Clear Sky Science · sv
Påskynda upptäckten av naturprodukter med länkad MS-genomik och språk-/transformermodeller
Varför nya läkemedel döljer sig mitt ibland oss
Många av våra viktigaste läkemedel, inklusive antibiotika och cancerläkemedel, kommer från mikroskopiska mikrober som tillverkar komplexa naturliga kemikalier. Att hitta nya molekyler i detta dolda apotek är dock långsamt och kostsamt, eftersom forskare måste sålla genom stora bibliotek av mikrober och försöka avgöra vilka som är värda att testa. Denna artikel visar hur kombinationen av avancerad artificiell intelligens och moderna laboratoriemätningar kraftigt kan påskynda sökandet, genom att hjälpa forskare att rikta in sig på de mest lovande mikroberna innan de utför arbetskrävande experiment. 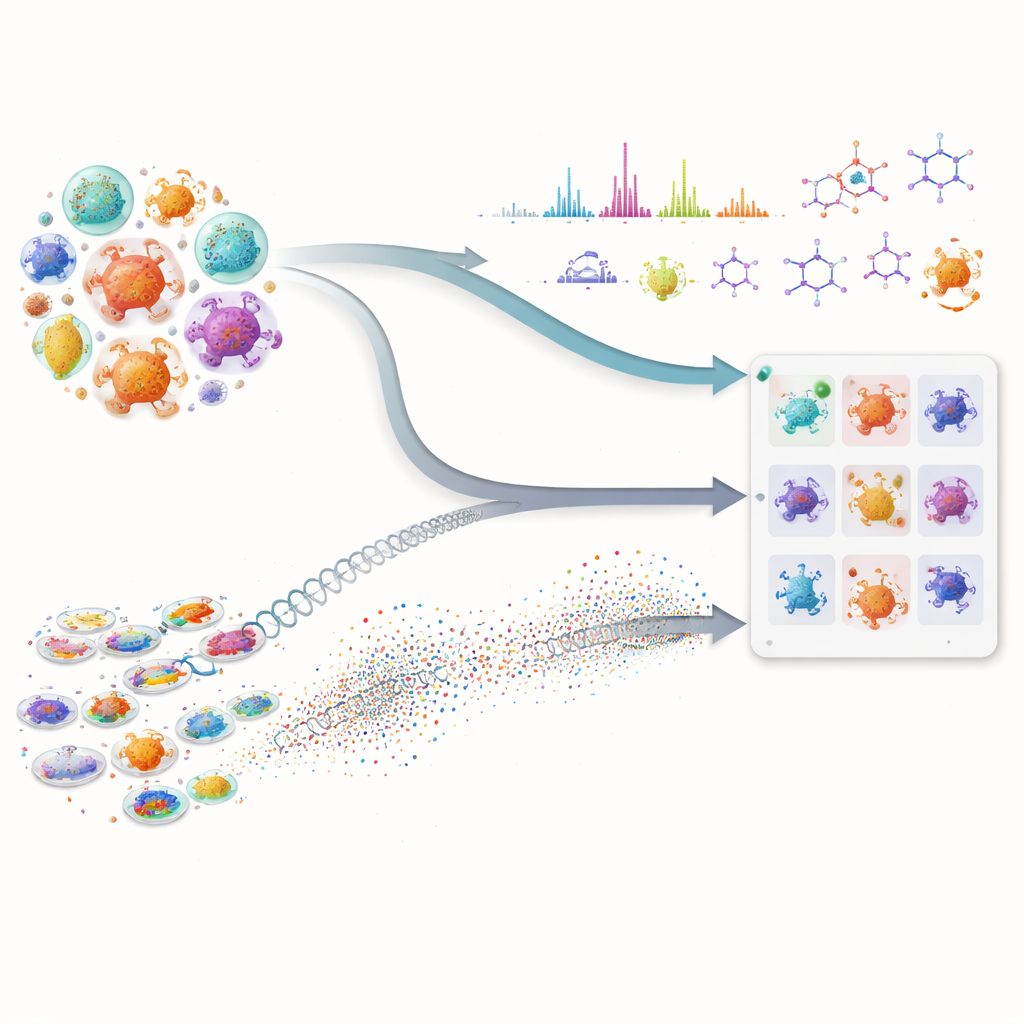
Gör mikrobers DNA till en sökbar karta
Den första delen av tillvägagångssättet undersöker mikrobers genetiska ”ritningar”. Istället för att endast använda traditionell DNA-jämförelse tillämpar teamet kraftfulla protein-språkmodeller — AI-system som lärt sig mönster från miljontals proteinsekvenser. Dessa modeller omvandlar varje biosyntetiskt protein till ett högdimensionellt numeriskt fingeravtryck. Det gör det möjligt för forskare att upptäcka avlägsna funktionella släktingar även när den underliggande DNA-sekvensen har förändrats mycket eller är uppdelad i fragment, ett vanligt problem med ofullständiga genomer. Forskarna poängsätter sedan varje mikroorganism efter hur många av dess proteiner som liknar dem i en känd väg för att bygga en målmolekyl, och efter hur stark den totala likheten är. Denna sammansatta poäng lyfter fram stammar vars samlade uppsättning proteiner ser ut att kunna bygga den önskade föreningen, samtidigt som mikrober som endast har en eller två vanliga, icke-specialiserade enzymer får lägre prioritet.
