Clear Sky Science · zh
优化 DNA 甲基化参考面板以实现细胞类型解卷积的指南
窥视混合组织内部
现代的健康与疾病研究经常测量附着在 DNA 上的化学标记,以期观察环境和生活方式如何在基因上留下痕迹。但大多数检测是在像血液这样的混合组织中进行的,血液包含多种不同类型的细胞。如果无法确定每种细胞类型的丰度,我们可能会将细胞组成的变化误认为是真正的疾病信号。本文解释了如何构建更好的“参考面板”,使科学家能够从 DNA 甲基化数据中准确估计细胞混合比例,从而得到更清晰、更可信的结果。 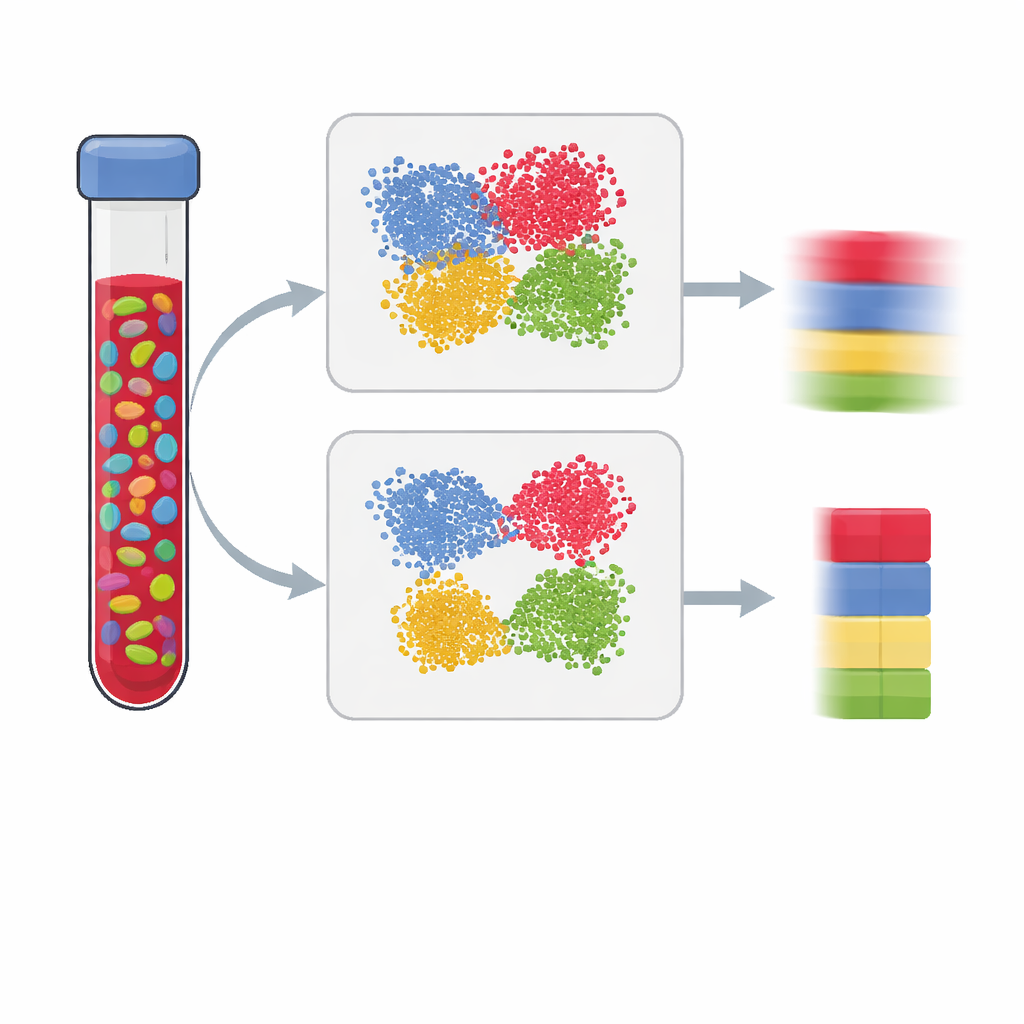
为何细胞混合很重要
全基因组表观关联研究(epigenome-wide association studies)寻找 DNA 甲基化——这些帮助调控基因活性的微小化学标记——在有某种性状(如疾病)的人与无该性状的人之间的差异。由于甲基化模式在不同细胞类型间差异很大,在整体血样中测量可能产生误导:一种免疫细胞类型向另一种的比例变化,可能会模拟出疾病效应,即使各细胞类型内并无真正变化。为纠正这种情况,研究者使用由纯化细胞或单细胞构建的参考面板来估计主要细胞类型(例如 T 细胞、B 细胞和自然杀伤细胞)的比例。参考面板的质量在很大程度上决定了我们能多好地“解混”样本,从而影响研究结论的可靠性。
从简单统计到更智能的标记
