Clear Sky Science · zh
通过基于图的样本选择与净化缓解网络入侵检测中的标签噪声
为何更干净的标签对网络安全至关重要
每天,安全系统都在监视大量互联网流量,试图在数百万正常连接中找出少数恶意连接。这些系统越来越依赖机器学习,通过过去被标记为“安全”或“攻击”的示例来学习。但如果许多标签是错误的,即便是强大的模型也会被误导,使得网络比表面看起来更脆弱。本文提出了SilentSentinel,一种在训练前清理标签的方法,使入侵检测器能够从值得信赖的数据中学习。
错误标签的隐蔽问题
构建良好的入侵检测系统始于数据,而问题往往从这里出现。为获得“恶意”流量,研究人员常在受控环境中运行恶意软件,并将其产生的所有流量标记为恶意。实际上,这些流量中很多是完全正常的,因此无害的连接被错误地标为攻击。用于自动标注的入侵检测工具在面对新的、前所未见的威胁时也会误判。这些错误造成“标签噪声”,即数据集中许多样本带有错误标签。当噪声很高且攻击样本相对正常流量很少时,标准训练方法会遇到困难:模型开始记忆错误,决策边界朝错误方向偏移,检测精度显著下降。
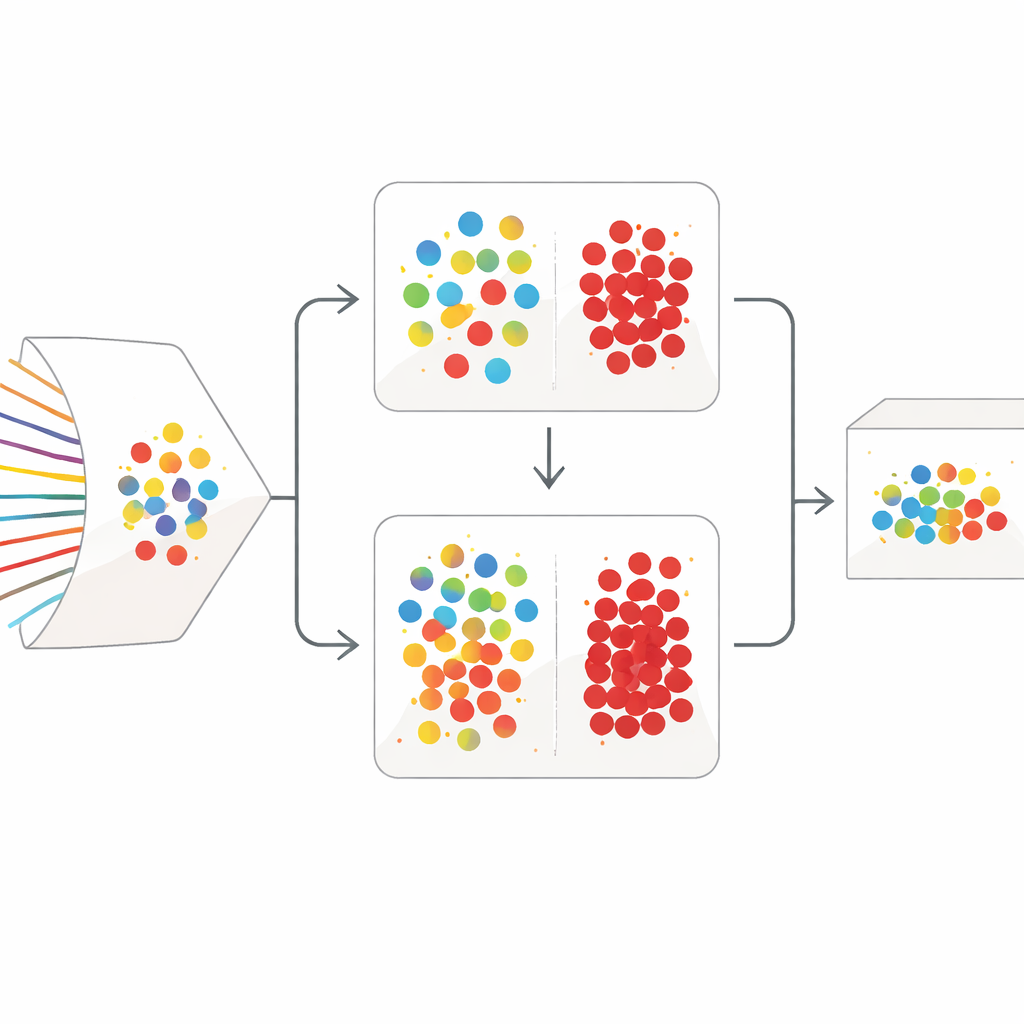
两阶段的清理策略
SilentSentinel通过数据中心的方法来应对这个问题:它不只是试图让模型本身更鲁棒,而是先修正训练数据。关键观察是,来自相同行为的网络流在特征空间中往往表现相似,无论它们是真正正常还是恶意。SilentSentinel的第一个模块称为正常样本发现(NSD),它寻找模型高度自信的流样本,假定这些样本的标签是正确的,然后利用它们的相似性关系为邻近样本重新标注。具体做法是构建一个图,每个点代表一个流,边连接行为相似的流。来自自信核心的标签在图上扩散,只有那些新标签高度一致的样本被保留为“干净”样本。这些样本成为训练的锚点,尤其是对数量众多的正常流量而言。
聚焦稀有攻击样本
真实数据集中正常流量占主导,但真正重要的是那些稀少的、真正的恶意流。第一轮基于图的方法仍会对许多此类样本保持不确定。为此,SilentSentinel加入了第二个模块,恶意样本筛选(MSS)。在这里,两个结构相同但初始化不同的神经网络共同学习。每个网络在每个训练步骤中都选出其认为最可信的样本子集并与另一个网络共享。随着时间推移,这种互相教学聚焦于双方都一致认可的示例,并逐渐筛除可能被误标的样本。一个精心选择的损失函数有助于防止占绝大多数的正常类压制稀缺的攻击样本,从而使最终的恶意样本集既更纯净也更有信息量。