Läsa komplexa kemiska blandningar med AI
Den andra delen fokuserar på vad mikroberna faktiskt producerar i laboratoriet. Med hjälp av vätskekromatografi och tandem-masspektrometri registrerar forskare detaljerade ”fingeravtryck” av molekylerna i fermentationsbuljonger. Författarnas interna arbetsflöde för intelligent strukturelucidation, WISE, rensar upp dessa signaler, separerar överlappande toppar och använder sedan AI-modeller tränade på miljontals naturproduktliknande strukturer för att gissa vilka molekylformer som bäst matchar varje spektrum. En transformerbaserad modell förutspår hur spektrumen för kandidatmolekyler bör se ut, och en kombinerad poäng väger hur väl observerade och förutsagda mönster överensstämmer, inklusive finare detaljer som isotopmönster och exakt massa. Genom att analysera hur dessa poäng fördelar sig på en standardiserad referensidentifierare bestämmer teamet tröskelvärden som skiljer troliga riktiga träffar från brus eller liknande avledare, vilket låter dem klassificera vissa strukturella gissningar som högkonfidenta och filtrera bort uppenbart felaktiga.
Koppla samman gener och kemikalier
Metodens verkliga styrka kommer från att slå samman dessa två informationsströmmar. För en given molekyl i fokus kommer en mikroorganism upp högt på listan endast om den visar både genetisk potential — dess proteiner liknar dem i en känd biosyntetisk väg — och kemiska bevis — den producerar spektrala egenskaper som stämmer med den förväntade strukturen. Denna korskontroll minskar felspår som ser övertygande ut baserat på bara en datatyp. Författarna testade sin ram på en stor samling aktinobakteriestammar och mutanter, med fokus på tre mycket olika antimikrobiella föreningar: valinomyciner, surfaktiner och antibiotikumet neomycin B. Istället för att förlita sig på perfekta genomer eller fullständiga spektralbibliotek fungerar systemet väl även när data är röriga eller ofullständiga, vilket är vanligt i tidiga upptäcktskampanjer. 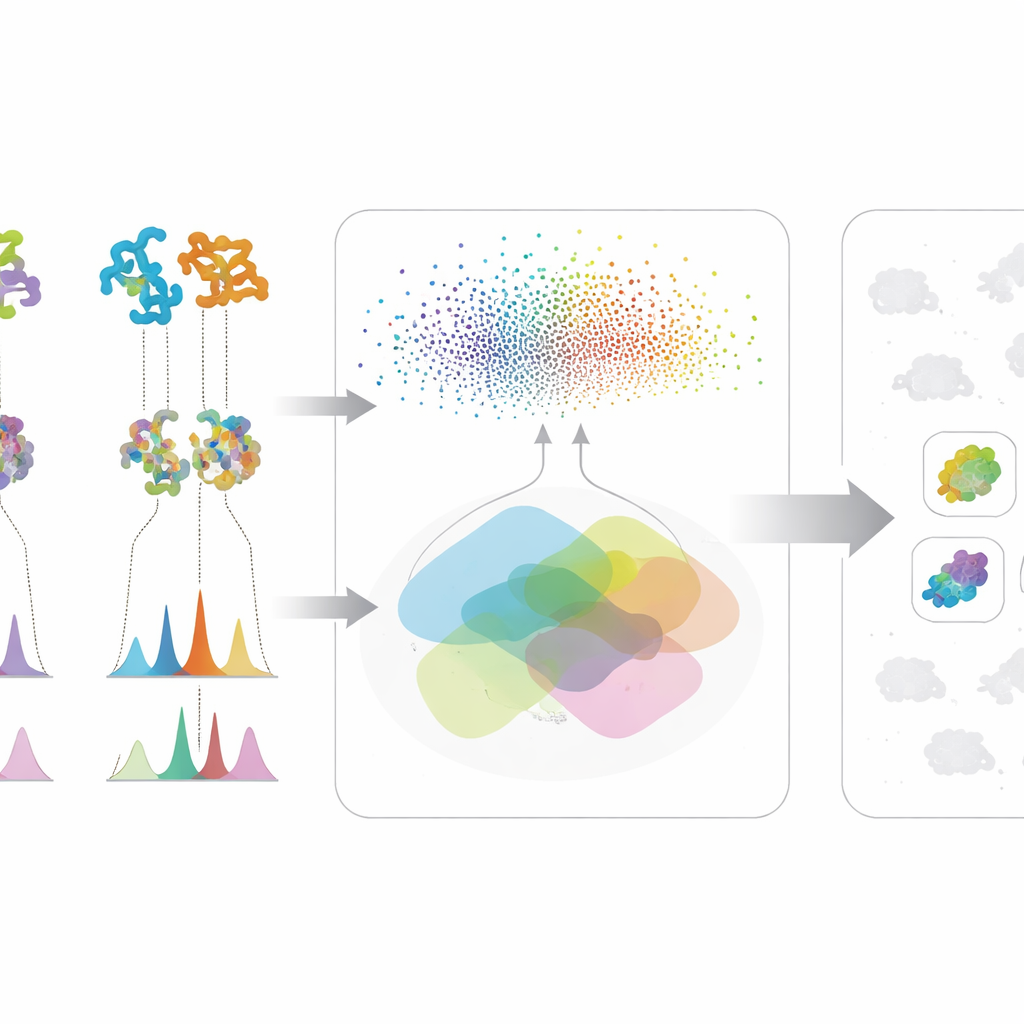
