Clear Sky Science · nl
Versnellen van natuurstoffenontdekking met gekoppelde MS-genomics en taal-/transformer-gebaseerde modellen
Waarom nieuwe medicijnen in het zicht verborgen liggen
Veel van onze belangrijkste geneesmiddelen, waaronder antibiotica en geneesmiddelen tegen kanker, komen van microscopische microben die complexe natuurlijke chemicaliën produceren. Toch is het vinden van nieuwe moleculen in deze verborgen apotheek traag en duur, omdat onderzoekers enorme collecties microben moeten doorzoeken en moeten raden welke de moeite waard zijn om te testen. Dit artikel laat zien hoe het combineren van geavanceerde kunstmatige intelligentie met moderne laboratoriummetingen de zoektocht sterk kan versnellen, waardoor onderzoekers zich kunnen richten op de meest veelbelovende microben voordat ze tijdrovende experimenten uitvoeren. 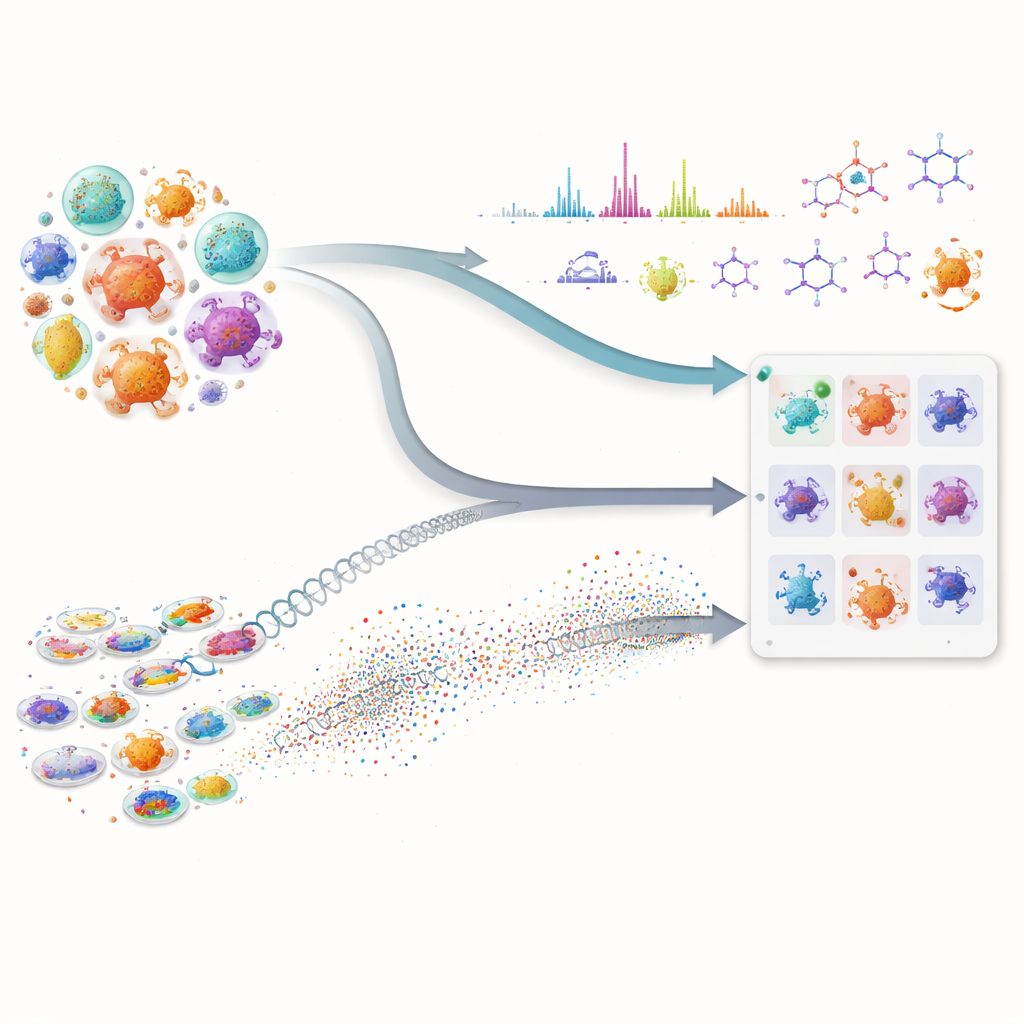
Microbiole DNA omzetten in een doorzoekbare kaart
Het eerste deel van de aanpak bekijkt de genetische “blauwdrukken” van microben. In plaats van alleen traditionele DNA-matching te gebruiken, past het team krachtige eiwit-taalmodellen toe—AI-systemen die patronen hebben geleerd uit miljoenen eiwitsequenties. Deze modellen zetten elk biosynthetisch eiwit om in een hoog-dimensionele numerieke vingerafdruk. Daardoor kunnen onderzoekers verre functionele verwanten opsporen, zelfs wanneer het onderliggende DNA sterk is veranderd of over fragmenten verdeeld is, een veelvoorkomend probleem bij ruwe conceptgenomen. De onderzoekers scoren vervolgens elke microbe op hoeveel van zijn eiwitten lijken op die in een bekend pad voor het maken van een doelmolecuul, en op hoe sterk die totale gelijkenis is. Deze samengestelde score brengt stammen naar voren waarvan de gecombineerde eiwitten erop lijken dat ze het gewenste verbinding kunnen opbouwen, terwijl microben die slechts één of twee veelvoorkomende, niet-gespecialiseerde enzymen hebben, worden minder zwaar gewogen.
