Clear Sky Science · sv
Minska problem med etikettbrus i nätverksintrångsdetektion via grafbaserat urval och rening av prover
Varför renare etiketter spelar roll för cybersäkerhet
Varje dag bevakar säkerhetssystem flöden av internettrafik för att försöka upptäcka de få skadliga anslutningarna som gömmer sig bland miljontals normala. Dessa system förlitar sig i allt större utsträckning på maskininlärning, som lär sig från tidigare exempel märkta som “säkra” eller “attack”. Men om många av de etiketter som används är felaktiga kan även kraftfulla modeller bli vilseledda, vilket gör nätverk mer sårbara än det verkar. Denna artikel presenterar SilentSentinel, en metod utformad för att rensa upp sådana etiketter innan träning, så att intrångsdetektorer kan lära sig från data de faktiskt kan lita på.
Det dolda problemet med felaktiga etiketter
Att bygga bra intrångsdetektionssystem börjar med data, och där uppstår ofta problemen. För att få fram ”skadlig” trafik kör forskare ofta skadlig kod i kontrollerade miljöer och märker allt som genereras som skadligt. I verkligheten är mycket av den trafiken helt normal, så ofarliga anslutningar blir felaktigt märkta som attacker. Automatiserade detektionsverktyg som används för märkning kan också fela, särskilt mot nya, aldrig tidigare sedda hot. Dessa misstag skapar ”etikettbrus”, en situation där många prover i en datamängd bär fel tagg. När bruset blir stort och attacker är sällsynta jämfört med normal trafik får standardmetoder för träning problem: modeller börjar memorera fel, deras beslutsgränser förskjuts åt fel håll och detektionsprecisionen sjunker markant.
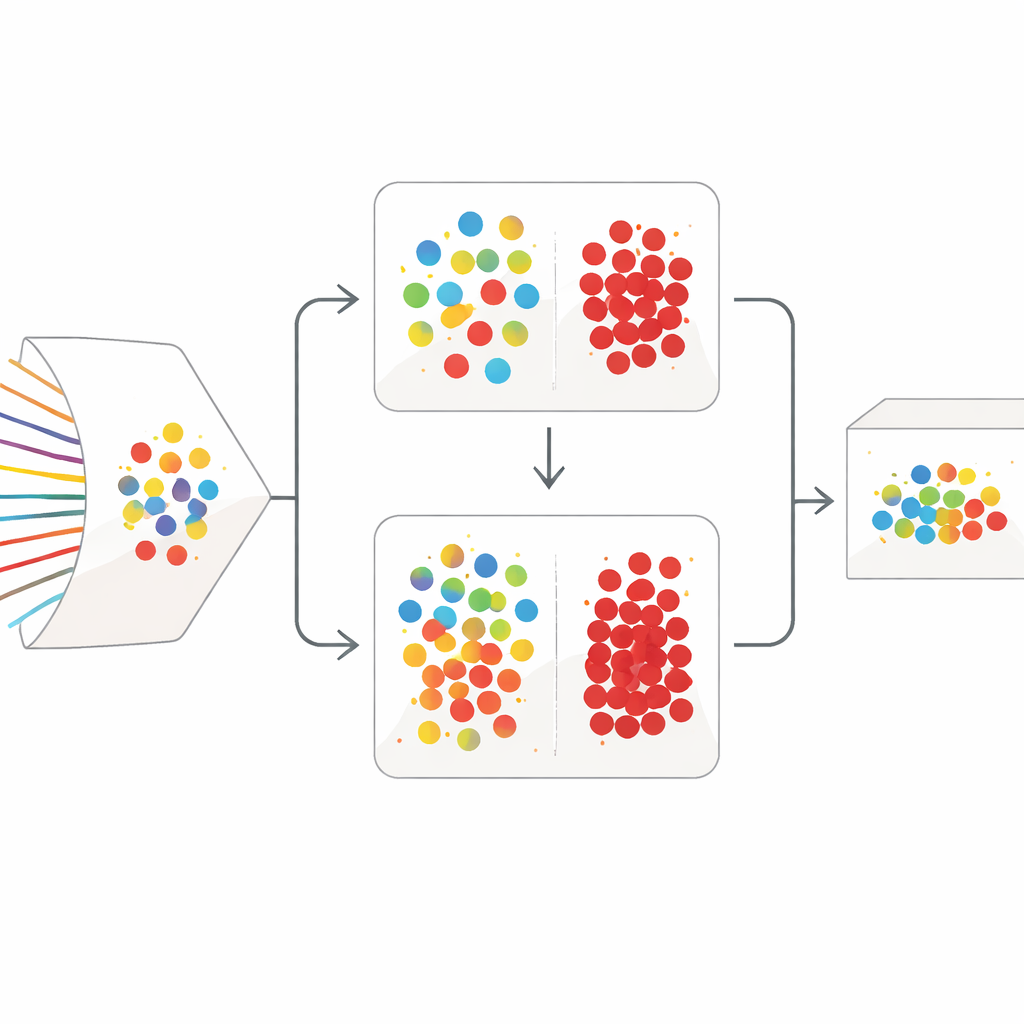
En tvåstegsstrategi för rensning
