Clear Sky Science · ar
التخفيف من ضوضاء التسميات في كشف التسلل الشبكي عبر اختيار وتنقية العينات المستندة إلى الرسم البياني
لماذا تهم التسميات الأنظف في الأمن السيبراني
يومياً، تراقب أنظمة الأمن تيارات هائلة من حركة الإنترنت محاولةً رصد الاتصالات الخبيثة القليلة المختبئة بين ملايين الاتصالات العادية. تعتمد هذه الأنظمة بشكل متزايد على التعلم الآلي، الذي يتعلم من أمثلة سابقة موصوفة بأنها «آمنة» أو «هجوم». لكن إذا كانت العديد من تلك التسميات خاطئة، فإن حتى النماذج القوية يمكن أن تُضلَّ، مما يجعل الشبكات أكثر عرضة للخطر مما تبدو عليه. يقدم هذا البحث SilentSentinel، طريقة مصممة لتنقية تلك التسميات قبل التدريب، حتى تتمكن أنظمة كشف التسلل من التعلم من بيانات يمكن الوثوق بها فعلاً.
المشكلة الخفية للتسميات الخاطئة
يبنى إنشاء أنظمة كشف التسلل الجيدة على بيانات، وهنا تبدأ المشكلات. للحصول على حركة «خبيثة»، غالباً ما يقوم الباحثون بتشغيل برمجيات خبيثة في بيئات مُنضبطة ويصنفون كل ما تُولِّده كخبيث. في الواقع، الكثير من تلك الحركة طبيعي تماماً، فيتم وسم الاتصالات الآمنة بالخطأ على أنها هجمات. كما يمكن لأدوات الكشف الآلية المستخدمة في الوسم أن ترتكب أخطاء، خصوصاً عند مواجهة تهديدات جديدة لم تُرَ من قبل. تخلق هذه الأخطاء «ضوضاء في التسميات»، وهي حالة تحمل فيها عينات كثيرة في مجموعة البيانات وسماً خاطئاً. عندما تزيد الضوضاء ويكون الهجوم نادراً مقارنةً بحركة المرور العادية، تكافح طرق التدريب القياسية: تبدأ النماذج في حفظ الأخطاء، وتتحول حدود القرار في الاتجاه الخاطئ، وتنخفض دقة الكشف بشدة.
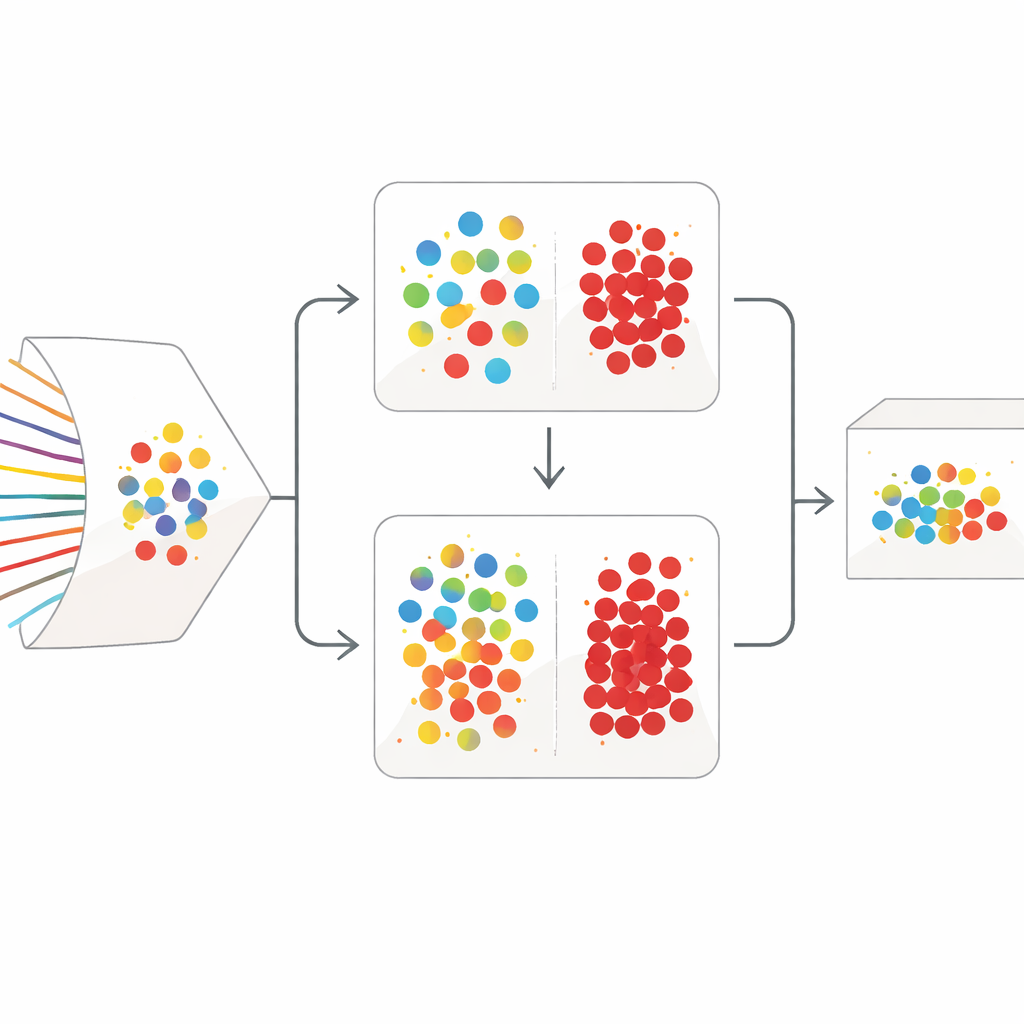
استراتيجية تنظيف من مرحلتين
يتعامل SilentSentinel مع هذه المشكلة بمنهج متمركز حول البيانات: بدلاً من محاولة جعل النموذج أكثر متانة فقط، يعمل أولاً على إصلاح بيانات التدريب. الملاحظة الرئيسية هي أن تدفقات الشبكة الناتجة عن نفس السلوك الواقعي تميل إلى الظهور متشابهة في فضاء السمات، سواء كانت فعلاً عادية أو خبيثة. الوحدة الأولى في SilentSentinel، المسماة اكتشاف العينات العادية (NSD)، تبحث عن عينات حركة يكون النموذج واثقاً جداً منها، تفترض صحة تسمياتها، ثم تستخدم علاقات التشابه لإعادة وسم جيرانها. يتم ذلك ببناء رسم بياني حيث كل نقطة تمثل تدفقاً وتوصِل الحواف التدفقات المتشابهة السلوك. تنتشر التسميات من النواة الواثقة عبر هذا الرسم البياني، ولا تُحتفظ إلا بالعينات التي تكون تسمياتها الجديدة متسقة بدرجة عالية كـ «نظيفة». تصبح هذه بمثابة مراسي للتدريب، وخاصة لحركة المرور العادية الوفيرَة.