Complexe chemische mengsels lezen met AI
Het tweede deel richt zich op wat de microben in het laboratorium daadwerkelijk produceren. Met behulp van vloeistofchromatografie en tandem-massaspectrometrie nemen wetenschappers gedetailleerde “vingerafdrukken” van de moleculen in fermentatiebaden op. De in-house Workflow for Intelligent Structural Elucidation, of WISE, van de auteurs zuivert deze signalen, scheidt overlappende pieken en gebruikt vervolgens AI-modellen die zijn getraind op miljoenen natuurstofachtige structuren om te raden welke moleculaire vormen het beste bij elk spectrum passen. Een transformer-gebaseerd model voorspelt hoe de spectra van kandidaatmoleculen eruit zouden moeten zien, en een gecombineerde score weegt hoe goed de waargenomen en voorspelde patronen overeenkomen, inclusief fijne details zoals isotopische patronen en exacte massa. Door te analyseren hoe deze scores zich verdelen op een standaard benchmark, identificeert het team drempels die waarschijnlijke echte matches scheiden van ruis of gelijkende decoys, waardoor ze sommige structurele gissingen als met hoge betrouwbaarheid kunnen labelen en duidelijk foute kunnen filteren.
Genen en chemicaliën samenbrengen
De echte kracht van de methode komt voort uit het samenvoegen van deze twee informatiestromen. Voor elk interessant molecuul komt een microbe pas bovenaan de lijst te staan als deze zowel genetisch potentieel heeft—zijn eiwitten lijken op die in een bekend pad—als chemisch bewijs—het produceert spectrale kenmerken die bij de verwachte structuur passen. Deze kruiscontrole vermindert valse leads die alleen overtuigend lijken in één type data. De auteurs testten hun raamwerk op een grote verzameling actinobacteriële stammen en mutanten, met de focus op drie zeer verschillende antimicrobiële verbindingen: valinomycine, surfactine en het antibioticum neomycine B. In plaats van te vertrouwen op perfecte genomen of complete spectrumbibliotheken, werkt het systeem goed zelfs wanneer gegevens rommelig of incompleet zijn, wat een veelvoorkomende realiteit is in vroegtijdige ontdekkingscampagnes. 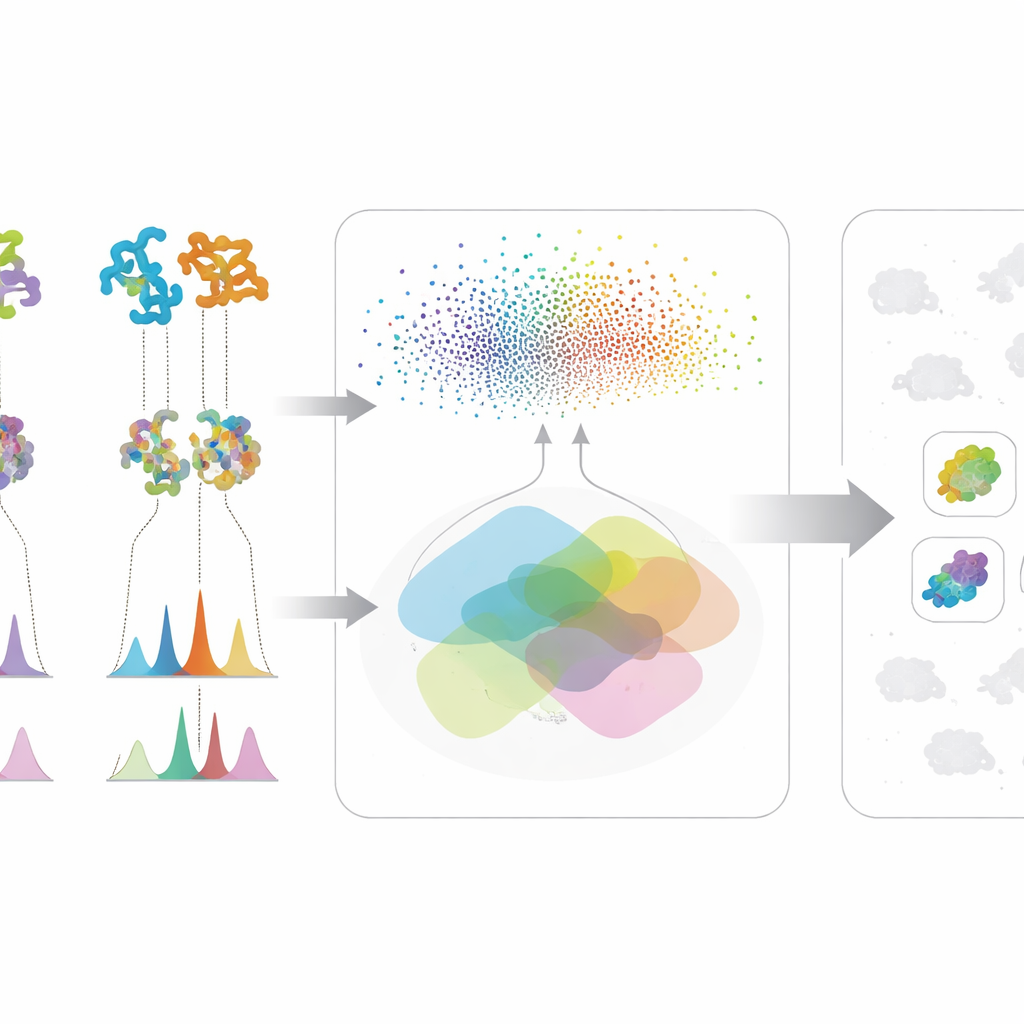