SilentSentinel angriper problemet med ett datacentriskt förhållningssätt: istället för att enbart försöka göra modellen mer robust, arbetar metoden först med att åtgärda träningsdata. Den centrala iakttagelsen är att nätverksflöden som kommer från samma verkliga beteende tenderar att se lika ut i ett feature-utrymme, oavsett om de verkligen är normala eller skadliga. SilentSentinels första modul, kallad Normal Sample Discovery (NSD), letar efter trafikprover som modellen är mycket säker på, antar att deras etiketter är korrekta, och använder sedan deras likhetsrelationer för att ometikettera deras grannar. Detta görs genom att bygga en graf där varje punkt är ett flöde och kanter förbinder flöden som beter sig lika. Etiketterna från den förtroendefulla kärnan sprider sig över grafen, och endast prover vars nya etiketter är mycket konsekventa behålls som ”rena”. Dessa blir ankare för träningen, särskilt för den dominerande normala trafiken.
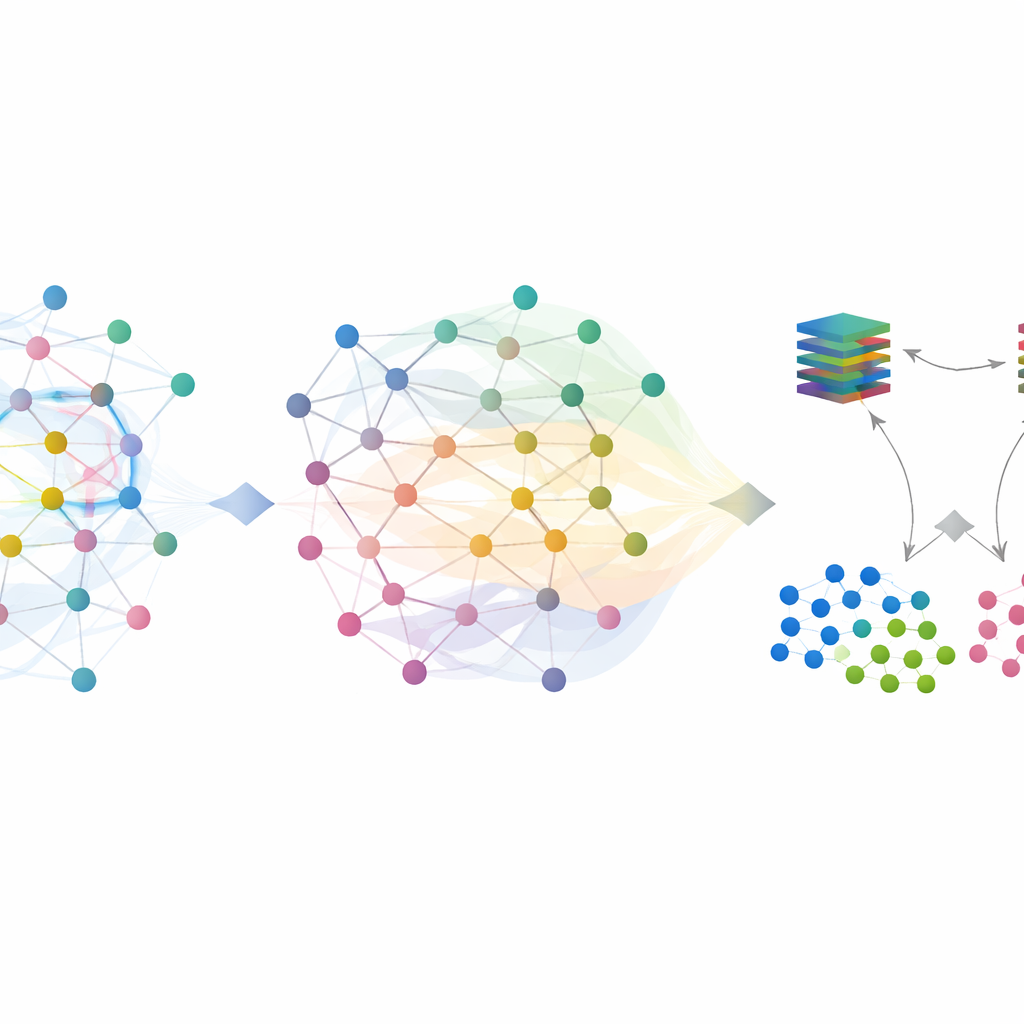
Fokusering på sällsynta attacker
Normal trafik dominerar verkliga datamängder, men de sällsynta, verkligt skadliga flödena är de som betyder mest. Många av dem förblir osäkra efter det första grafbaserade steget. För att hantera detta lägger SilentSentinel till en andra modul, Malicious Sample Screening (MSS). Här lär sig två neurala nätverk med samma arkitektur men olika startvillkor tillsammans. Varje nätverk väljer, i varje träningssteg, de delmängder av prover det anser mest tillförlitliga och delar dem med det andra nätverket. Med tiden fokuserar detta fram-och-tillbaka-lärande på exempel som båda nätverken är överens om och filtrerar gradvis bort de som sannolikt är felmärkta. En särskilt utvald förlustfunktion hjälper till att förhindra att den överväldigande majoritetsklassen tränger undan de knappa attackproven, vilket gör den slutliga uppsättningen skadliga exempel både renare och mer informativ.
Att pröva systemet
