Clear Sky Science · fr
Atténuer le bruit d’étiquetage dans la détection d’intrusions réseau via sélection et purification d’échantillons basées sur un graphe
Pourquoi des étiquettes plus propres comptent pour la cybersécurité
Chaque jour, les systèmes de sécurité surveillent des flux massifs de trafic internet pour repérer les rares connexions malveillantes parmi des millions de connexions normales. Ces systèmes reposent de plus en plus sur l’apprentissage automatique, qui apprend à partir d’exemples passés étiquetés « sûr » ou « attaque ». Mais si beaucoup de ces étiquettes sont erronées, même des modèles puissants peuvent être induits en erreur, laissant les réseaux plus vulnérables qu’il n’y paraît. Cet article présente SilentSentinel, une méthode conçue pour nettoyer ces étiquettes avant l’entraînement, afin que les détecteurs d’intrusion apprennent à partir de données en lesquelles ils peuvent réellement avoir confiance.
Le problème caché des étiquettes erronées
La construction de bons systèmes de détection d’intrusion commence par les données, et c’est là que les choses se gâtent. Pour obtenir du trafic « malveillant », les chercheurs exécutent souvent des logiciels malveillants dans des environnements contrôlés et étiquettent comme nuisible tout ce qu’ils génèrent. En réalité, une grande partie de ce trafic est parfaitement normale, si bien que des connexions inoffensives sont à tort marquées comme des attaques. Les outils automatiques de détection d’intrusion utilisés pour l’étiquetage se trompent aussi, notamment face à des menaces nouvelles ou inédites. Ces erreurs créent un « bruit d’étiquetage », situation où de nombreux échantillons d’un jeu de données portent une étiquette incorrecte. Quand le bruit est important et que les attaques sont rares par rapport au trafic normal, les méthodes d’entraînement standard peinent : les modèles commencent à mémoriser les erreurs, leurs frontières de décision se déplacent dans la mauvaise direction, et la précision de détection chute fortement.
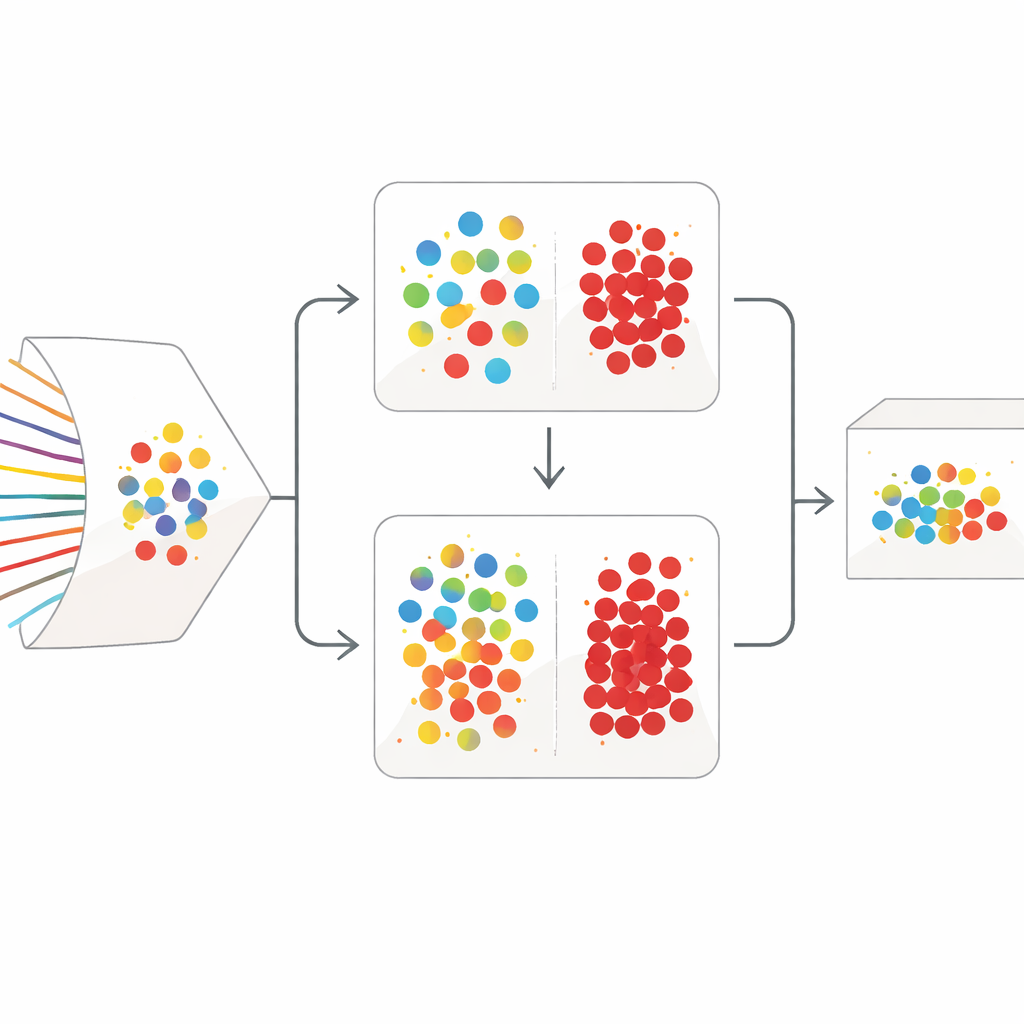
Une stratégie de nettoyage en deux étapes