系统的实证检验
作者在两个广泛使用的入侵数据集上评估了SilentSentinel:覆盖多种经典攻击的CIC-IDS2017,以及聚焦于加密的HTTPS上DNS流量(DoHBrw-2020)。他们通过有意翻转大量标签(最多达到40%)来模拟现实情形,并将SilentSentinel与若干主流应对噪声数据的方法进行了比较。在对称与非对称噪声设定下,SilentSentinel在F1分数(精确率与召回率的平衡)上始终表现更好。在更具挑战性的CIC-IDS2017数据上,在高噪声条件下相比最佳竞品提升了超过17%的性能。在DoHBrw上,随着标签噪声增加,它也能将性能保持在接近完美的水平,而竞争方法则明显退化。进一步分析显示,SilentSentinel在最终训练集中留下的错误标注样本远少于现有技术。
对日常安全的意义
对非专业读者而言,结论很直接:如果你用充满错误的示例来教安全系统,它在现实中也会犯错。SilentSentinel像一位细心的编辑,仔细审阅嘈杂的训练数据集,将每个示例与其邻居以及两个独立的“审阅”网络交叉核验,在主训练开始前修正或丢弃可疑条目。通过这样做,它使入侵检测模型能够更清晰地识别正常与恶意流量的真实样貌,即使原始标签不可靠。最终结果是在网络边缘提供更稳定、更可信的防御,即便其学习的数据远非完美,仍能保持良好表现。
引用: Zhao, R., Ding, J., Dong, Q. et al. Mitigating label noise in network intrusion detection via graph-based sample selection and purification. Sci Rep 16, 11674 (2026). https://doi.org/10.1038/s41598-026-45988-y
关键词: 网络入侵检测, 标签噪声, 基于图的学习, 有噪标签, 恶意流量检测