Clear Sky Science · it
Accelerare la scoperta di prodotti naturali con modelli collegati MS-genomica e basati su language/transformer
Perché i nuovi farmaci si nascondono in bella vista
Molti dei nostri farmaci più importanti, inclusi antibiotici e terapie oncologiche, provengono da microrganismi che producono molecole naturali complesse. Trovare nuove molecole in questa farmacia nascosta è però lento e costoso, perché gli scienziati devono setacciare enormi collezioni di microrganismi e indovinare quali vale la pena testare. Questo articolo mostra come la combinazione di intelligenza artificiale avanzata e misure di laboratorio moderne possa accelerare notevolmente la ricerca, aiutando i ricercatori a concentrare gli sforzi sui ceppi più promettenti prima di intraprendere esperimenti laboriosi. 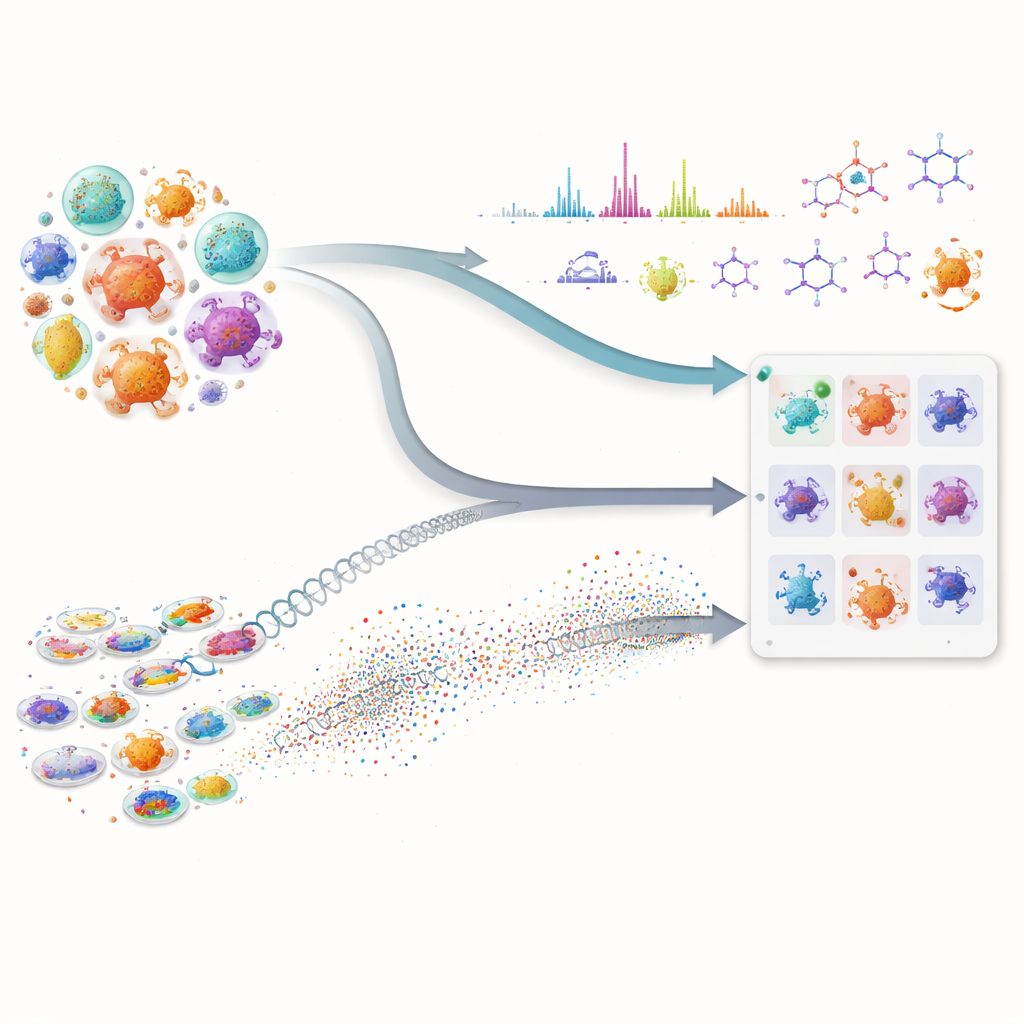
Trasformare il DNA microbico in una mappa ricercabile
La prima parte dell’approccio esamina i “progetti” genetici dei microrganismi. Invece di usare solo il tradizionale confronto del DNA, il gruppo impiega potenti modelli linguistici per proteine — sistemi di IA che hanno appreso schemi da milioni di sequenze proteiche. Questi modelli convertono ogni proteina biosintetica in un’impronta numerica ad alta dimensione. Questo permette di rilevare parenti funzionali distanti anche quando il DNA sottostante è molto cambiato o frammentato, un problema comune nelle bozze di genomi. I ricercatori poi assegnano a ogni microbo un punteggio basato su quante delle sue proteine somigliano a quelle di una via biosintetica nota per produrre una molecola target e su quanto è forte quella somiglianza complessiva. Questo punteggio composito mette in evidenza ceppi il cui insieme proteico combinato sembra in grado di costruire il composto desiderato, escludendo invece i microrganismi che possiedono soltanto una o due enzimi comuni e non specializzati.
