Clear Sky Science · ru
Рекомендации по оптимизации эталонных панелей метилирования ДНК для деконволюции типов клеток
Заглядывая внутрь смешанных тканей
Современные исследования здоровья и болезней часто измеряют химические метки на нашей ДНК, стремясь понять, как среда и образ жизни оставляют следы на генах. Но большинство анализов проводят на смешанных тканях, например крови, которые содержат множество типов клеток. Если мы не можем определить долю каждого типа клеток, мы можем принять изменение в составе клеток за истинный сигнал заболевания. В этой статье объясняется, как создавать лучшие «эталонные панели», которые позволяют исследователям точно оценивать состав клеток по данным о метилировании ДНК, что приводит к более ясным и надежным выводам. 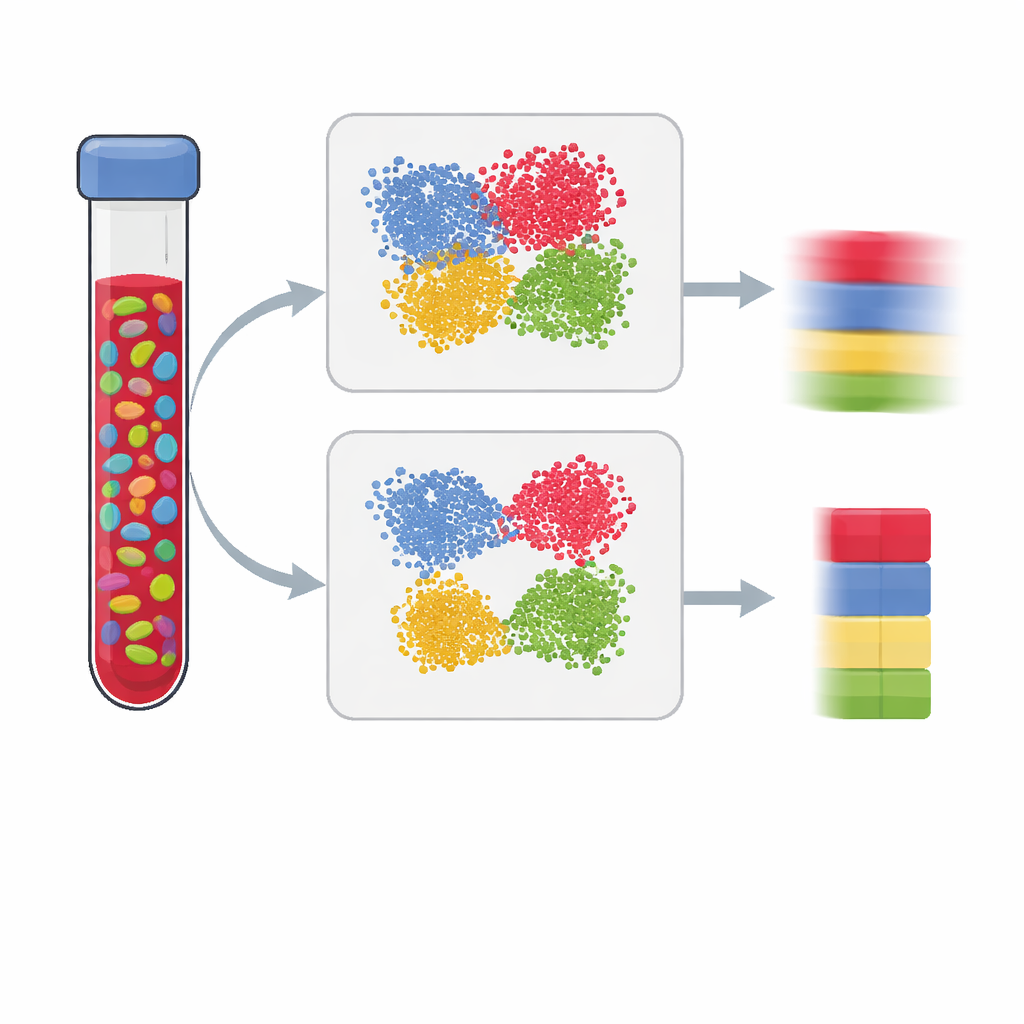
Почему важно соотношение типов клеток
Широкомасштабные эпигеномные исследования сравнивают метилирование ДНК — добавление небольших химических меток, регулирующих активность генов — между людьми с тем или иным признаком, например заболеванием, и без него. Поскольку шаблоны метилирования сильно различаются у разных типов клеток, измерения в цельной крови могут вводить в заблуждение: сдвиг от одного типа иммунных клеток к другому может имитировать эффект болезни, даже если внутри каждого типа ничего не изменилось. Чтобы скорректировать это, исследователи оценивают доли основных типов клеток (например, Т‑ клеток, В‑клеток и натуральных киллеров) с помощью эталонной панели, созданной из очищенных клеток или одиночных клеток. Качество такой панели во многом определяет, насколько хорошо можно «размешать» образец и, следовательно, насколько надежны выводы исследования.
