Clear Sky Science · es
Mitigar el ruido de etiquetas en la detección de intrusiones en redes mediante selección y purificación de muestras basada en grafos
Por qué importan etiquetas más limpias para la ciberseguridad
Cada día, los sistemas de seguridad vigilan ríos de tráfico de Internet tratando de detectar las pocas conexiones maliciosas ocultas entre millones de conexiones normales. Estos sistemas dependen cada vez más del aprendizaje automático, que aprende a partir de ejemplos previos etiquetados como “seguro” o “ataque”. Pero si muchas de esas etiquetas son incorrectas, incluso modelos potentes pueden ser engañados, dejando las redes más vulnerables de lo que parecen. Este artículo presenta SilentSentinel, un método diseñado para limpiar esas etiquetas antes del entrenamiento, de modo que los detectores de intrusiones puedan aprender a partir de datos en los que realmente confiar.
El problema oculto de las etiquetas erróneas
La construcción de buenos sistemas de detección de intrusiones comienza con los datos, y es ahí donde surgen los problemas. Para obtener tráfico “malicioso”, los investigadores con frecuencia ejecutan malware en entornos controlados y etiquetan todo lo que genera como malo. En realidad, gran parte de ese tráfico es perfectamente normal, por lo que conexiones inocuas se marcan por error como ataques. Las herramientas automáticas de detección usadas para etiquetar también pueden fallar, especialmente ante amenazas nuevas y nunca vistas antes. Estos errores crean “ruido de etiquetas”, una situación en la que muchas muestras de un conjunto de datos llevan la etiqueta equivocada. Cuando el ruido es alto y los ataques son raros en comparación con el tráfico normal, los métodos de entrenamiento estándar tienen dificultades: los modelos empiezan a memorizar errores, sus fronteras de decisión se desplazan en la dirección equivocada y la precisión de la detección cae de forma brusca.
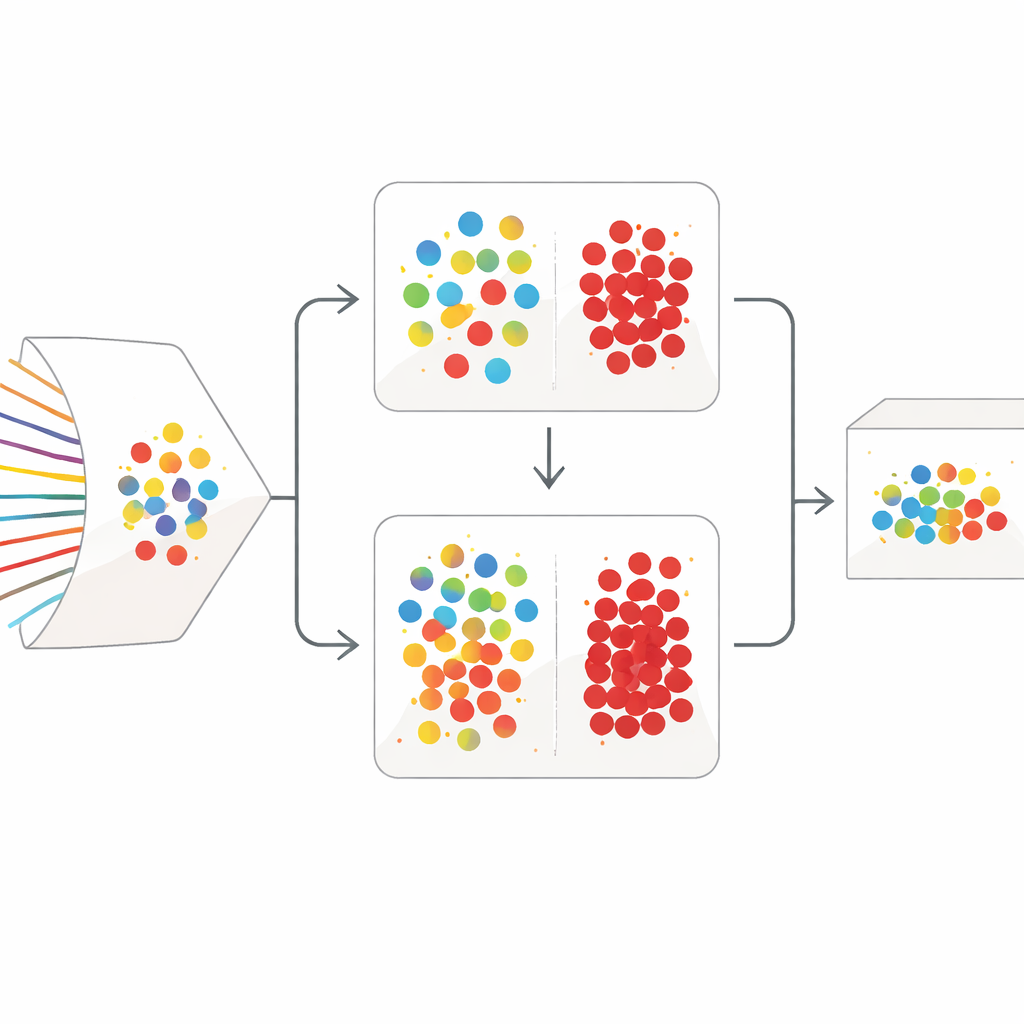
Una estrategia de limpieza en dos fases