传统上,科学家使用标准统计检验从 DNA 位点中挑选面板标记。他们寻找在某一细胞类型与所有其他类型之间显著不同的位置,并按 t 统计量对其排序。近年来,诸如 IDOL、弹性网(Elastic Net)和随机森林等优化与机器学习方法被用于改进这些选择。新研究表明,这些方法常常优先选择在细胞类型间实际差异较小的标记,尤其当纯化样本数量有限时。此类“低效应量”标记在训练数据中可能看起来可信,但在新数据集中表现不佳,微妙地降低了细胞类型估计的准确性。
寻找细胞类型之间的清晰间隔
作者提出了一种更直接评估标记有用性的方法:一种“间隔特异性评分”。该评分不只关注统计显著性,而是通过比较目标细胞中最高值与所有其他细胞中最低值之间的差距(或对低值取相反处理)来衡量某一 DNA 位点将一种细胞类型与其他类型区分开的清晰程度。具有大正间隔的标记既具特异性又更稳健。使用现有的免疫细胞数据,研究者展示了按此评分排序时得到的 DNA 位点在细胞类型间的差异远大于传统方法。由这些基于间隔的标记构建的面板在多个免疫亚群上产生了更准确的细胞比例估计,尤其是在像记忆性 CD4 T 细胞这样更难区分的群体上。 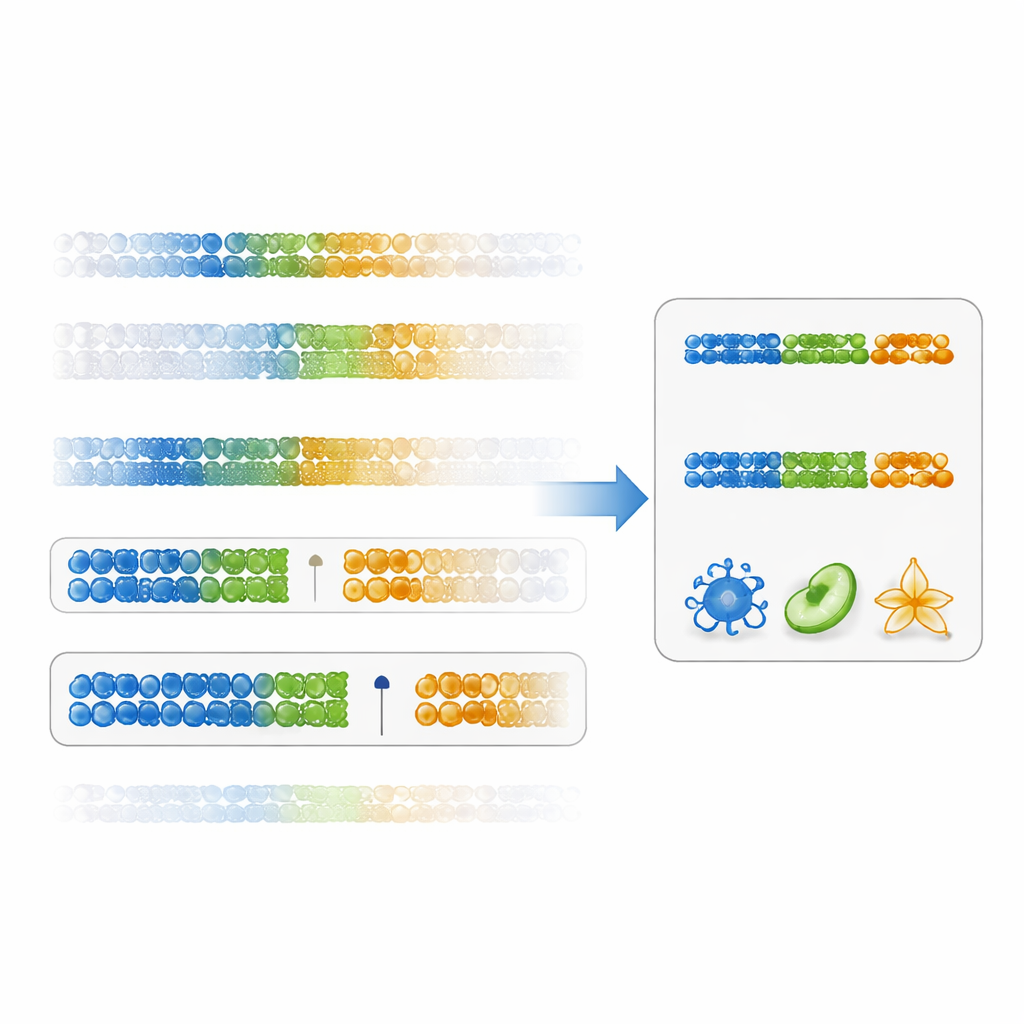
低效应量与过拟合为何有害
团队还测试了先进的优化工具或机器学习模型是否能改进他们的间隔法。结果却相反。像 IDOL、弹性网和随机森林这类方法倾向于选择效应量更小的特征,并且在独立混合样本或有已知细胞计数的真实血样上表现更差。这表明,当训练样本仅有几十个时,复杂模型更容易过拟合数据的特异性噪音,而非捕捉普遍模式。相反,仅由具有高间隔评分的强低甲基化标记构建的面板,不仅提高了解卷积精度,还更好地捕捉已知的生物学趋势,例如随年龄增长自然杀伤细胞的上升。