SilentSentinel s’attaque au problème par une approche centrée sur les données : au lieu de se contenter de rendre le modèle plus robuste, il travaille d’abord à corriger les données d’entraînement. L’observation clé est que les flux réseau issus du même comportement réel tendent à se ressembler dans un espace de caractéristiques, qu’ils soient réellement normaux ou malveillants. Le premier module de SilentSentinel, appelé Découverte d’Échantillons Normaux (DEN), repère les échantillons de trafic pour lesquels le modèle est très confiant, suppose que leurs étiquettes sont correctes, puis utilise leurs relations de similarité pour réétiqueter leurs voisins. Cela se fait en construisant un graphe où chaque point représente un flux et les arêtes relient des flux au comportement similaire. Les étiquettes du noyau confiant se propagent sur ce graphe, et seuls les échantillons dont les nouvelles étiquettes sont hautement cohérentes sont conservés comme « propres ». Ceux-ci servent d’ancres pour l’entraînement, en particulier pour l’abondant trafic normal.
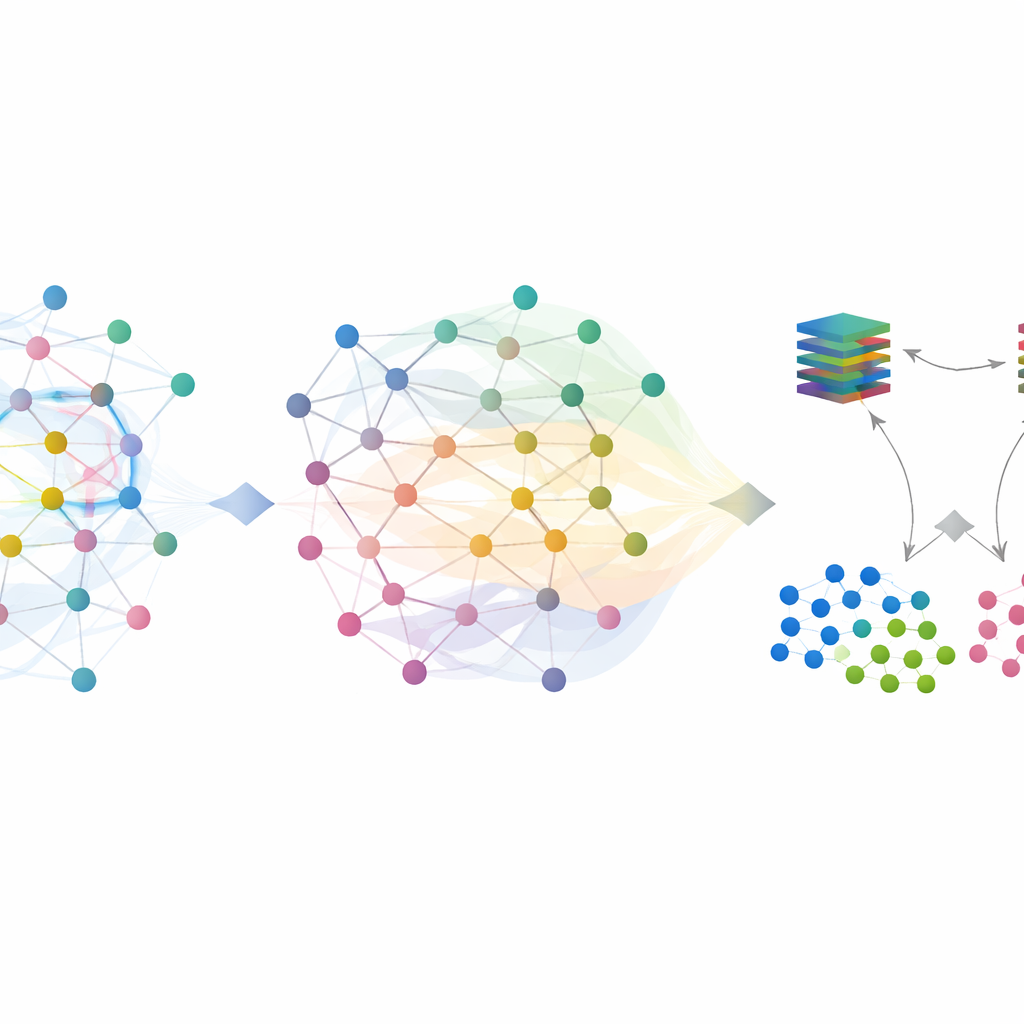
Se concentrer sur les attaques rares
Le trafic normal domine les jeux de données réels, mais les flux réellement malveillants et rares sont ceux qui comptent le plus. Beaucoup d’entre eux restent incertains après le premier passage basé sur le graphe. Pour les traiter, SilentSentinel ajoute un second module, le Filtrage d’Échantillons Malveillants (FEM). Ici, deux réseaux neuronaux de même architecture mais d’initialisations différentes apprennent ensemble. À chaque étape d’entraînement, chaque réseau sélectionne les sous-ensembles d’échantillons qu’il juge les plus fiables et les partage avec l’autre. Au fil du temps, cet enseignement réciproque se concentre sur des exemples sur lesquels les deux réseaux s’accordent et filtre progressivement ceux susceptibles d’être mal étiquetés. Une fonction de perte choisie spécialement aide à empêcher que la classe majoritaire écrasante n’étouffe les rares échantillons d’attaque, rendant l’ensemble final d’exemples malveillants à la fois plus pur et plus informatif.
Évaluation du système
