Clear Sky Science · ja
グラフベースのサンプル選別と精製によるネットワーク侵入検知におけるラベルノイズの緩和
サイバーセキュリティでより正確なラベルが重要な理由
セキュリティシステムは日々、膨大なインターネットトラフィックの流れを監視し、数百万件の正常な通信の中に紛れたわずかな悪性接続を探し出そうとしています。これらのシステムはますます機械学習に依存しており、「安全」や「攻撃」とラベル付けされた過去の事例から学びます。しかし、そのラベルの多くが誤っていると、強力なモデルであっても誤導され、ネットワークは見かけよりも脆弱になります。本稿では、学習前にラベルを浄化することで侵入検知器が信頼できるデータから学べるようにする手法、SilentSentinelを紹介します。
見落とされがちな誤ラベルの問題
良好な侵入検知システムを構築するにはデータが出発点であり、そこに問題が生じます。「悪性」トラフィックを得るために研究者はしばしば制御環境下でマルウェアを実行し、その生成するすべての通信を悪性とラベル付けします。実際にはその多くが正常な通信であり、無害な接続が誤って攻撃とタグ付けされることがよくあります。ラベル付けに用いる自動化された侵入検知ツールも、新しい未知の脅威に直面すると誤動作することがあります。これらの誤りは「ラベルノイズ」を生み出し、データセット内の多くのサンプルが誤ったタグを持つ状態になります。ノイズが高く、攻撃が正常トラフィックに比べて希少な場合、標準的な学習手法は苦戦します:モデルは誤りを記憶し始め、判断境界が誤った方向にずれ、検出精度が急激に低下します。
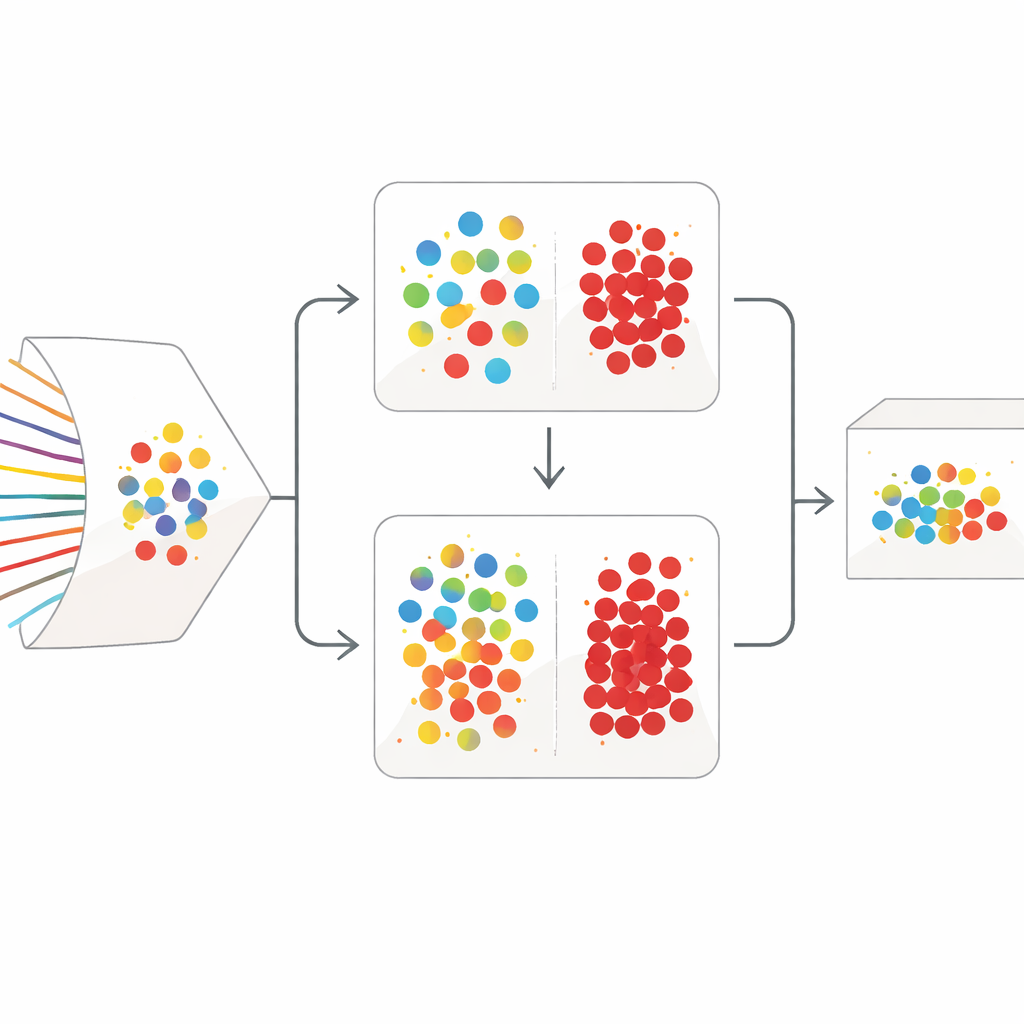
二段階のデータ浄化戦略
SilentSentinelはデータ中心のアプローチでこの問題に対処します:モデル自体を堅牢にするだけでなく、まず訓練データを修正することに取り組みます。重要な観察は、現実世界の同じ振る舞いに由来するネットワークフローは、真に正常であれ真に悪性であれ、特徴空間上で類似して見える傾向があるという点です。SilentSentinelの第1モジュールであるNormal Sample Discovery(NSD)は、モデルが非常に確信を持っているトラフィックサンプルを見つけ、それらのラベルを正しいと仮定し、類似関係を用いて近傍のラベルを再付与します。これは各点をフローとし、振る舞いが似たフロー同士を辺でつなぐグラフを構築することで行われます。確信のあるコアからラベルがこのグラフに広がり、新しいラベルが高い一貫性を示すサンプルのみが「クリーン」として保持されます。これらが訓練のアンカーとなり、特に多数を占める正常トラフィックに対して有用です。
希少な攻撃に焦点を合わせる
