Clear Sky Science · en
Mitigating label noise in network intrusion detection via graph-based sample selection and purification
Why Cleaner Labels Matter for Cybersecurity
Every day, security systems watch rivers of internet traffic, trying to spot the few malicious connections hiding among millions of normal ones. These systems increasingly rely on machine learning, which learns from past examples labeled as “safe” or “attack.” But if many of those labels are wrong, even powerful models can be misled, leaving networks more vulnerable than they appear. This paper introduces SilentSentinel, a method designed to clean up those labels before training, so intrusion detectors can learn from data they can actually trust.
The Hidden Problem of Wrong Labels
Building good intrusion detection systems starts with data, and that is where things go wrong. To get “malicious” traffic, researchers often run malware in controlled environments and label everything it generates as bad. In reality, much of that traffic is perfectly normal, so harmless connections are mistakenly tagged as attacks. Automated intrusion detection tools used for labeling can also misfire, especially when facing new, never-before-seen threats. These mistakes create “label noise,” a situation where many samples in a dataset carry the wrong tag. When noise gets high and attacks are rare compared with normal traffic, standard training methods struggle: models begin to memorize errors, their decision boundaries shift in the wrong direction, and detection accuracy drops sharply.
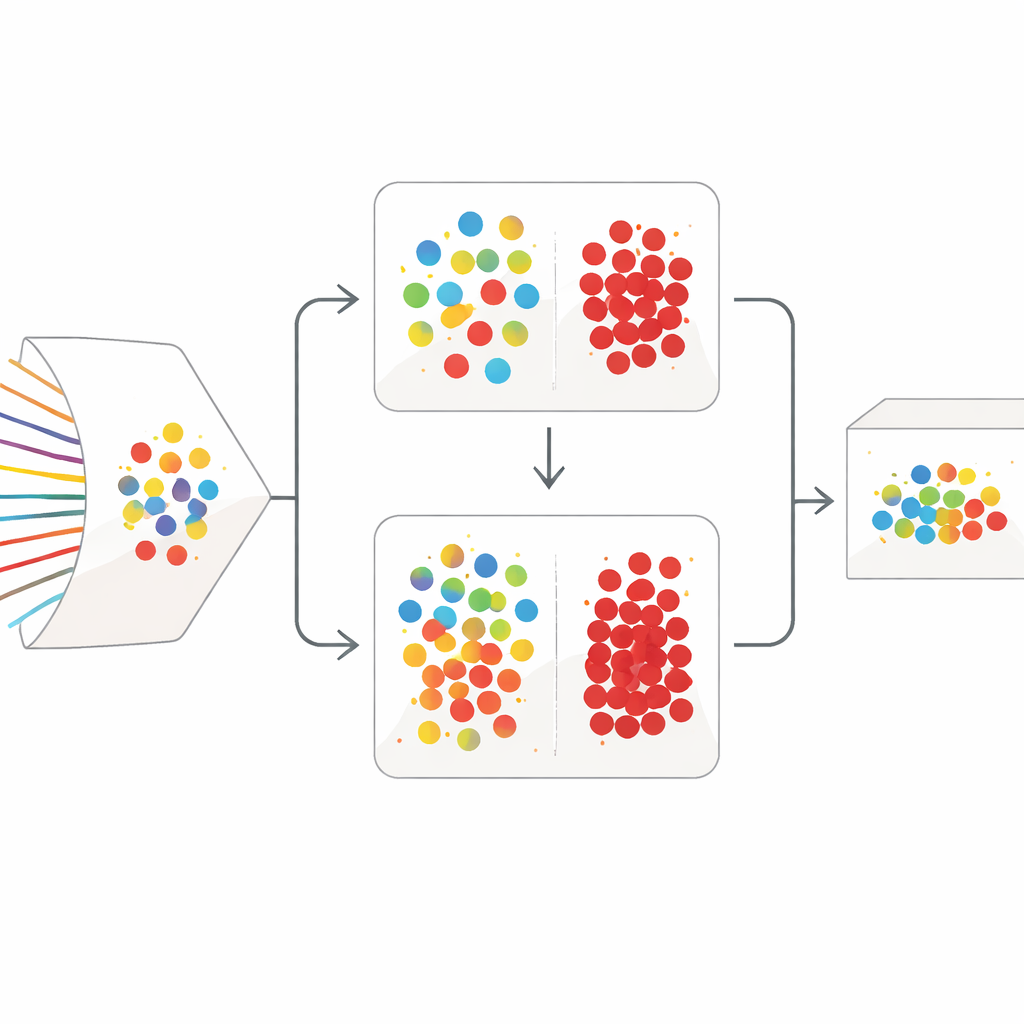
A Two-Stage Cleanup Strategy
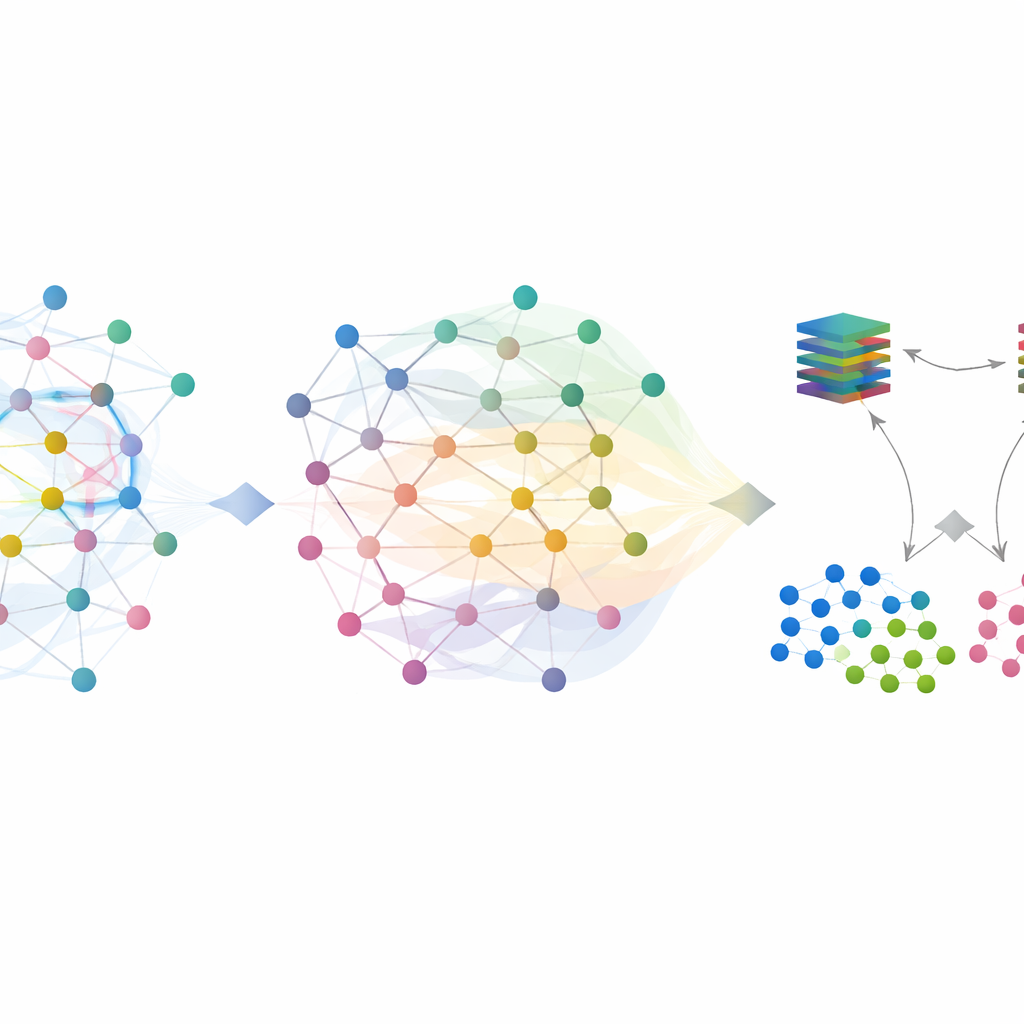
SilentSentinel tackles this problem with a data-centric approach: instead of only trying to make the model itself more robust, it first works to fix the training data. The key observation is that network flows from the same real-world behavior tend to look similar in a feature space, whether they are truly normal or truly malicious. SilentSentinel’s first module, called Normal Sample Discovery (NSD), looks for traffic samples that the model is very confident about, assumes their labels are correct, and then uses their similarity relationships to re-label their neighbors. This is done by building a graph where each point is a flow and edges connect flows that behave alike. Labels from the confident core spread over this graph, and only samples whose new labels are highly consistent are kept as “clean.” These become anchors for training, especially for the abundant normal traffic.
Zooming In on Rare Attacks
