Clear Sky Science · fr
Lignes directrices pour optimiser les panneaux de référence de méthylation de l’ADN pour la déconvolution des types cellulaires
Regarder à l’intérieur des tissus mixtes
Les études modernes sur la santé et la maladie mesurent souvent des marques chimiques sur notre ADN pour comprendre comment l’environnement et le mode de vie influent sur nos gènes. Mais la plupart des analyses portent sur des tissus mixtes, comme le sang, qui contiennent de nombreux types cellulaires. Si l’on ne peut pas déterminer la proportion de chaque type cellulaire, on risque de confondre un changement de composition cellulaire avec un véritable signal de maladie. Cet article explique comment construire de meilleurs « panneaux de référence » permettant d’estimer avec précision les mélanges cellulaires à partir de données de méthylation de l’ADN, ce qui conduit à des résultats plus clairs et plus fiables. 
Pourquoi la composition cellulaire compte
Les études d’association épigénomique à l’échelle du génome recherchent des différences de méthylation de l’ADN — l’ajout de petites marques chimiques qui contribuent à réguler l’activité des gènes — entre des personnes avec ou sans un trait, comme une maladie. Parce que les profils de méthylation varient fortement d’un type cellulaire à l’autre, les mesurer sur un échantillon en vrac peut induire en erreur : un déplacement entre deux types de cellules immunitaires peut imiter un effet de maladie même si rien n’a changé au sein de chaque type cellulaire. Pour corriger cela, les chercheurs estiment les fractions des principaux types cellulaires (par exemple lymphocytes T, lymphocytes B et cellules NK) en se basant sur un panneau de référence construit à partir de cellules purifiées ou de cellules uniques. La qualité de ce panneau détermine en grande partie notre capacité à « démêler » un échantillon et, par conséquent, la fiabilité des conclusions de l’étude.
Des statistiques simples à des marqueurs plus pertinents
Traditionnellement, les scientifiques sélectionnaient des sites d’ADN pour ces panneaux en utilisant des tests statistiques standard. Ils cherchaient des positions où un type cellulaire différait de façon significative de tous les autres et les classaient selon une statistique t. Plus récemment, des méthodes d’optimisation et d’apprentissage automatique telles qu’IDOL, Elastic Net et Random Forest ont été utilisées pour affiner ces choix. La nouvelle étude montre que ces approches privilégient souvent des marqueurs présentant de faibles différences réelles entre types cellulaires, surtout lorsque seules quelques quelques échantillons purifiés sont disponibles. De tels marqueurs à « faible taille d’effet » peuvent sembler convaincants sur les données d’entraînement mais échouer sur de nouveaux jeux de données, dégradant subtilement la précision des estimations de types cellulaires.
Trouver des écarts nets entre types cellulaires
Les auteurs proposent une façon plus directe d’évaluer l’utilité d’un marqueur : un « score de spécificité par écart ». Plutôt que de ne se concentrer que sur la significativité statistique, ce score mesure la netteté avec laquelle un site d’ADN sépare un type cellulaire de tous les autres, en examinant l’écart entre la valeur la plus élevée dans le type cible et la valeur la plus basse dans l’ensemble des autres cellules (ou l’inverse pour les valeurs faibles). Les marqueurs présentant de grands écarts positifs sont à la fois spécifiques et robustes. En utilisant des données existantes sur les cellules immunitaires, les chercheurs ont montré que classer les marqueurs selon ce score conduit à des sites d’ADN avec des différences beaucoup plus marquées entre types cellulaires que la méthode traditionnelle. Les panneaux construits à partir de ces marqueurs fondés sur l’écart ont produit des estimations de fractions cellulaires plus précises sur de nombreux sous-ensembles immunitaires, en particulier pour des populations difficiles à distinguer comme les cellules T CD4 mémoire. 