От простых статистик к более умным маркерам
Традиционно учёные выбирали сайты ДНК для таких панелей, используя стандартные статистические тесты. Они искали позиции, где один тип клетки значительно отличался от всех остальных, и ранжировали их по t‑статистике. В последнее время для уточнения выбора стали применять методы оптимизации и машинного обучения, такие как IDOL, Elastic Net и Random Forests. Новое исследование показывает, что эти подходы часто отдают приоритет маркерам с небольшими реальными различиями между типами клеток, особенно при наличии лишь нескольких очищенных образцов. Такие маркеры с «малой величиной эффекта» могут выглядеть убедительно на обучающих данных, но плохо переноситься на новые наборы данных, что незаметно снижает точность оценок долей типов клеток.
Поиск четких разрывов между типами клеток
Авторы предлагают более прямой способ оценить полезность маркера: «оценку специфичности по разрыву». Вместо того чтобы сосредотачиваться только на статистической значимости, эта оценка измеряет, насколько чисто сайт ДНК разделяет один тип клетки от всех остальных, глядя на разницу между наибольшим значением в целевой клетке и наименьшим значением во всех остальных клетках (или наоборот для низких значений). Маркеры с большими положительными разрывами одновременно специфичны и устойчивы. На существующих данных по иммунным клеткам исследователи показали, что ранжирование маркеров по этой оценке даёт сайты ДНК с гораздо более крупными различиями между типами клеток, чем традиционный метод. Панели, построенные на таких маркерах по разрывам, давали более точные оценки долей клеток в различных иммунных подмножествах, особенно для труднодифференцируемых популяций, таких как «памятные» CD4 Т‑клетки. 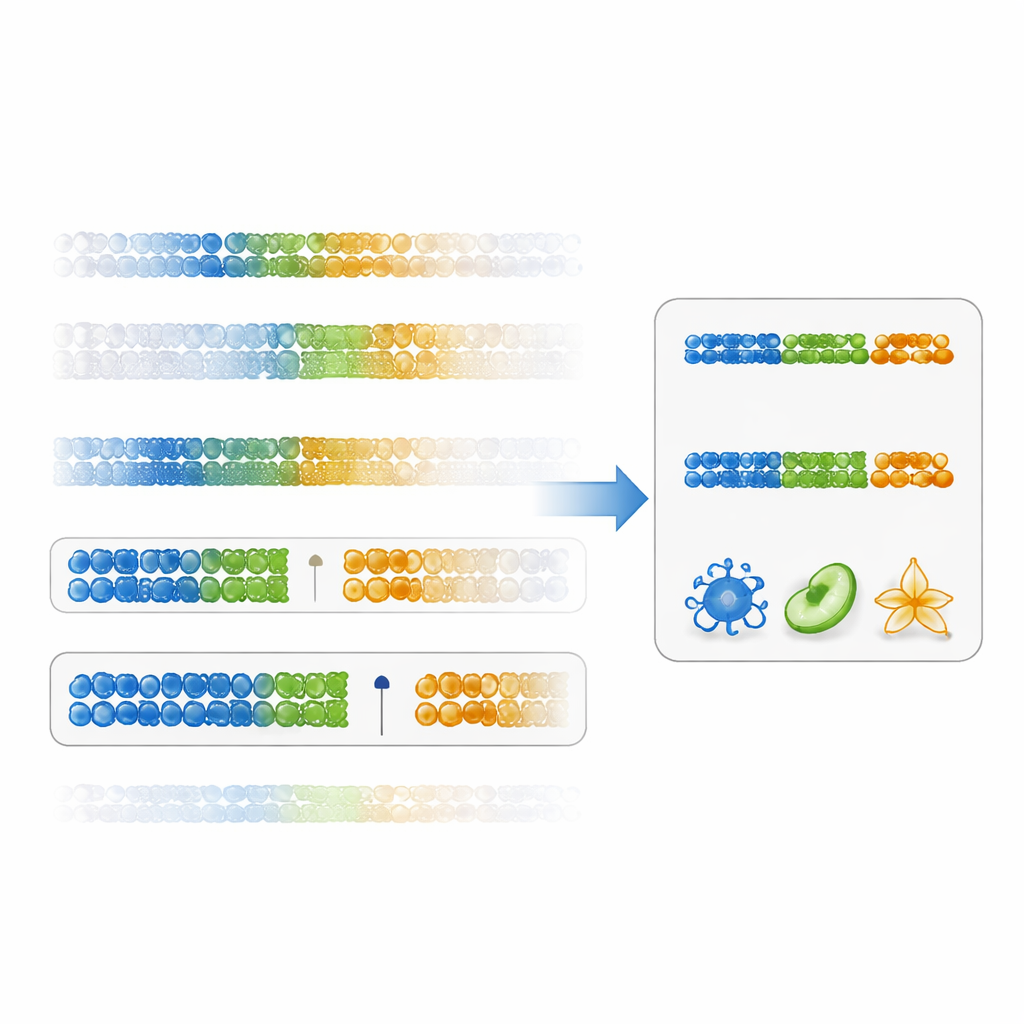
Почему низкие эффекты и переобучение вредят
Команда также проверила, смогут ли сложные инструменты оптимизации или модели машинного обучения превзойти их подход на основе разрывов. Вместо этого они обнаружили обратное. Методы вроде IDOL, Elastic Net и Random Forest склонялись к выбору признаков с меньшими размерами эффекта и показывали худшие результаты при проверке на независимых смесях или на реальных образцах крови