Clear Sky Science · pt
Mitigando ruído de rótulo na detecção de intrusão de redes via seleção e purificação de amostras baseada em grafo
Por que rótulos mais limpos importam para a cibersegurança
Todos os dias, sistemas de segurança monitoram rios de tráfego da internet, tentando identificar as poucas conexões maliciosas escondidas entre milhões de conexões normais. Esses sistemas dependem cada vez mais de aprendizado de máquina, que aprende a partir de exemplos rotulados como “seguro” ou “ataque”. Mas se muitos desses rótulos estiverem errados, mesmo modelos poderosos podem ser enganados, deixando redes mais vulneráveis do que aparentam. Este artigo apresenta o SilentSentinel, um método projetado para limpar esses rótulos antes do treinamento, de modo que os detectores de intrusão aprendam a partir de dados nos quais possam realmente confiar.
O problema oculto dos rótulos incorretos
Construir bons sistemas de detecção de intrusão começa com os dados, e é aí que as coisas dão errado. Para obter tráfego “malicioso”, pesquisadores muitas vezes executam malware em ambientes controlados e rotulam tudo o que ele gera como ruim. Na prática, grande parte desse tráfego é perfeitamente normal, portanto conexões inofensivas são equivocadamente marcadas como ataques. Ferramentas automatizadas de detecção usadas para rotular também podem falhar, especialmente diante de ameaças novas e nunca vistas antes. Esses erros criam um “ruído de rótulo”, uma situação em que muitas amostras em um conjunto de dados têm a etiqueta errada. Quando o ruído é alto e os ataques são raros em comparação ao tráfego normal, métodos de treinamento padrão têm dificuldades: os modelos começam a memorizar erros, suas fronteiras de decisão se deslocam na direção errada e a precisão de detecção cai acentuadamente.
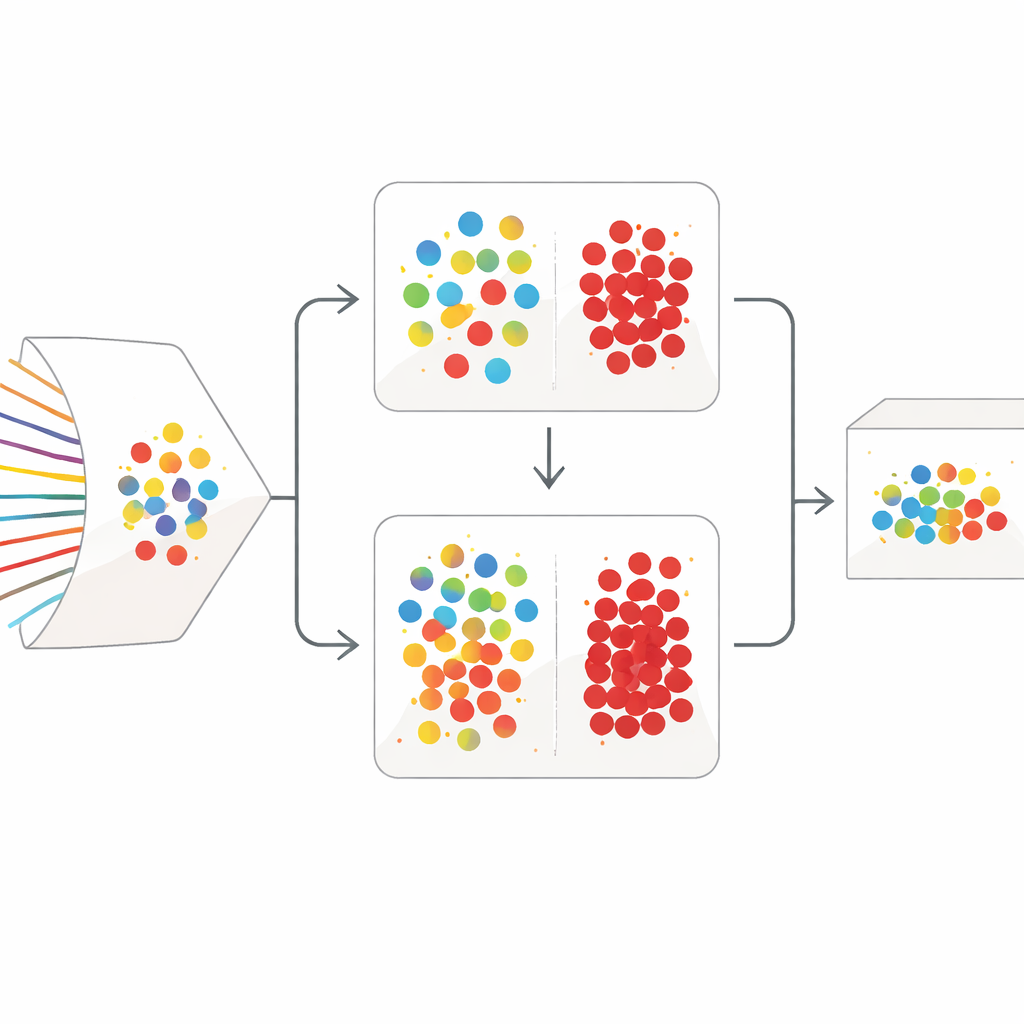
Uma estratégia de limpeza em duas etapas
O SilentSentinel enfrenta esse problema com uma abordagem centrada nos dados: em vez de apenas tentar tornar o modelo mais robusto, ele primeiro trabalha para corrigir os dados de treinamento. A observação-chave é que fluxos de rede originados do mesmo comportamento no mundo real tendem a se parecer em um espaço de características, seja que sejam realmente normais ou realmente maliciosos. O primeiro módulo do SilentSentinel, chamado Descoberta de Amostras Normais (Normal Sample Discovery - NSD), busca amostras de tráfego sobre as quais o modelo está muito confiante, assume que seus rótulos estão corretos e então usa as relações de similaridade para rótular novamente seus vizinhos. Isso é feito construindo um grafo onde cada ponto é um fluxo e arestas conectam fluxos que se comportam de forma parecida. Rótulos do núcleo confiante se espalham por esse grafo, e apenas amostras cujos novos rótulos são altamente consistentes são mantidas como “limpas”. Estas se tornam âncoras para o treinamento, especialmente para o abundante tráfego normal.
Focando nos ataques raros