更好的面板带来更清晰的疾病信号
为展示这些改进在实践中的效果,作者重新分析了大型的精神分裂症和1型糖尿病研究。使用他们优化过的参考面板对估计的细胞比例的改变都很小,但这些微小变化使下游结果更为清晰。与疾病相关的甲基化改变在已与炎症和自身免疫相关的通路中变得更富集,且与免疫信号相关的特定基因更加突出。换言之,更佳的标记选择减少了噪音,使生物学解释更连贯。
这对未来研究的意义
对非专业读者来说,关键信息是并非所有统计学显著的信号都同样有用。在试图拆解混合组织时,最重要的是标记在多大程度上将一种细胞类型与另一种区分开,而不仅仅是其 P 值有多显眼。通过优先选择在细胞类型间具有大且清晰间隔的 DNA 位点——尤其是那些在某类细胞中独特去甲基化的位点——研究者即使在小型数据集中也能构建出更可靠的参考面板。作者已将构建此类面板的工具加入到 EpiDISH 软件中,帮助未来的研究从 DNA 甲基化数据中得出更准确、更具生物学意义的结论。
引用: Guo, X., Teschendorff, A.E. Guidelines on optimizing DNA methylation reference panels for cell-type deconvolution. Commun Biol 9, 454 (2026). https://doi.org/10.1038/s42003-026-09745-1
关键词: DNA 甲基化, 细胞类型解卷积, 表观基因组学, 免疫细胞, 参考面板