التركيز على الهجمات النادرة
تسود حركة المرور العادية مجموعات البيانات الحقيقية، لكن التدفقات الخبيثة النادرة هي الأهم. يبقى الكثير منها غير مؤكد بعد المرور الأول القائم على الرسم البياني. للتعامل مع هذه الحالة، يضيف SilentSentinel وحدة ثانية، فحص العينات الخبيثة (MSS). هنا، يتعلَّم شبكتان عصبيتان لهما نفس البنية لكن بنقطة انطلاق مختلفة معاً. في كل خطوة تدريب، تختار كل شبكة تحت مجموعات العينات التي تعتبرها الأكثر جدارة بالثقة وتشاركها مع الأخرى. مع مرور الوقت، يركِّز هذا التدريس المتبادل على الأمثلة التي تتفق عليها الشركتان ويصفِّي تدريجياً تلك التي يحتمل أن تكون مُوسومة خطأ. تساعد دالة خسارة مختارة بعناية على منع فئة الأغلبية الساحقة من طمس العينات النادرة للهجوم، مما يجعل مجموعة الأمثلة الخبيثة النهائية أنقى وأكثر إفادة.
اختبار النظام
قيَّم المؤلفون SilentSentinel على مجموعتي بيانات شائعتين للكشف عن التسلل: CIC-IDS2017، التي تغطي أنواعاً عديدة من الهجمات التقليدية، وDoHBrw-2020، التي تركز على حركة DNS-over-HTTPS المشفرة. محاكوا ظروفاً واقعية عبر قلب جزء كبير من التسميات عمدًا — حتى 40 بالمئة — وقارنوا SilentSentinel بعدة طرق رائدة تهدف إلى التعامل مع البيانات المشوشة. عبر إعدادات الضوضاء المتماثلة وغير المتماثلة، حقق SilentSentinel باستمرار نقاط F1 أعلى، وهو مقياس يوازن بين الدقة والاستدعاء. على بيانات CIC-IDS2017 الأكثر تحدياً، حسّن الأداء بأكثر من 17 بالمئة مقارنةً بأفضل نهج منافس تحت ضوضاء عالية. في DoHBrw، حافظ على أداء قريب من الكمال حتى مع زيادة ضوضاء التسميات، بينما تدهورت طرق المنافسين بشكل ملحوظ. أظهر التحليل الإضافي أن SilentSentinel ترك عدداً أقل بكثير من العينات ذات التسميات الخاطئة في مجموعة التدريب النهائية مقارنة بالتقنيات الحالية.
ماذا يعني هذا للأمن اليومي
الخلاصة للمستخدم العادي بسيطة: إذا علمت نظام أمنية من أمثلة مليئة بالأخطاء، فسيرتكب أخطاء في العالم الحقيقي. يعمل SilentSentinel كمحرر حريص يراجع مجموعة تدريب صاخبة، يتحقق متقاطعاً من كل مثال مقابل جيرانه وضد شبكتين «مراجعتين» مستقلتين، ويصلح أو يتخلص من الإدخالات المشبوهة قبل بدء التعلم الرئيسي. من خلال ذلك، يسمح لنماذج كشف التسلل برؤية صورة أوضح لما تبدو عليه الحركة العادية والخبيثة فعلاً، حتى عندما تكون التسميات الأصلية غير موثوقة. والنتيجة النهائية هي مدافع أكثر استقراراً وموثوقية على حافة الشبكة — يحافظ على أداء جيد حتى عندما تكون البيانات التي يتعلم منها بعيدة عن الكمال.
الاستشهاد: Zhao, R., Ding, J., Dong, Q. et al. Mitigating label noise in network intrusion detection via graph-based sample selection and purification. Sci Rep 16, 11674 (2026). https://doi.org/10.1038/s41598-026-45988-y
الكلمات المفتاحية: كشف التسلل الشبكي, ضوضاء التسميات, التعلم القائم على الرسوم البيانية, التسميات المشوشة, كشف الحركة الخبيثة