Les auteurs ont évalué SilentSentinel sur deux jeux de données d’intrusion largement utilisés : CIC-IDS2017, qui couvre de nombreux types d’attaques classiques, et DoHBrw-2020, qui se concentre sur le trafic chiffré DNS-over-HTTPS. Ils ont simulé des conditions réalistes en inversant délibérément une fraction substantielle des étiquettes, jusqu’à 40 %, et ont comparé SilentSentinel à plusieurs méthodes de pointe destinées à gérer des données bruitées. Dans des scénarios de bruit symétrique et asymétrique, SilentSentinel a systématiquement obtenu des scores F1 plus élevés, un compromis entre précision et rappel. Sur le jeu plus difficile CIC-IDS2017, il a amélioré les performances de plus de 17 % par rapport à la meilleure approche concurrente sous fort bruit. Sur DoHBrw, il a maintenu des performances proches de la perfection même lorsque le bruit d’étiquetage augmentait, tandis que les méthodes rivales se détérioraient nettement. Des analyses supplémentaires ont montré que SilentSentinel laissait beaucoup moins d’échantillons mal étiquetés dans l’ensemble d’entraînement final que les techniques existantes.
Ce que cela signifie pour la sécurité quotidienne
Pour le grand public, la conclusion est simple : si vous enseignez à un système de sécurité à partir d’exemples truffés d’erreurs, il commettra des erreurs dans le monde réel. SilentSentinel joue le rôle d’un éditeur attentif qui parcourt un jeu de données d’entraînement bruité, recoupe chaque exemple avec ses voisins et avec deux réseaux « réviseurs » indépendants, et corrige ou écarte les entrées suspectes avant le démarrage de l’apprentissage principal. Ce faisant, il permet aux modèles de détection d’intrusion de mieux distinguer ce à quoi ressemblent réellement le trafic normal et le trafic malveillant, même lorsque les étiquettes d’origine sont peu fiables. Le résultat final est un défenseur de la périphérie réseau plus stable et digne de confiance — capable de conserver de bonnes performances même lorsque les données d’apprentissage sont loin d’être parfaites.
Citation: Zhao, R., Ding, J., Dong, Q. et al. Mitigating label noise in network intrusion detection via graph-based sample selection and purification. Sci Rep 16, 11674 (2026). https://doi.org/10.1038/s41598-026-45988-y
Mots-clés: détection d’intrusion réseau, bruit d’étiquetage, apprentissage basé sur les graphes, étiquettes bruitées, détection de trafic malveillant