Het raamwerk op de proef stellen
In de casestudy van neomycine B zocht de AI eerst naar microben waarvan de eiwitten leken op die in het bekende neomycinepad, en controleerde vervolgens of hun massaspectra duidden op de aanwezigheid van neomycine-achtige moleculen. Vier stammen slaagden voor beide filters; drie daarvan werden experimenteel bevestigd als producenten van neomycine B, waaronder twee eerder niet-erkende producenten. Voor valinomycine en surfactine identificeerde het raamwerk ook producenten met hoge precisie, terwijl een controletest met willekeurig door elkaar gegooide scores veel slechter presteerde. Deze resultaten tonen aan dat het model echte biologische relaties vastlegt, niet slechts toevallige overeenkomsten in de data, en dat het onderzoekers succesvol kan leiden naar de meest waarschijnlijke hits in een druk zoekgebied.
Wat dit betekent voor toekomstige geneesmiddelenontdekking
Simpel gezegd hebben de auteurs een slim aanbevelingssysteem gebouwd voor de ontdekking van natuurstoffen. In plaats van elke microbe en elk chemisch signaal op brute kracht te testen, kunnen wetenschappers zich nu concentreren op een korte lijst stammen waar genetisch potentieel en chemische output overeenkomen. Dit vermindert verspilde inspanning aanzienlijk, terwijl er nog steeds ruimte blijft om onverwachte moleculen te ontdekken die nog niet in enige referentie staan. Naarmate AI-modellen en datasets blijven verbeteren, zou dit soort geïntegreerd genomisch en metabolomisch redeneren enorme delen van de microbiële chemie kunnen ontsluiten die nog onontgonnen zijn, mogelijk het onthullen van nieuwe antibiotica en andere nuttige verbindingen precies wanneer de samenleving ze het meest nodig heeft.
Bronvermelding: Tay, D.W.P., Koh, W., Ang, S.J. et al. Accelerating natural product discovery with linked MS-genomics and language/transformer-based models. npj Antimicrob Resist 4, 31 (2026). https://doi.org/10.1038/s44259-026-00206-7
Trefwoorden: ontdekking van natuurstoffen, microbiële metabolieten, massaspectrometrie, eiwit-taalmodellen, AI in geneesmiddelenontwikkeling