Clear Sky Science · fr
Accélérer la découverte de produits naturels grâce à la mise en relation SM‑génomique et aux modèles linguistiques/transformers
Pourquoi de nouveaux médicaments se cachent à découvert
Beaucoup de nos médicaments les plus importants, notamment des antibiotiques et des traitements anticancéreux, proviennent de micro‑organismes minuscules qui produisent des molécules naturelles complexes. Pourtant, repérer de nouveaux composés dans cette pharmacie cachée est lent et coûteux, car les chercheurs doivent trier d’immenses bibliothèques de microbes et deviner lesquels méritent d’être testés. Cet article montre comment la combinaison d’une intelligence artificielle avancée et de mesures expérimentales modernes peut considérablement accélérer la recherche, en aidant les équipes à cibler les souches les plus prometteuses avant d’entreprendre des expériences fastidieuses. 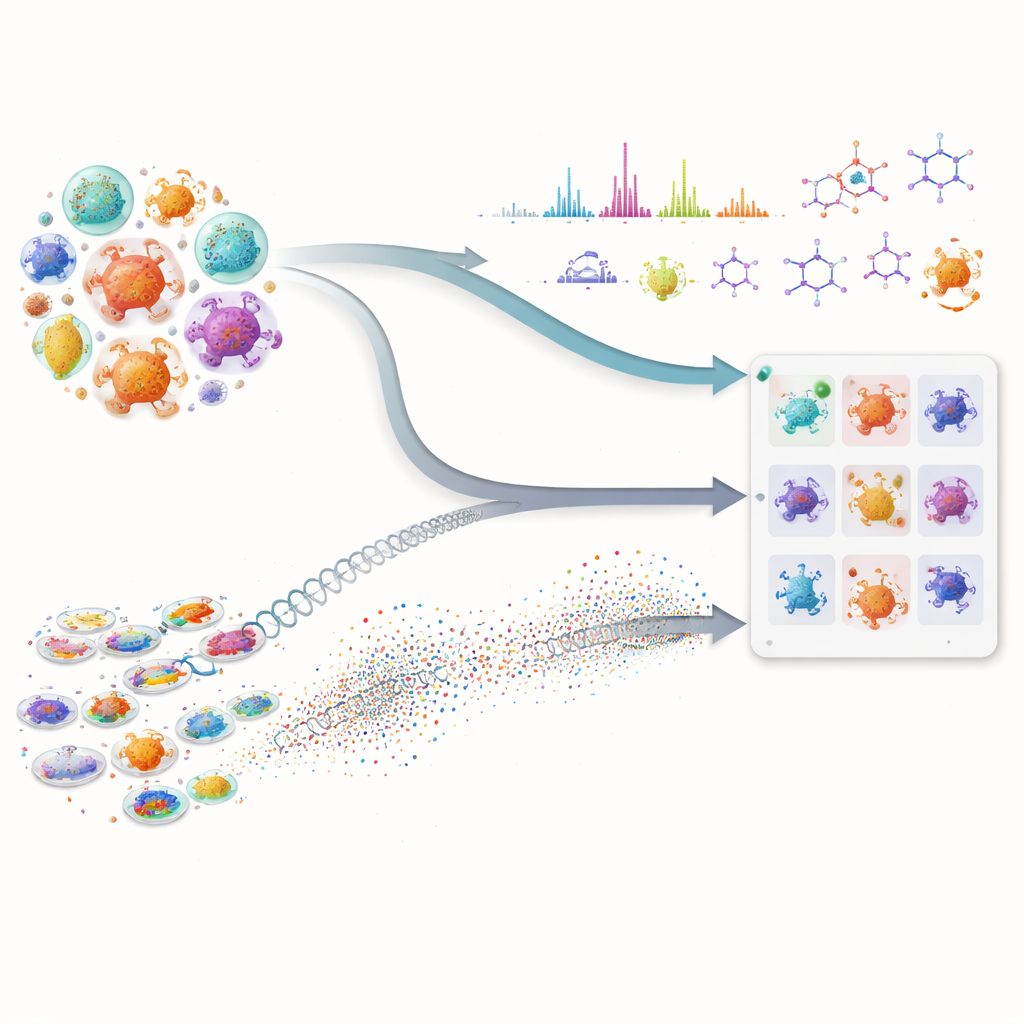
Transformer l’ADN microbien en carte consultable
La première partie de l’approche analyse les « plans » génétiques des microbes. Plutôt que de se limiter au seul appariement d’ADN traditionnel, l’équipe utilise des modèles linguistiques protéiques puissants — des systèmes d’IA ayant appris des motifs à partir de millions de séquences protéiques. Ces modèles convertissent chaque protéine biosynthétique en une empreinte numérique haute‑dimensionnelle. Cela permet de détecter des cousins fonctionnels lointains même lorsque l’ADN sous‑jacent a beaucoup changé ou est fragmenté, un problème courant avec des génomes en brouillon. Les chercheurs attribuent ensuite à chaque microbe un score fondé sur le nombre de ses protéines ressemblant à celles d’une voie connue de biosynthèse d’une molécule cible, et sur l’intensité globale de cette similarité. Ce score composite met en évidence des souches dont l’ensemble protéique semble capable de construire le composé souhaité, tout en écartant les microbes qui ne possèdent qu’une ou deux enzymes communes et non spécialisées.
