Clear Sky Science · ru
Снижение шума в метках для обнаружения сетевых вторжений с помощью выборки и очистки образцов на графе
Почему более чистые метки важны для кибербезопасности
Каждый день системы безопасности отслеживают потоки интернет-трафика, пытаясь обнаружить несколько вредоносных соединений, скрывающихся среди миллионов нормальных. Эти системы всё чаще опираются на машинное обучение, которое учится на прошлых примерах, помеченных как «безопасно» или «атака». Но если многие из этих меток неверны, даже мощные модели могут быть введены в заблуждение, оставляя сети более уязвимыми, чем кажется. В этой статье предложен SilentSentinel — метод, предназначенный для очистки меток перед обучением, чтобы детекторы вторжений учились на данных, которым можно действительно доверять.
Скрытая проблема неверных меток
Построение хороших систем обнаружения вторжений начинается с данных, и именно здесь возникают проблемы. Чтобы получить «вредоносный» трафик, исследователи часто запускают вредоносное ПО в контролируемой среде и помечают всё, что оно генерирует, как вредоносное. На практике большая часть такого трафика совершенно нормальна, поэтому безвредные соединения ошибочно маркируются как атаки. Автоматические инструменты разметки вторжений также могут ошибаться, особенно при встрече с новыми, ранее не виденными угрозами. Эти ошибки создают «шум в метках» — ситуацию, когда многие образцы в датасете несут неверную метку. Когда уровень шума велик, а атаки редки по сравнению с нормальным трафиком, стандартные методы обучения испытывают трудности: модели начинают запоминать ошибки, их границы решений смещаются в неверном направлении, и точность обнаружения резко падает.
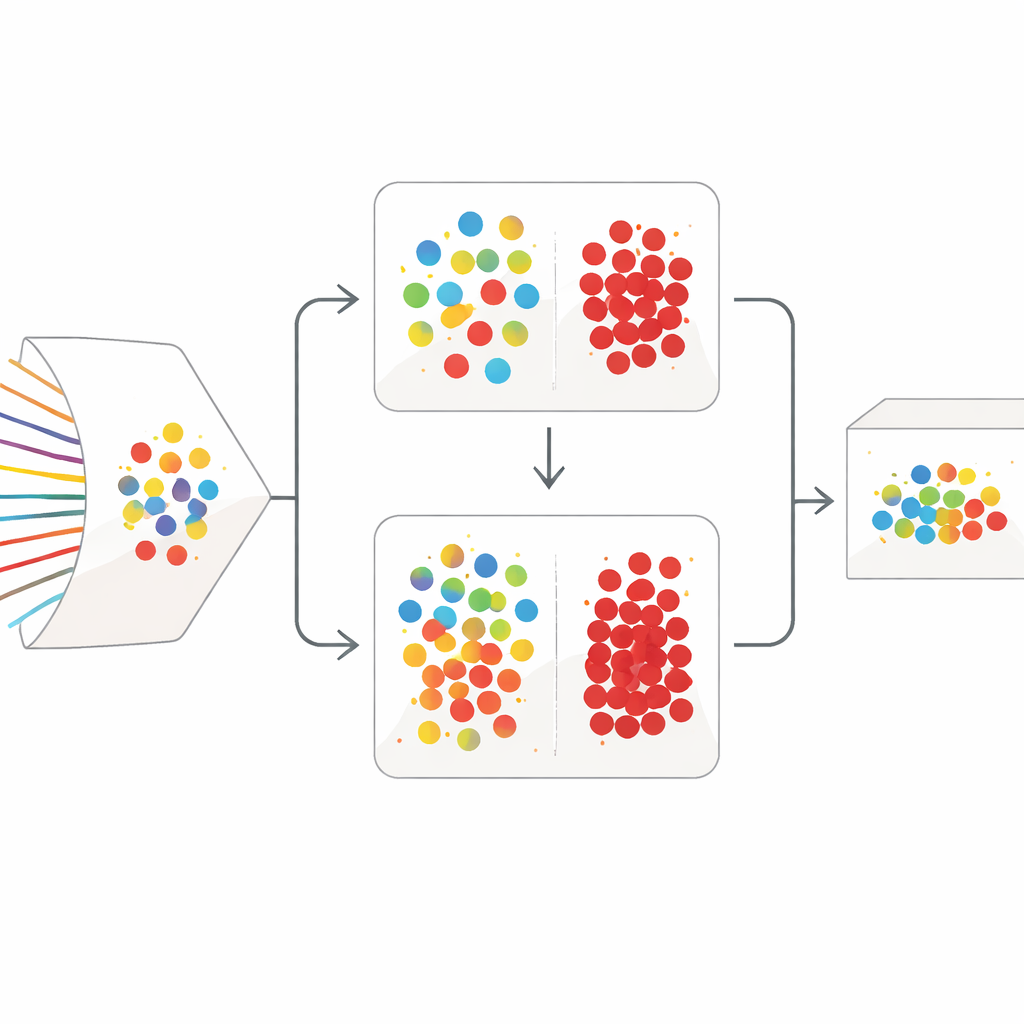
Стратегия очистки в два этапа
SilentSentinel решает эту проблему, ориентируясь на данные: вместо того чтобы лишь повышать устойчивость самой модели, он сначала работает над исправлением обучающего набора. Ключевое наблюдение: сетевые потоки, соответствующие одному и тому же поведению в реальном мире, как правило, выглядят схожими в пространстве признаков — независимо от того, действительно ли они нормальные или вредоносные. Первый модуль SilentSentinel, называемый Normal Sample Discovery (NSD), ищет образцы трафика, в которых модель очень уверена, предполагает их метки корректными и затем использует отношения схожести, чтобы переназначать метки их соседям. Это делается путём построения графа, где каждая точка — это поток, а рёбра соединяют похожие по поведению потоки. Метки из уверенного ядра распространяются по этому графу, и только образцы, чьи новые метки оказываются высоко согласованными, сохраняются как «чистые». Они становятся опорными примерами для обучения, особенно для преобладающего нормального трафика.
Углублённый анализ редких атак
