Clear Sky Science · it
Mitigare il rumore delle etichette nel rilevamento delle intrusioni di rete tramite selezione e purificazione dei campioni basate su grafi
Perché etichette più pulite sono importanti per la cybersecurity
Ogni giorno i sistemi di sicurezza osservano flussi enormi di traffico internet, cercando di individuare le poche connessioni dannose nascoste tra milioni di connessioni normali. Questi sistemi si basano sempre più sull’apprendimento automatico, che impara da esempi passati etichettati come “sicuro” o “attacco”. Ma se molte di quelle etichette sono sbagliate, anche modelli potenti possono essere fuorviati, lasciando le reti più vulnerabili di quanto appaiano. Questo articolo presenta SilentSentinel, un metodo progettato per ripulire quelle etichette prima dell’addestramento, così che i rilevatori di intrusioni possano apprendere da dati su cui possono effettivamente contare.
Il problema nascosto delle etichette errate
Costruire buoni sistemi di rilevamento delle intrusioni comincia dai dati, ed è proprio qui che si generano gli errori. Per ottenere traffico “maligno”, i ricercatori spesso eseguono malware in ambienti controllati e marcano tutto ciò che viene generato come dannoso. In realtà, gran parte di quel traffico è perfettamente normale, quindi connessioni innocue vengono etichettate per errore come attacchi. Anche gli strumenti automatizzati di rilevamento usati per etichettare possono sbagliare, specialmente quando affrontano minacce nuove e mai viste prima. Questi errori creano il “rumore delle etichette”, una situazione in cui molti campioni in un dataset portano il tag sbagliato. Quando il rumore è elevato e gli attacchi sono rari rispetto al traffico normale, i metodi di addestramento standard faticano: i modelli cominciano a memorizzare gli errori, i confini decisionali si spostano nella direzione sbagliata e l’accuratezza del rilevamento cala drasticamente.
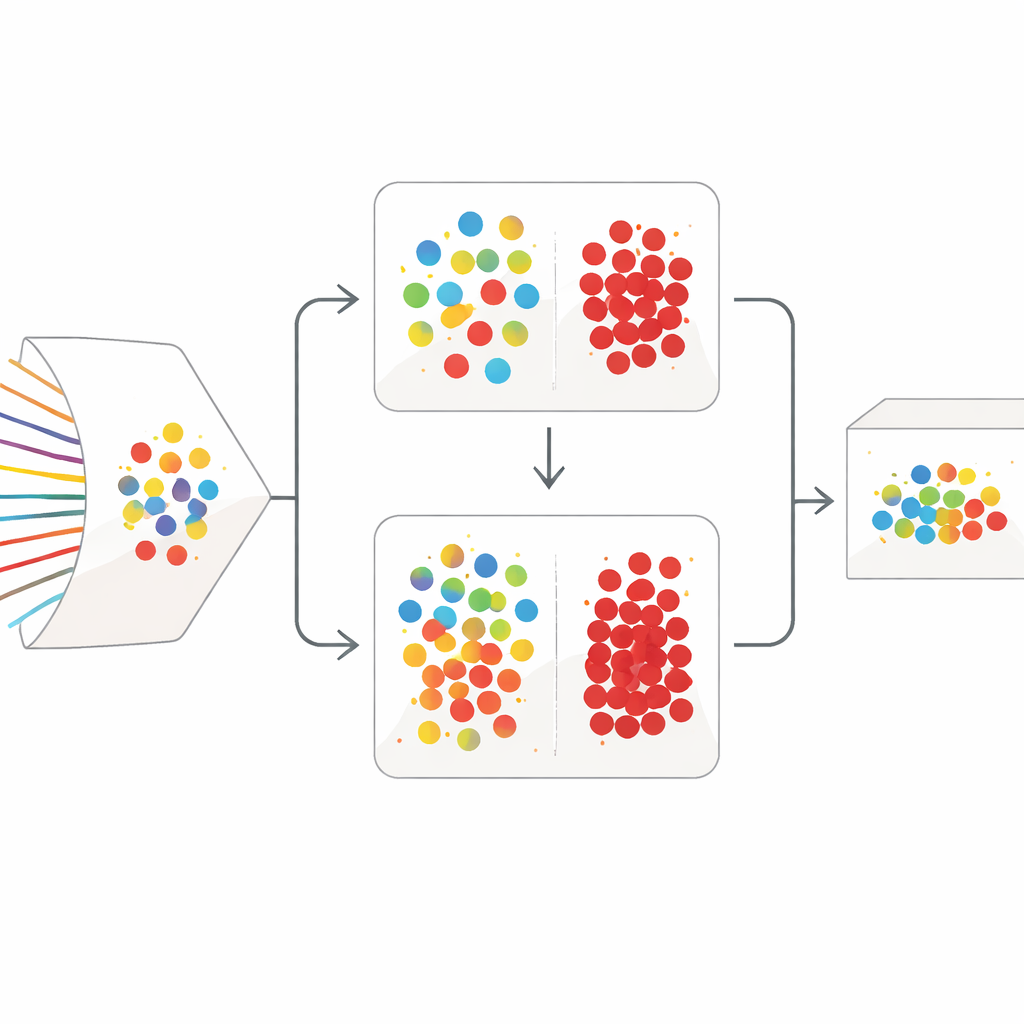
Una strategia di pulizia in due stadi
SilentSentinel affronta questo problema con un approccio centrato sui dati: invece di limitarsi a rendere il modello più robusto, lavora prima per correggere i dati di addestramento. L’osservazione chiave è che i flussi di rete che derivano dallo stesso comportamento reale tendono ad apparire simili in uno spazio di feature, sia che siano veramente normali sia che siano realmente maligni. Il primo modulo di SilentSentinel, chiamato Normal Sample Discovery (NSD), cerca i campioni di traffico su cui il modello è molto sicuro, assume che le loro etichette siano corrette e poi usa le relazioni di somiglianza per rietichettare i vicini. Questo avviene costruendo un grafo in cui ogni punto è un flusso e gli archi collegano flussi che si comportano in modo analogo. Le etichette dal nucleo fidato si propagano su questo grafo, e vengono mantenuti come “puliti” solo i campioni le cui nuove etichette risultano altamente coerenti. Questi diventano ancore per l’addestramento, soprattutto per l’abbondante traffico normale.
Concentrarsi sugli attacchi rari
