Clear Sky Science · de
Reduzierung von Label-Rauschen bei der Netzwerkeindrückungserkennung durch graphbasierte Stichprobenauswahl und Reinigung
Warum sauberere Labels für Cybersecurity wichtig sind
Tagtäglich beobachten Sicherheitssysteme Ströme von Internetverkehr und versuchen, die wenigen bösartigen Verbindungen unter Millionen normaler zu erkennen. Diese Systeme verlassen sich zunehmend auf maschinelles Lernen, das aus vergangenen Beispielen lernt, die als „sicher“ oder „Angriff“ gekennzeichnet sind. Wenn jedoch viele dieser Labels falsch sind, können selbst leistungsfähige Modelle in die Irre geführt werden und Netzwerke anfälliger bleiben, als es scheint. Dieses Papier stellt SilentSentinel vor, eine Methode, die diese Labels vor dem Training bereinigt, sodass Eindringungserkennungs‑Systeme aus Daten lernen können, denen sie tatsächlich vertrauen dürfen.
Das verborgene Problem falscher Labels
Der Aufbau guter Eindringungserkennungssysteme beginnt mit Daten – und genau hier entstehen Fehler. Um „bösartigen“ Verkehr zu erhalten, lassen Forscher oft Malware in kontrollierten Umgebungen laufen und kennzeichnen alles, was erzeugt wird, als bösartig. In Wirklichkeit ist ein großer Teil dieses Verkehrs vollkommen normal, sodass harmlose Verbindungen fälschlich als Angriffe markiert werden. Automatisierte Werkzeuge zur Kennzeichnung können ebenfalls Fehlfunktionen zeigen, insbesondere bei neuen, zuvor unbekannten Bedrohungen. Diese Fehler erzeugen sogenanntes „Label-Rauschen“, also Datensätze, in denen viele Proben das falsche Etikett tragen. Wenn das Rauschen hoch ist und Angriffe im Vergleich zum normalen Verkehr selten sind, haben Standard‑Trainingsverfahren Schwierigkeiten: Modelle beginnen, Fehler zu memorisieren, ihre Entscheidungsgrenzen verschieben sich in die falsche Richtung, und die Erkennungsgenauigkeit sinkt deutlich.
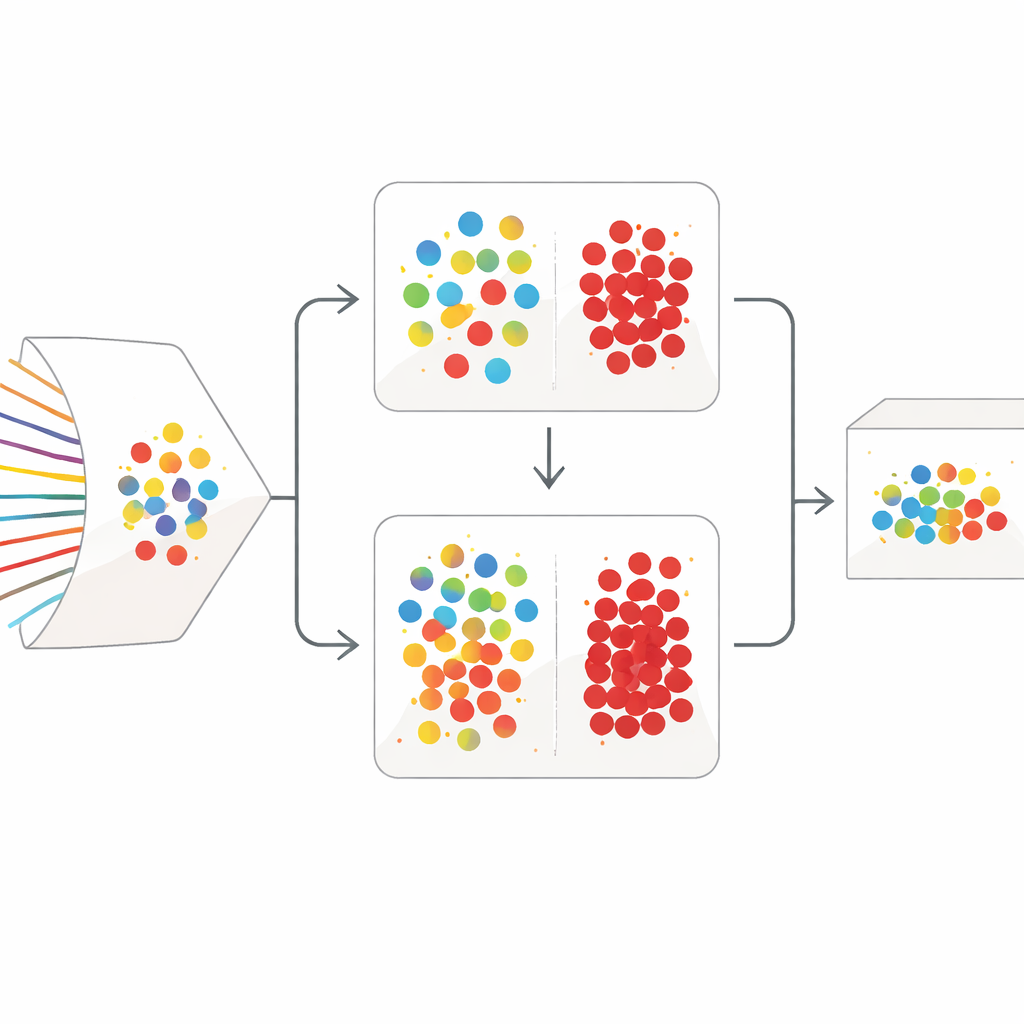
Eine zweistufige Bereinigungsstrategie