Нормальный трафик доминирует в реальных наборах данных, но редкие, действительно вредоносные потоки — самые важные. Многие из них остаются неопределёнными после первого графового этапа. Чтобы справиться с этим, SilentSentinel добавляет второй модуль — Malicious Sample Screening (MSS). Здесь две нейронные сети с одинаковой архитектурой, но разными начальными инициализациями обучаются совместно. На каждом шаге обучения каждая сеть отбирает подмножества образцов, которым она больше всего доверяет, и делится ими с другой сетью. Со временем это взаимное обучение фокусируется на примерах, по которым обе сети сходятся во мнении, и постепенно отфильтровывает те, которые, вероятно, промаркированы неверно. Специально подобранная функция потерь помогает предотвратить подавление редких классов атак доминирующим большинством, делая итоговый набор вредоносных примеров как более чистым, так и более информативным.
Проверка системы на практике
Авторы оценивали SilentSentinel на двух широко используемых наборах данных по вторжениям: CIC-IDS2017, охватывающем множество классических атак, и DoHBrw-2020, ориентированном на шифрованный трафик DNS-over-HTTPS. Они смоделировали реалистичные условия, намеренно переворачивая значительную долю меток — до 40 процентов, — и сравнили SilentSentinel с несколькими ведущими методами, направленными на работу с зашумлёнными данными. В условиях как симметричного, так и асимметричного шума SilentSentinel стабильно демонстрировал более высокие F1-метрики, баланс точности и полноты. На более сложном наборе CIC-IDS2017 он улучшил результаты более чем на 17 процентов по сравнению с лучшим из конкурентов при высоком уровне шума. На DoHBrw метод сохранял практически идеальную производительность даже при росте шума в метках, в то время как альтернативные подходы заметно деградировали. Дополнительный анализ показал, что в итоговом обучающем наборе SilentSentinel оставлял значительно меньше промаркированных неверно образцов, чем существующие техники.
Что это значит для повседневной безопасности
Для неспециалиста вывод прост: если обучать систему безопасности на примерах, полных ошибок, она будет ошибаться в реальной работе. SilentSentinel действует как внимательный редактор, который просматривает зашумлённый обучающий набор, сверяет каждый пример с соседями и с двумя независимыми «рецензентами»-сетями и исправляет или отбрасывает подозрительные записи до начала основного обучения. Тем самым он позволяет моделям обнаружения вторжений яснее видеть, как на самом деле выглядят нормальный и вредоносный трафик, даже когда исходные метки ненадёжны. В результате получается более устойчивый и надёжный защитник на краю сети — тот, который продолжает эффективно работать, даже если данные, на которых он учился, далеки от совершенства.
Цитирование: Zhao, R., Ding, J., Dong, Q. et al. Mitigating label noise in network intrusion detection via graph-based sample selection and purification. Sci Rep 16, 11674 (2026). https://doi.org/10.1038/s41598-026-45988-y
Ключевые слова: обнаружение сетевых вторжений, шум в метках, обучение на графах, зашумленные метки, обнаружение вредоносного трафика