Il traffico normale domina i dataset reali, ma i flussi veramente maligni e rari sono quelli che contano di più. Molti di essi restano incerti dopo il primo passaggio basato sul grafo. Per gestire questi casi, SilentSentinel aggiunge un secondo modulo, Malicious Sample Screening (MSS). Qui, due reti neurali con la stessa architettura ma inizializzazioni diverse apprendono insieme. Ogni rete, ad ogni passo di addestramento, seleziona i sottoinsiemi di campioni che considera più affidabili e li condivide con l’altra. Col tempo questo insegnamento reciproco si concentra sugli esempi su cui entrambe le reti concordano e filtra gradualmente quelli probabilmente etichettati male. Una funzione di perdita scelta appositamente aiuta a impedire che la classe maggioritaria schiacciante sovrasti i rari campioni di attacco, rendendo il set finale di esempi maligni sia più puro sia più informativo.
Mettere il sistema alla prova
Gli autori hanno valutato SilentSentinel su due dataset di intrusioni largamente usati: CIC-IDS2017, che copre molti tipi di attacchi classici, e DoHBrw-2020, incentrato sul traffico DNS-over-HTTPS cifrato. Hanno simulato condizioni realistiche ribaltando deliberatamente una frazione consistente di etichette, fino al 40 percento, e hanno confrontato SilentSentinel con diversi metodi di riferimento pensati per gestire dati rumorosi. In entrambe le condizioni di rumore simmetrico e asimmetrico, SilentSentinel ha ottenuto costantemente punteggi F1 più alti, un equilibrio tra precisione e richiamo. Sul dataset più sfidante CIC-IDS2017, ha migliorato le prestazioni di oltre il 17 percento rispetto al miglior approccio concorrente sotto elevato rumore. Su DoHBrw ha mantenuto prestazioni quasi perfette anche all’aumentare del rumore delle etichette, mentre i metodi rivali degradavano in modo evidente. Analisi ulteriori hanno mostrato che SilentSentinel ha lasciato molto meno campioni etichettati male nel set di addestramento finale rispetto alle tecniche esistenti.
Che cosa significa per la sicurezza quotidiana
Per il lettore non specialistico, la conclusione è semplice: se insegni a un sistema di sicurezza da esempi pieni di errori, esso commetterà errori nel mondo reale. SilentSentinel funziona come un attento redattore che scorre un dataset di addestramento rumoroso, verifica ogni esempio rispetto ai vicini e rispetto a due reti “revisori” indipendenti, e corregge o scarta le voci sospette prima dell’inizio dell’apprendimento principale. Facendo così, permette ai modelli di rilevamento delle intrusioni di vedere un quadro più chiaro di come appare realmente il traffico normale e quello maligno, anche quando le etichette originali sono inaffidabili. Il risultato finale è un difensore al bordo della rete più stabile e affidabile — capace di mantenere buone prestazioni anche quando i dati da cui apprende sono lontani dalla perfezione.
Citazione: Zhao, R., Ding, J., Dong, Q. et al. Mitigating label noise in network intrusion detection via graph-based sample selection and purification. Sci Rep 16, 11674 (2026). https://doi.org/10.1038/s41598-026-45988-y
Parole chiave: rilevamento intrusioni di rete, rumore delle etichette, apprendimento basato su grafi, etichette rumorose, rilevamento del traffico dannoso