SilentSentinel begegnet diesem Problem mit einem datenorientierten Ansatz: Anstatt nur zu versuchen, das Modell selbst robuster zu machen, arbeitet die Methode zunächst daran, die Trainingsdaten zu korrigieren. Die zentrale Beobachtung ist, dass Netzwerkflüsse, die vom selben realen Verhalten stammen, im Merkmalsraum ähnlich aussehen, unabhängig davon, ob sie tatsächlich normal oder bösartig sind. Das erste Modul von SilentSentinel, Normal Sample Discovery (NSD), sucht Verkehrsproben, bei denen das Modell sehr zuversichtlich ist, geht von korrekten Labels aus und verwendet dann Ähnlichkeitsbeziehungen, um die Nachbarn umzukennzeichnen. Dazu wird ein Graph aufgebaut, in dem jeder Punkt einen Flow darstellt und Kanten Flows verbinden, die sich ähnlich verhalten. Labels aus dem zuversichtlichen Kern breiten sich über diesen Graphen aus, und nur Proben, deren neue Labels hoch konsistent sind, werden als „sauber“ behalten. Diese dienen als Anker für das Training, insbesondere für den reichlich vorhandenen normalen Verkehr.
Fokussierung auf seltene Angriffe
Normaler Verkehr dominiert reale Datensätze, doch die seltenen, tatsächlich bösartigen Flows sind die wichtigsten. Viele von ihnen bleiben nach dem ersten graphbasierten Durchgang unsicher. Um damit umzugehen, fügt SilentSentinel ein zweites Modul hinzu, Malicious Sample Screening (MSS). Hier lernen zwei neuronale Netze mit derselben Architektur, aber unterschiedlichen Startparametern gemeinsam. Jedes Netzwerk wählt in jedem Trainingsschritt die Teilmengen von Proben aus, die es für am vertrauenswürdigsten hält, und teilt diese mit dem anderen. Im Laufe der Zeit konzentriert sich dieses Wechselspiel auf Beispiele, bei denen beide Netze übereinstimmen, und filtert allmählich solche heraus, die wahrscheinlich falsch gekennzeichnet sind. Eine speziell gewählte Verlustfunktion verhindert, dass die überwältigende Mehrheitsklasse die knappen Angriffssamples erdrückt, sodass die finale Menge bösartiger Beispiele sowohl reiner als auch informativer wird.
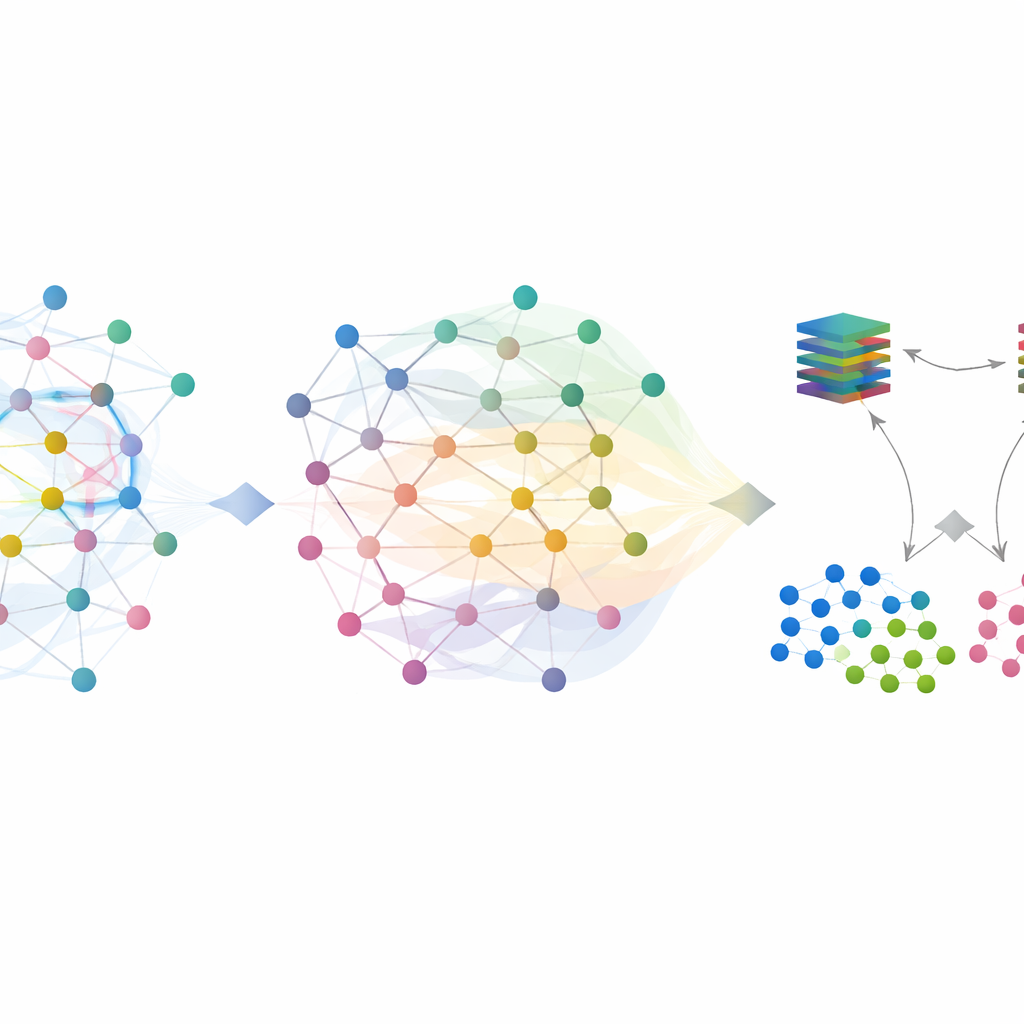
Evaluation des Systems