Författarna utvärderade SilentSentinel på två mycket använda intrångsdatamängder: CIC-IDS2017, som täcker många typer av klassiska attacker, och DoHBrw-2020, som fokuserar på krypterad DNS-over-HTTPS-trafik. De simulerade realistiska förhållanden genom att avsiktligt vända en betydande andel etiketter, upp till 40 procent, och jämförde SilentSentinel med flera ledande metoder som syftar till att hantera brusiga data. Både under symmetriska och asymmetriska brusscenarier uppnådde SilentSentinel konsekvent högre F1-poäng, en balans mellan precision och recall. På den mer utmanande CIC-IDS2017-datan förbättrade den prestandan med över 17 procent jämfört med den bästa konkurrerande metoden vid hög brusnivå. På DoHBrw höll den prestandan nära perfekt även när etikettbruset ökade, medan konkurrerande metoder försämrades märkbart. Ytterligare analys visade att SilentSentinel lämnade betydligt färre felmärkta prover i den slutliga träningsuppsättningen än befintliga tekniker.
Vad detta betyder för vardaglig säkerhet
För en lekman är slutsatsen enkel: om du lär upp ett säkerhetssystem med exempel fulla av misstag kommer det att göra misstag i verkligheten. SilentSentinel fungerar som en noggrann redaktör som går igenom en brusig träningsdatamängd, jämför varje exempel med dess grannar och med två oberoende ”gransknings”-nätverk, och rättar eller kasserar misstänkta poster innan den egentliga inlärningen börjar. Genom att göra detta låter den intrångsdetektionsmodeller se en tydligare bild av hur normal och skadlig trafik verkligen ser ut, även när de ursprungliga etiketterna är opålitliga. Slutresultatet är en mer stabil och pålitlig försvarare vid nätverkets gräns — en som fortsätter att prestera väl även när datan den lär sig från är långt ifrån perfekt.
Citering: Zhao, R., Ding, J., Dong, Q. et al. Mitigating label noise in network intrusion detection via graph-based sample selection and purification. Sci Rep 16, 11674 (2026). https://doi.org/10.1038/s41598-026-45988-y
Nyckelord: nätverksintrångsdetektion, etikettbrus, grafbaserat lärande, brusiga etiketter, detektion av skadlig trafik