネオマイシンBの産生が確認され、その中には以前に認識されていなかった二つの生産株も含まれていました。バリノマイシンとサーファクチンについても、フレームワークは高精度で生産株を特定しました。一方でスコアをランダムにシャッフルする対照試験ははるかに成績が悪かったです。これらの結果は、モデルがデータ中の偶然の一致ではなく実際の生物学的関係を捉えており、探索空間が混雑している中で最も可能性の高いヒットに研究者を導くことができることを示しています。
将来の医薬品探索への示唆
日常語に置き換えれば、著者らは天然物探索のための賢い推薦エンジンを構築しました。すべての微生物や全ての化学信号を力任せに試す代わりに、遺伝的潜在力と化学的産物が一致する短い株のリストに研究者の注意を集中させられます。これにより無駄な労力が大幅に削減される一方で、まだどの参考書にも載っていない予期せぬ分子を発見する余地は残ります。AIモデルとデータセットが改良され続けるにつれ、この種の統合されたゲノミクスとメタボロミクスに基づく推論は、未踏の微生物化学領域を解き明かし、新たな抗生物質やその他有用な化合物を社会が最も必要とする時期に明らかにする可能性があります。
引用: Tay, D.W.P., Koh, W., Ang, S.J. et al. Accelerating natural product discovery with linked MS-genomics and language/transformer-based models. npj Antimicrob Resist 4, 31 (2026). https://doi.org/10.1038/s44259-026-00206-7
キーワード: 天然物探索, 微生物代謝物, 質量分析, タンパク質言語モデル, 医薬品探索におけるAI