O tráfego normal domina conjuntos de dados reais, mas os fluxos maliciosos raros são os que mais importam. Muitos deles permanecem incertos após a primeira passagem baseada em grafo. Para tratar esses casos, o SilentSentinel adiciona um segundo módulo, Triagem de Amostras Maliciosas (Malicious Sample Screening - MSS). Aqui, duas redes neurais com a mesma estrutura, mas pontos de partida diferentes, aprendem juntas. Cada rede, a cada passo de treinamento, seleciona os subconjuntos de amostras que considera mais confiáveis e os compartilha com a outra. Ao longo do tempo, esse ensino recíproco se concentra em exemplos nos quais ambas as redes concordam e gradualmente filtra aqueles que provavelmente estão rotulados incorretamente. Uma função de perda especialmente escolhida ajuda a evitar que a classe majoritária esmagadora ofusque as amostras raras de ataque, tornando o conjunto final de exemplos maliciosos tanto mais puro quanto mais informativo.
Testando o sistema
Os autores avaliaram o SilentSentinel em dois conjuntos de dados de intrusão amplamente usados: CIC-IDS2017, que cobre muitos tipos de ataques clássicos, e DoHBrw-2020, que foca no tráfego criptografado DNS-over-HTTPS. Eles simularam condições realistas ao inverter deliberadamente uma fração substancial de rótulos, até 40%, e compararam o SilentSentinel com vários métodos de ponta que visam lidar com dados ruidosos. Em cenários tanto de ruído simétrico quanto assimétrico, o SilentSentinel alcançou consistentemente escores F1 mais altos, um equilíbrio entre precisão e recall. No conjunto mais desafiador CIC-IDS2017, melhorou o desempenho em mais de 17% em comparação com a melhor abordagem concorrente sob alto ruído. No DoHBrw, manteve o desempenho quase perfeito mesmo com o aumento do ruído de rótulo, enquanto métodos rivais degradaram-se notavelmente. Análises adicionais mostraram que o SilentSentinel deixou muito menos amostras rotuladas incorretamente no conjunto final de treinamento do que técnicas existentes.
O que isso significa para a segurança do dia a dia
Para um público leigo, a conclusão é direta: se você ensina um sistema de segurança a partir de exemplos cheios de erros, ele cometerá erros no mundo real. O SilentSentinel atua como um editor cuidadoso que percorre um conjunto de treinamento ruidoso, verifica cada exemplo em relação aos seus vizinhos e a duas redes “revisoras” independentes, e corrige ou descarta entradas suspeitas antes do aprendizado principal começar. Ao fazer isso, permite que detectores de intrusão vejam uma imagem mais clara do que tráfego normal e malicioso realmente são, mesmo quando os rótulos originais são pouco confiáveis. O resultado final é um defensor de borda de rede mais estável e confiável—um que continua a ter bom desempenho mesmo quando os dados dos quais aprende estão longe de ser perfeitos.
Citação: Zhao, R., Ding, J., Dong, Q. et al. Mitigating label noise in network intrusion detection via graph-based sample selection and purification. Sci Rep 16, 11674 (2026). https://doi.org/10.1038/s41598-026-45988-y
Palavras-chave: detecção de intrusão em rede, ruído de rótulo, aprendizado baseado em grafo, rótulos ruidosos, detecção de tráfego malicioso