Sätta ramverket på prov
I neomycin B-fallstudien sökte AI:n först efter mikrober vars proteiner liknade dem i den kända neomycinvägen och kontrollerade sedan om deras masspektrum antydde närvaro av neomycinlika molekyler. Fyra stammar klarade båda filtren; tre av dem bekräftades experimentellt som producenter av neomycin B, inklusive två tidigare oerkända producenter. För valinomyciner och surfaktiner identifierade ramverket också producenter med hög precision, medan ett kontrolltest som slumpmässigt blandade poängen presterade mycket sämre. Dessa resultat visar att modellen fångar verkliga biologiska samband, inte bara slumpmässiga sammanträffanden i data, och att den framgångsrikt kan vägleda forskare mot de mest sannolika träffarna i ett tätt sökområde.
Vad detta betyder för framtidens läkemedelsupptäckt
I vardagliga termer har författarna byggt en smart rekommendationsmotor för upptäckt av naturprodukter. Istället för att testa varje mikroorganism och varje kemisk signal med brutalkraft kan forskare nu fokusera på en kort lista med stammar där genetisk potential och kemiskt utflöde överensstämmer. Detta minskar avsevärt slöseri med arbete, samtidigt som det fortfarande lämnar utrymme att upptäcka oväntade molekyler som ännu inte finns i någon referensbok. Allteftersom AI-modeller och datamängder förbättras kan denna typ av integrerat genomiskt och metabolomiskt resonemang låsa upp stora områden av mikrobiell kemi som fortfarande är outforskade, och potentiellt avslöja nya antibiotika och andra användbara föreningar just när samhället behöver dem som mest.
Citering: Tay, D.W.P., Koh, W., Ang, S.J. et al. Accelerating natural product discovery with linked MS-genomics and language/transformer-based models. npj Antimicrob Resist 4, 31 (2026). https://doi.org/10.1038/s44259-026-00206-7
Nyckelord: upptäckt av naturprodukter, mikrobiella metaboliter, masspektrometri, protein-språkmodeller, AI i läkemedelsupptäckt