Die Autoren bewerteten SilentSentinel auf zwei weit verbreiteten Eindringungsdatensätzen: CIC-IDS2017, das viele klassische Angriffstypen abdeckt, und DoHBrw-2020, das sich auf verschlüsselten DNS-over-HTTPS‑Verkehr konzentriert. Sie simulierten realistische Bedingungen, indem sie absichtlich einen erheblichen Anteil der Labels – bis zu 40 Prozent – vertauschten, und verglichen SilentSentinel mit mehreren führenden Methoden zum Umgang mit verrauschten Daten. Sowohl bei symmetrischem als auch asymmetrischem Rauschen erzielte SilentSentinel durchgängig höhere F1‑Werte, einen Ausgleich von Precision und Recall. Auf den anspruchsvolleren CIC-IDS2017‑Daten verbesserte es die Leistung unter hohem Rauschen um mehr als 17 Prozent gegenüber dem besten konkurrierenden Ansatz. Auf DoHBrw hielt es die Leistung nahezu perfekt, selbst bei zunehmendem Label-Rauschen, während konkurrierende Methoden merklich schlechter wurden. Weitere Analysen zeigten, dass SilentSentinel in der finalen Trainingsmenge deutlich weniger falsch gekennzeichnete Proben ließ als bestehende Techniken.
Was das für den Alltag bedeutet
Für Laien ist die Schlussfolgerung einfach: Wenn man ein Sicherheitssystem mit Beispielen trainiert, die voller Fehler sind, wird es in der Praxis Fehler machen. SilentSentinel wirkt wie ein sorgfältiger Redakteur, der einen verrauschten Trainingsdatensatz durchliest, jedes Beispiel mit seinen Nachbarn und mit zwei unabhängigen „Prüfnetzwerken“ abgleicht und verdächtige Einträge vor dem eigentlichen Lernen korrigiert oder verwirft. Dadurch bekommen Eindringungserkennungsmodelle ein klareres Bild davon, wie normaler und bösartiger Verkehr tatsächlich aussehen, selbst wenn die ursprünglichen Labels unzuverlässig sind. Das Ergebnis ist ein stabilerer und vertrauenswürdiger Verteidiger am Netzwerkrand – einer, der auch dann gut funktioniert, wenn die Trainingsdaten alles andere als perfekt sind.
Zitation: Zhao, R., Ding, J., Dong, Q. et al. Mitigating label noise in network intrusion detection via graph-based sample selection and purification. Sci Rep 16, 11674 (2026). https://doi.org/10.1038/s41598-026-45988-y
Schlüsselwörter: Netzwerkeindrückungserkennung, Label-Rauschen, graphbasierte Lernverfahren, verrauschte Labels, Erkennung bösartigen Verkehrs