SilentSentinel aborda este problema con un enfoque centrado en los datos: en lugar de intentar solo hacer al modelo más robusto, trabaja primero en corregir los datos de entrenamiento. La observación clave es que los flujos de red derivados del mismo comportamiento real tienden a parecerse en un espacio de características, ya sean realmente normales o realmente maliciosos. El primer módulo de SilentSentinel, llamado Descubrimiento de Muestras Normales (NSD), busca muestras de tráfico en las que el modelo tiene mucha confianza, asume que sus etiquetas son correctas y luego usa sus relaciones de similitud para reetiquetar a sus vecinos. Esto se hace construyendo un grafo donde cada punto es un flujo y las aristas conectan flujos que se comportan de forma similar. Las etiquetas del núcleo confiable se propagan por este grafo, y solo se conservan como “limpias” las muestras cuyas nuevas etiquetas son altamente consistentes. Estas se convierten en anclas para el entrenamiento, especialmente para el abundante tráfico normal.
Enfocándose en ataques raros
El tráfico normal domina los conjuntos de datos reales, pero los flujos pocos y verdaderamente maliciosos son los que más importan. Muchos de ellos permanecen inciertos tras la primera pasada basada en grafos. Para manejarlos, SilentSentinel añade un segundo módulo, Cribado de Muestras Maliciosas (MSS). Aquí, dos redes neuronales con la misma arquitectura pero puntos de partida distintos aprenden de forma conjunta. Cada red, en cada paso de entrenamiento, selecciona los subconjuntos de muestras que considera más fiables y se los comparte a la otra. Con el tiempo, esta enseñanza recíproca se centra en ejemplos en los que ambas redes coinciden y filtra gradualmente aquellos que probablemente están mal etiquetados. Una función de pérdida escogida específicamente ayuda a evitar que la clase mayoritaria abrumadora ahogue a las escasas muestras de ataque, haciendo que el conjunto final de ejemplos maliciosos sea tanto más puro como más informativo.
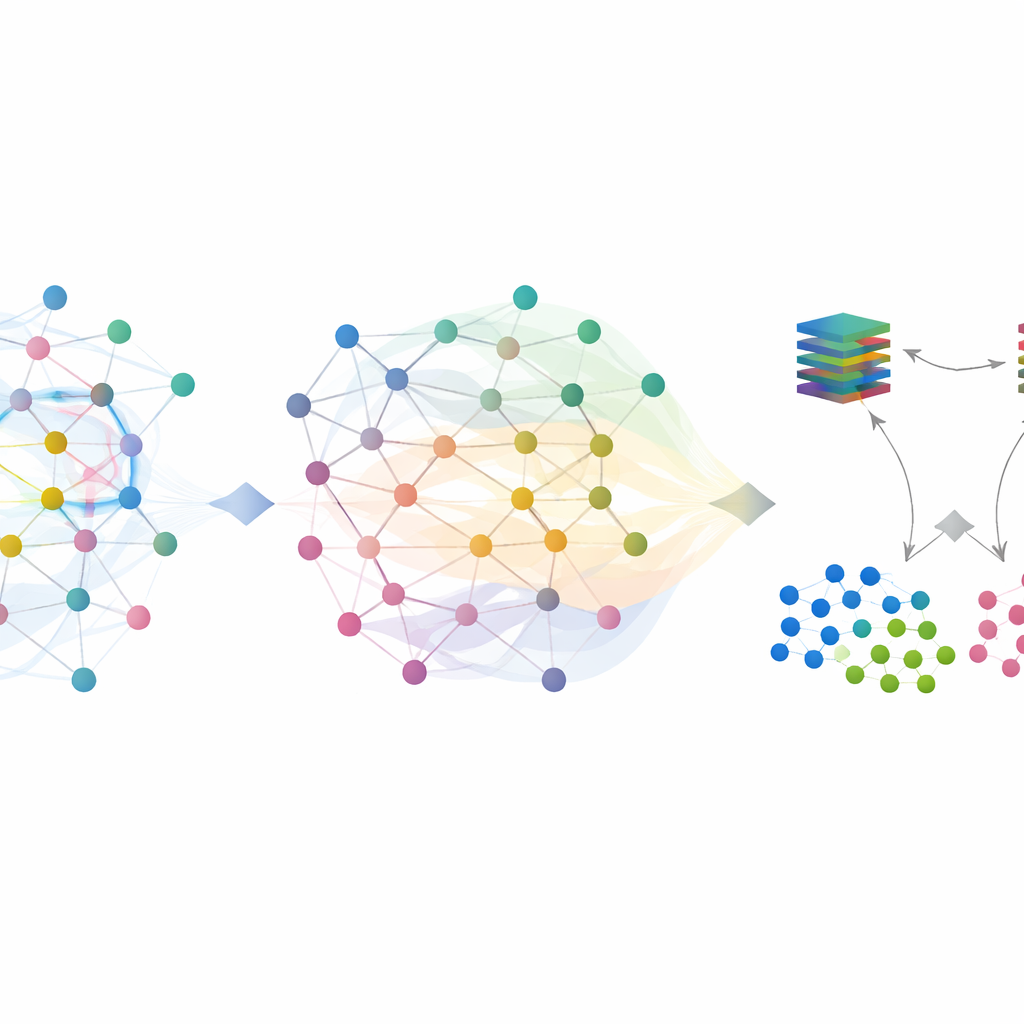
Poniendo el sistema a prueba