Lire des mélanges chimiques complexes avec l’IA
La deuxième partie se concentre sur ce que les microbes produisent réellement en laboratoire. À l’aide de chromatographie liquide et de spectrométrie de masse en tandem, les scientifiques enregistrent des « empreintes » détaillées des molécules présentes dans les bouillons de fermentation. Le Workflow interne pour l’Élucidation Structurale Intelligente, ou WISE, nettoie ces signaux, sépare les pics qui se chevauchent, puis utilise des modèles d’IA entraînés sur des millions de structures de type produit naturel pour deviner quelles formes moléculaires correspondent le mieux à chaque spectre. Un modèle basé sur des transformers prédit à quoi devraient ressembler les spectres de molécules candidates, et un score combiné évalue dans quelle mesure les schémas observés et prédits s’alignent, en intégrant des détails fins comme les patrons isotopiques et la masse exacte. En analysant la distribution de ces scores sur une référence standard, l’équipe identifie des seuils qui distinguent les appariements vraisemblables du bruit ou des leurres ressemblants, leur permettant de qualifier certaines propositions structurales de haute confiance et d’éliminer les évidentes erreurs.
Réunir gènes et produits chimiques
La vraie puissance de la méthode vient de la fusion de ces deux sources d’information. Pour qu’un microbe remonte en tête de liste pour une molécule d’intérêt, il doit montrer à la fois un potentiel génétique — ses protéines ressemblent à celles d’une voie connue — et une preuve chimique — il produit des caractéristiques spectrales compatibles avec la structure attendue. Cette vérification croisée réduit les fausses pistes qui semblent convaincantes dans un seul type de données. Les auteurs ont testé leur cadre sur une grande collection de souches et mutants actinobactériens, en se concentrant sur trois composés antimicrobiens très différents : la valinomycine, la surfactine et l’antibiotique néomycine B. Plutôt que de s’appuyer sur des génomes parfaits ou des bibliothèques spectrales complètes, le système fonctionne bien même lorsque les données sont désordonnées ou incomplètes, une réalité fréquente dans les campagnes de découverte en phase initiale. 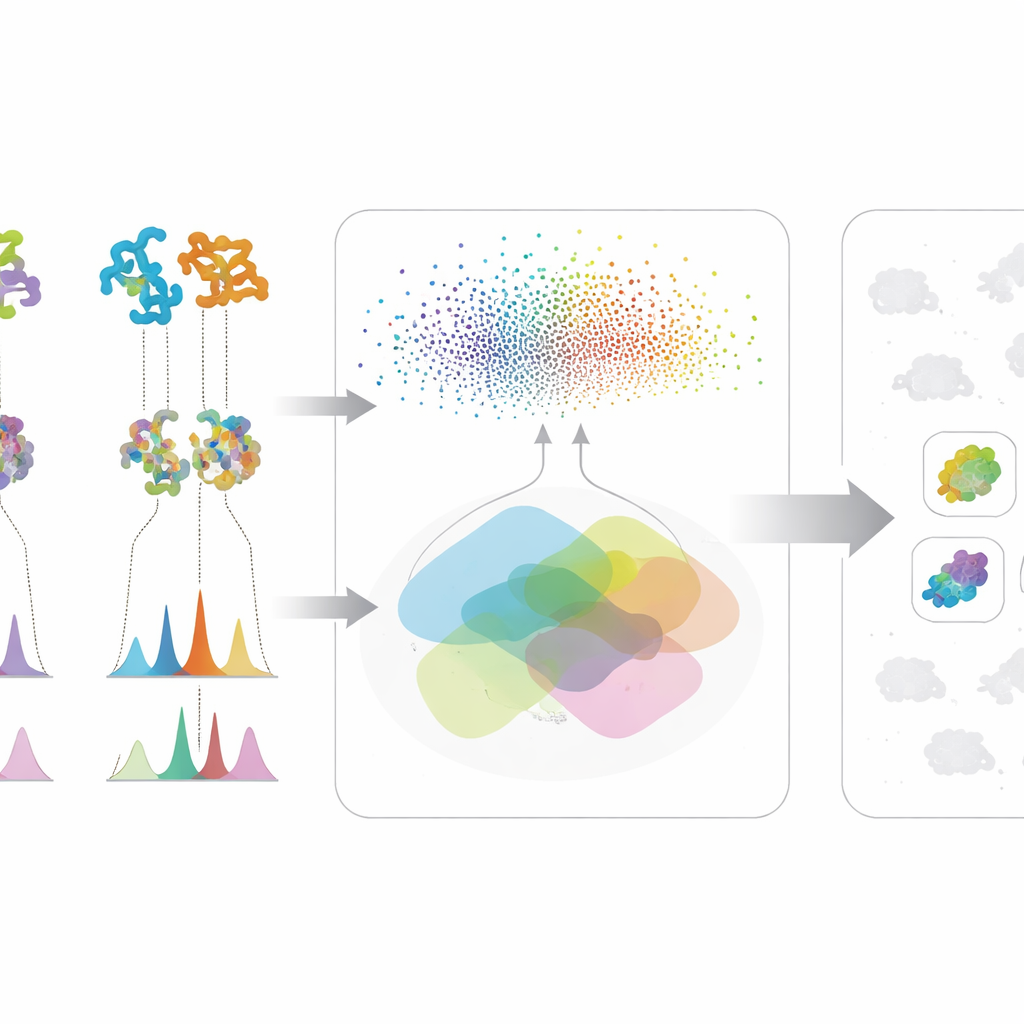