Leggere miscele chimiche complesse con l’IA
La seconda parte si concentra su ciò che i microbi effettivamente producono in laboratorio. Usando cromatografia liquida e spettrometria di massa tandem, gli scienziati registrano “impronte” dettagliate delle molecole presenti nei brodi di fermentazione. Il Workflow for Intelligent Structural Elucidation degli autori, o WISE, pulisce questi segnali, separa picchi sovrapposti e poi usa modelli di IA addestrati su milioni di strutture simili a prodotti naturali per ipotizzare quali forme molecolari corrispondono meglio a ogni spettro. Un modello basato su transformer predice come dovrebbero apparire gli spettri delle molecole candidate e un punteggio combinato valuta quanto bene i pattern osservati e quelli predetti si allineano, includendo dettagli fini come i pattern isotopici e la massa esatta. Analizzando la distribuzione di questi punteggi su un benchmark standard, il team identifica soglie che separano probabili corrispondenze reali dal rumore o da decoy simili, permettendo di etichettare alcune ipotesi strutturali come ad alta confidenza e di filtrare quelle chiaramente sbagliate.
Mettere insieme geni e chimica
La vera potenza del metodo deriva dalla fusione di questi due filoni informativi. Per una data molecola di interesse, un microbo risale in cima alla lista solo se mostra sia il potenziale genetico — le sue proteine somigliano a quelle di una via nota — sia l’evidenza chimica — produce caratteristiche spettrali compatibili con la struttura prevista. Questo controllo incrociato riduce i falsi indizi che appaiono convincenti in un solo tipo di dato. Gli autori hanno testato il loro framework su una vasta collezione di ceppi e mutanti di actinobatteri, concentrandosi su tre composti antimicrobici molto diversi: valinomicina, surfactina e l’antibiotico neomicina B. Invece di dipendere da genomi perfetti o da librerie spettrali complete, il sistema funziona bene anche quando i dati sono disordinati o incompleti, una realtà comune nelle campagne di scoperta in fase iniziale. 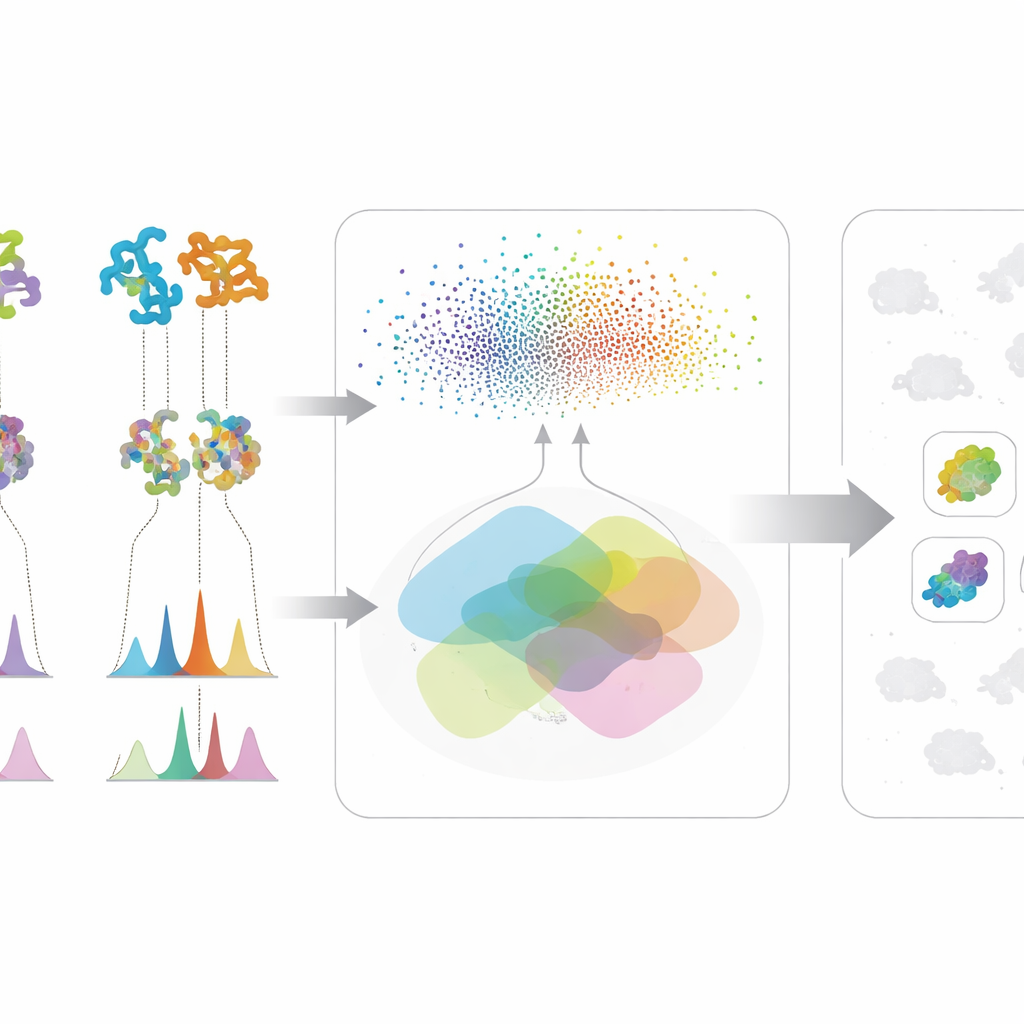