実際のデータセットでは正常トラフィックが支配的ですが、真に重要なのは希少な悪性フローです。その多くは最初のグラフベースの処理の後でも不確かさが残ります。これに対処するため、SilentSentinelは2つ目のモジュール、Malicious Sample Screening(MSS)を追加します。ここでは同じ構造だが初期値の異なる2つのニューラルネットワークが共同で学習します。各ネットワークは学習の各ステップで、自身が最も信頼できると判断したサンプルの部分集合を選び、それを相手に共有します。時間とともにこの相互教授は両ネットワークが同意する例に焦点を絞り、誤ラベルの可能性が高いものを徐々に除外します。特別に選ばれた損失関数は、多数派クラスが希少な攻撃サンプルを圧倒してしまうのを防ぎ、最終的な悪性サンプル集合をより純度が高く、情報量の多いものにします。
システムの実証評価
著者らはSilentSentinelを2つの広く使われる侵入検知データセットで評価しました:多種類の古典的攻撃を含むCIC-IDS2017と、暗号化されたDNS-over-HTTPSトラフィックに焦点を当てたDoHBrw-2020です。彼らは現実的な条件を模擬するためにラベルのかなりの割合(最大40%)を意図的に反転させ、ノイズに対処することを目指した複数の先行手法と比較しました。対称ノイズ・非対称ノイズの両条件で、SilentSentinelは常により高いF1スコア(適合率と再現率のバランス)を達成しました。特にノイズが高いCIC-IDS2017では、最良の競合手法に比べて性能を17%以上向上させました。DoHBrwではラベルノイズが増加しても性能をほぼ完璧に維持した一方で、他手法は目に見えて劣化しました。さらなる解析から、SilentSentinelは最終的な訓練セットに残る誤ラベルの数が既存手法よりもはるかに少ないことが示されました。
日常のセキュリティにとっての意味
一般向けの要点は明快です:誤りだらけの事例からシステムを教育すれば、実運用でも誤りを犯します。SilentSentinelはノイズの多い訓練データセットを注意深く読み直す編集者のように機能し、各例を近傍や2つの独立した「査読者」ネットワークと突き合わせて、疑わしい項目を修正または破棄してから本格的な学習を開始します。こうして、元のラベルが信頼できない場合でも、侵入検知モデルが正常トラフィックと悪性トラフィックの実際の姿をより明確に把握できるようになります。結果として、学習元データが完璧でなくても安定して信頼できるネットワーク境界の守護者が実現します。
引用: Zhao, R., Ding, J., Dong, Q. et al. Mitigating label noise in network intrusion detection via graph-based sample selection and purification. Sci Rep 16, 11674 (2026). https://doi.org/10.1038/s41598-026-45988-y
キーワード: ネットワーク侵入検知, ラベルノイズ, グラフベース学習, ノイズラベル, 悪性トラフィック検出