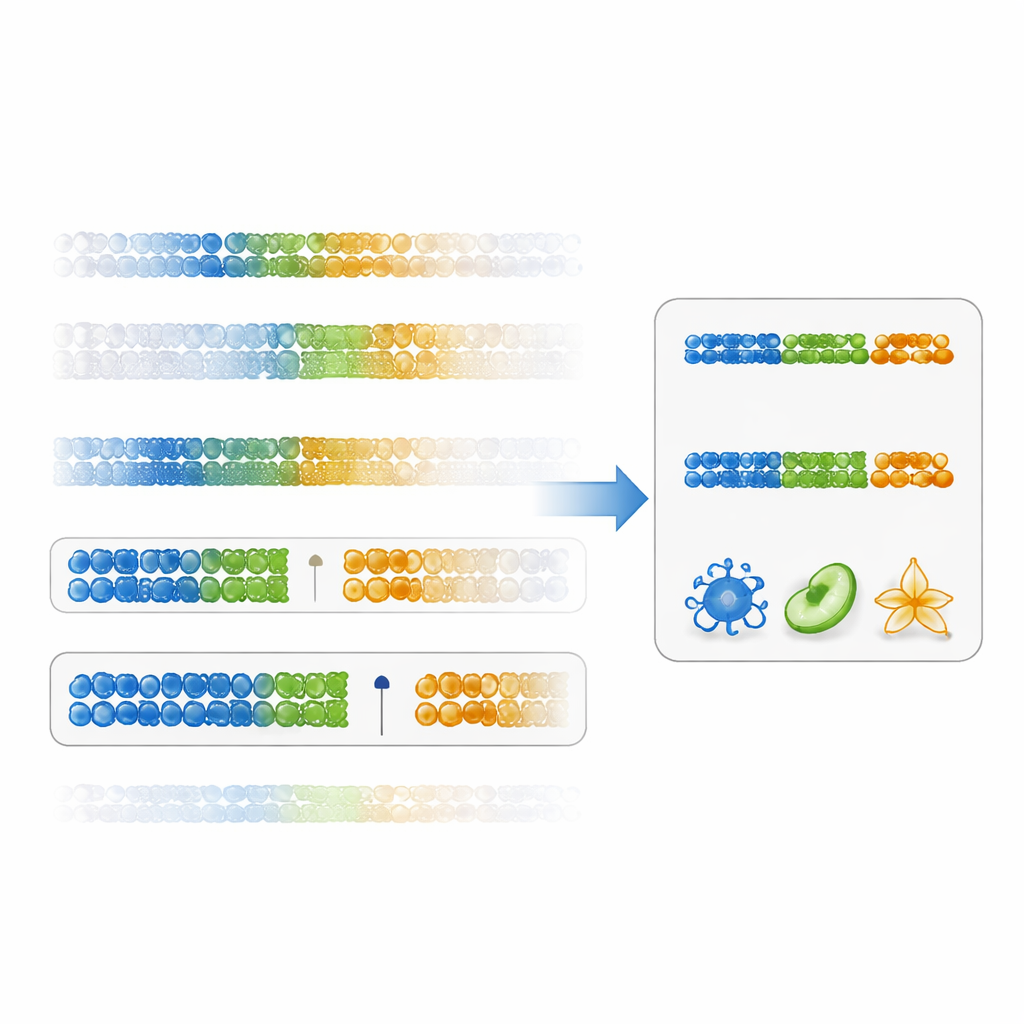
Pourquoi les faibles signaux et le surapprentissage nuisent
L’équipe a également testé si des outils d’optimisation avancés ou des modèles d’apprentissage automatique pouvaient améliorer leur approche basée sur l’écart. Ils ont trouvé l’effet inverse. Des méthodes comme IDOL, Elastic Net et Random Forest avaient tendance à sélectionner des caractéristiques avec des tailles d’effet plus faibles et obtenaient de moins bons résultats quand on les évaluait sur des mélanges indépendants ou sur des échantillons sanguins réels avec des comptages cellulaires connus. Cela suggère qu’avec seulement quelques dizaines d’échantillons d’entraînement, les modèles complexes surapprennent des particularités des données au lieu de capter des schémas généraux. En revanche, des panneaux construits uniquement à partir de marqueurs fortement hypométhylés avec des scores d’écart élevés ont non seulement amélioré la précision de la déconvolution mais ont aussi mieux reflété des tendances biologiques connues, comme l’augmentation liée à l’âge des cellules NK.
Des signaux de maladie plus nets grâce à de meilleurs panneaux
Pour montrer l’impact pratique de ces améliorations, les auteurs ont réanalysé de grandes études sur la schizophrénie et le diabète de type 1. L’utilisation de leurs panneaux de référence optimisés a légèrement modifié les fractions cellulaires estimées, mais ces petits décalages ont affiné les résultats en aval. Les changements de méthylation associés à la maladie sont devenus plus enrichis pour des voies impliquées dans l’inflammation et l’auto-immunité, et des gènes spécifiques liés à la signalisation immunitaire sont apparus plus clairement. Autrement dit, une meilleure sélection de marqueurs a réduit le bruit et rendu l’histoire biologique plus cohérente.
Ce que cela signifie pour les études futures
Pour les non-spécialistes, le message clé est que toutes les signatures statistiquement significatives ne sont pas également utiles. Lorsqu’il s’agit de démêler des tissus mixtes, ce qui compte le plus est la clarté avec laquelle un marqueur distingue un type cellulaire d’un autre, et non seulement l’attrait de sa valeur de P. En favorisant des sites d’ADN présentant de grands écarts nets entre types cellulaires — en particulier ceux qui sont spécifiquement déméthylés dans un type donné — les chercheurs peuvent construire des panneaux de référence plus fiables même à partir de petits jeux de données. Les auteurs ont ajouté des outils pour construire de tels panneaux au logiciel EpiDISH, aidant les études futures à tirer des conclusions plus précises et biologiquement significatives à partir des données de méthylation de l’ADN.
Citation: Guo, X., Teschendorff, A.E. Guidelines on optimizing DNA methylation reference panels for cell-type deconvolution. Commun Biol 9, 454 (2026). https://doi.org/10.1038/s42003-026-09745-1
Mots-clés: Méthylation de l’ADN, déconvolution des types cellulaires, épigénomique, cellules immunitaires, panneaux de référence