Mettere il framework alla prova
Nello studio di caso su neomicina B, l’IA ha prima cercato microbi le cui proteine somigliassero a quelle della via nota della neomicina, quindi ha verificato se i loro spettri di massa suggerivano la presenza di molecole simili alla neomicina. Quattro ceppi hanno superato entrambi i filtri; tre di questi sono stati confermati sperimentalmente come produttori di neomicina B, inclusi due produttori precedentemente non riconosciuti. Per valinomicina e surfactina, il framework ha individuato produttori con alta precisione, mentre un test di controllo che mescolava casualmente i punteggi ha dato risultati molto peggiori. Questi risultati mostrano che il modello cattura relazioni biologiche reali, non semplici coincidenze casuali nei dati, e che può guidare con successo i ricercatori verso i candidati più probabili in uno spazio di ricerca affollato.
Cosa significa per la futura scoperta di farmaci
In termini pratici, gli autori hanno costruito un motore di raccomandazione intelligente per la scoperta di prodotti naturali. Invece di testare ogni microbo e ogni segnale chimico in modo massiccio, gli scienziati possono ora concentrarsi su una lista breve di ceppi in cui il potenziale genetico e l’output chimico concordano. Questo riduce notevolmente gli sforzi sprecati, lasciando comunque spazio alla scoperta di molecole inaspettate che non sono ancora in alcun repertorio. Man mano che i modelli di IA e i dataset continueranno a migliorare, questo tipo di ragionamento integrato su genomica e metabolomica potrebbe sbloccare vaste aree della chimica microbica ancora inesplorate, rivelando potenzialmente nuovi antibiotici e altri composti utili proprio quando la società ne ha più bisogno.
Citazione: Tay, D.W.P., Koh, W., Ang, S.J. et al. Accelerating natural product discovery with linked MS-genomics and language/transformer-based models. npj Antimicrob Resist 4, 31 (2026). https://doi.org/10.1038/s44259-026-00206-7
Parole chiave: scoperta di prodotti naturali, metaboliti microbici, spettrometria di massa, modelli linguistici per proteine, IA nella scoperta di farmaci