Mettre le cadre à l’épreuve
Dans l’étude de cas sur la néomycine B, l’IA a d’abord recherché des microbes dont les protéines ressemblaient à celles de la voie connue de néomycine, puis a vérifié si leurs spectres de masse laissaient entrevoir des molécules de type néomycine. Quatre souches ont passé les deux filtres ; trois d’entre elles ont été confirmées expérimentalement comme productrices de néomycine B, dont deux productrices jusque‑là non reconnues. Pour la valinomycine et la surfactine, le cadre a également identifié des producteurs avec une grande précision, tandis qu’un test de contrôle où les scores étaient mélangés au hasard donnait des performances bien moindres. Ces résultats montrent que le modèle capture de véritables relations biologiques, et non de simples coïncidences aléatoires dans les données, et qu’il peut efficacement orienter les chercheurs vers les candidats les plus probables dans un espace de recherche encombré.
Ce que cela signifie pour la découverte de médicaments à venir
En termes simples, les auteurs ont construit un moteur de recommandations intelligent pour la découverte de produits naturels. Plutôt que de tester chaque microbe et chaque signal chimique par force brute, les scientifiques peuvent désormais se concentrer sur une courte liste de souches où potentiel génétique et production chimique concordent. Cela réduit fortement le travail perdu, tout en laissant la possibilité de découvrir des molécules inattendues qui ne figurent encore dans aucun ouvrage de référence. À mesure que les modèles d’IA et les jeux de données s’amélioreront, ce type de raisonnement intégré génomique–métabolomique pourrait ouvrir d’immenses régions de la chimie microbienne encore inexplorées, révélant potentiellement de nouveaux antibiotiques et autres composés utiles au moment où la société en a le plus besoin.
Citation: Tay, D.W.P., Koh, W., Ang, S.J. et al. Accelerating natural product discovery with linked MS-genomics and language/transformer-based models. npj Antimicrob Resist 4, 31 (2026). https://doi.org/10.1038/s44259-026-00206-7
Mots-clés: découverte de produits naturels, métabolites microbiens, spectrométrie de masse, modèles linguistiques protéiques, IA dans la découverte de médicaments