Los autores evaluaron SilentSentinel en dos conjuntos de datos de intrusiones ampliamente usados: CIC-IDS2017, que cubre muchos tipos de ataques clásicos, y DoHBrw-2020, que se centra en tráfico cifrado DNS-over-HTTPS. Simularon condiciones realistas invirtiendo deliberadamente una fracción sustancial de las etiquetas, hasta un 40 por ciento, y compararon SilentSentinel con varios métodos líderes que intentan lidiar con datos ruidosos. En escenarios con ruido tanto simétrico como asimétrico, SilentSentinel logró consistentemente puntuaciones F1 más altas, un equilibrio entre precisión y exhaustividad. En el más desafiante conjunto CIC-IDS2017, mejoró el rendimiento en más de un 17 por ciento frente al mejor enfoque competidor bajo ruido elevado. En DoHBrw, mantuvo el rendimiento casi perfecto incluso a medida que aumentaba el ruido de etiquetas, mientras que los métodos rivales se degradaban visiblemente. Un análisis adicional mostró que SilentSentinel dejó muchos menos ejemplos mal etiquetados en el conjunto final de entrenamiento que las técnicas existentes.
Qué significa esto para la seguridad cotidiana
Para un lector no especialista, la conclusión es sencilla: si enseñas a un sistema de seguridad con ejemplos llenos de errores, cometerá errores en el mundo real. SilentSentinel actúa como un editor meticuloso que revisa un conjunto de datos de entrenamiento ruidoso, verifica cada ejemplo frente a sus vecinos y frente a dos redes “revisoras” independientes, y corrige o descarta las entradas sospechosas antes de que comience el aprendizaje principal. Al hacerlo, permite que los modelos de detección de intrusiones tengan una imagen más clara de cómo se ven de verdad el tráfico normal y el malicioso, incluso cuando las etiquetas originales son poco fiables. El resultado final es un defensor en el borde de la red más estable y digno de confianza, que mantiene un buen rendimiento incluso cuando los datos de los que aprende están lejos de ser perfectos.
Cita: Zhao, R., Ding, J., Dong, Q. et al. Mitigating label noise in network intrusion detection via graph-based sample selection and purification. Sci Rep 16, 11674 (2026). https://doi.org/10.1038/s41598-026-45988-y
Palabras clave: detección de intrusiones en redes, ruido de etiquetas, aprendizaje basado en grafos, etiquetas ruidosas, detección de tráfico malicioso