Normal traffic dominates real datasets, but the rare, truly malicious flows are the ones that matter most. Many of them remain uncertain after the first graph-based pass. To handle these, SilentSentinel adds a second module, Malicious Sample Screening (MSS). Here, two neural networks with the same structure but different starting points learn together. Each network, at every training step, selects the subsets of samples it finds most trustworthy and shares them with the other. Over time, this back-and-forth teaching focuses on examples that both networks agree on and gradually filters out those likely to be mislabeled. A specially chosen loss function helps prevent the overwhelming majority class from drowning out the scarce attack samples, making the final set of malicious examples both purer and more informative.
Putting the System to the Test
The authors evaluated SilentSentinel on two widely used intrusion datasets: CIC-IDS2017, which covers many types of classic attacks, and DoHBrw-2020, which focuses on encrypted DNS-over-HTTPS traffic. They simulated realistic conditions by deliberately flipping a substantial fraction of labels, up to 40 percent, and compared SilentSentinel against several leading methods that aim to cope with noisy data. Across both symmetric and asymmetric noise settings, SilentSentinel consistently achieved higher F1 scores, a balance of precision and recall. On the more challenging CIC-IDS2017 data, it improved performance by over 17 percent compared with the best competing approach under high noise. On DoHBrw, it kept performance near perfect even as label noise increased, while rival methods degraded noticeably. Further analysis showed that SilentSentinel left far fewer mislabeled samples in the final training set than existing techniques.
What This Means for Everyday Security
For a layperson, the takeaway is straightforward: if you teach a security system from examples that are full of mistakes, it will make mistakes in the real world. SilentSentinel acts like a careful editor that reads through a noisy training dataset, cross-checks each example against its neighbors and against two independent “reviewer” networks, and fixes or discards suspicious entries before the main learning begins. By doing this, it allows intrusion detection models to see a clearer picture of what normal and malicious traffic truly look like, even when the original labels are unreliable. The end result is a more stable and trustworthy defender on the network edge—one that keeps performing well even when the data it learns from is far from perfect.
Citation: Zhao, R., Ding, J., Dong, Q. et al. Mitigating label noise in network intrusion detection via graph-based sample selection and purification. Sci Rep 16, 11674 (2026). https://doi.org/10.1038/s41598-026-45988-y
Keywords: network intrusion detection, label noise, graph-based learning, noisy labels, malicious traffic detection