с известными подсчётами клеток. Это указывает на то, что при наличии лишь нескольких десятков обучающих образцов сложные модели переобучаются на особенности данных, а не захватывают общие закономерности. Напротив, панели, построенные исключительно из сильно гипометилированных маркеров с высокими значениями разрыва, не только улучшали точность деконволюции, но и лучше отражали известные биологические тенденции, например возрастное увеличение числа натуральных киллеров.
Более ясные сигналы болезни благодаря лучшим панелям
Чтобы увидеть, как эти улучшения сказываются на практике, авторы повторно проанализировали большие исследования шизофрении и сахарного диабета 1 типа. Использование их оптимизированных эталонных панелей лишь немного изменило оценочные доли клеток, но эти небольшие сдвиги обострили последующие выводы. Изменения метилирования, связанные с болезнью, стали более обогащёнными для путей, уже связанных с воспалением и аутоиммунитетом, и конкретные гены, участвующие в иммунной сигнализации, проявились яснее. Иными словами, более тонкий отбор маркеров снизил шум и сделал биологическую картину более согласованной.
Что это значит для будущих исследований
Для неспециалистов ключевое послание таково: не все статистически значимые сигналы одинаково полезны. При попытке распутать смешанные ткани важнее то, насколько чётко маркер отличает один тип клетки от другого, а не только впечатляет ли его P‑значение. Отдавая предпочтение сайтам ДНК с большими, чистыми разрывами между типами клеток — особенно тем, которые уникально деметилированы в данном типе — исследователи могут создавать более надёжные эталонные панели даже на основе небольших наборов данных. Авторы добавили инструменты для конструирования таких панелей в программное обеспечение EpiDISH, что поможет будущим исследованиям делать более точные и биологически значимые выводы из данных о метилировании ДНК.
Цитирование: Guo, X., Teschendorff, A.E. Guidelines on optimizing DNA methylation reference panels for cell-type deconvolution. Commun Biol 9, 454 (2026). https://doi.org/10.1038/s42003-026-09745-1
Ключевые слова: Метилирование ДНК, деконволюция типов клеток, эпигеномика, иммунные клетки, эталонные панели