Clear Sky Science · pl
Łagodzenie szumów etykiet w wykrywaniu włamań w sieci za pomocą doboru próbek i oczyszczania opartych na grafie
Dlaczego czystsze etykiety mają znaczenie dla cyberbezpieczeństwa
Codziennie systemy zabezpieczeń obserwują potoki ruchu internetowego, próbując wyłapać nieliczne złośliwe połączenia ukryte wśród milionów normalnych. Systemy te coraz częściej opierają się na uczeniu maszynowym, które uczy się na podstawie wcześniejszych przykładów oznaczonych jako „bezpieczne” lub „atak”. Jeśli jednak wiele z tych etykiet jest błędnych, nawet potężne modele mogą zostać wprowadzone w błąd, pozostawiając sieci bardziej podatne niż się wydaje. W artykule przedstawiono SilentSentinel — metodę zaprojektowaną do oczyszczania tych etykiet przed treningiem, tak aby detektory włamań uczyły się na danych, którym można naprawdę zaufać.
Ukryty problem błędnych etykiet
Budowa dobrych systemów wykrywania włamań zaczyna się od danych i to właśnie tam pojawiają się problemy. Aby uzyskać ruch „złośliwy”, badacze często uruchamiają malware w kontrolowanych środowiskach i oznaczają wszystko, co ono generuje, jako szkodliwe. W rzeczywistości znaczna część takiego ruchu jest całkowicie normalna, więc nieszkodliwe połączenia są błędnie oznaczane jako ataki. Zautomatyzowane narzędzia do wykrywania włamań używane do etykietowania także mogą się mylić, zwłaszcza w obliczu nowych, wcześniej nieznanych zagrożeń. Te błędy tworzą „szum etykiet” — sytuację, w której wiele próbek w zbiorze danych ma nieprawidłowe oznaczenie. Gdy poziom szumu rośnie, a ataki są rzadkie w porównaniu z ruchem normalnym, standardowe metody treningowe mają trudności: modele zaczynają zapamiętywać błędy, ich granice decyzyjne przesuwają się w złym kierunku, a dokładność wykrywania gwałtownie spada.
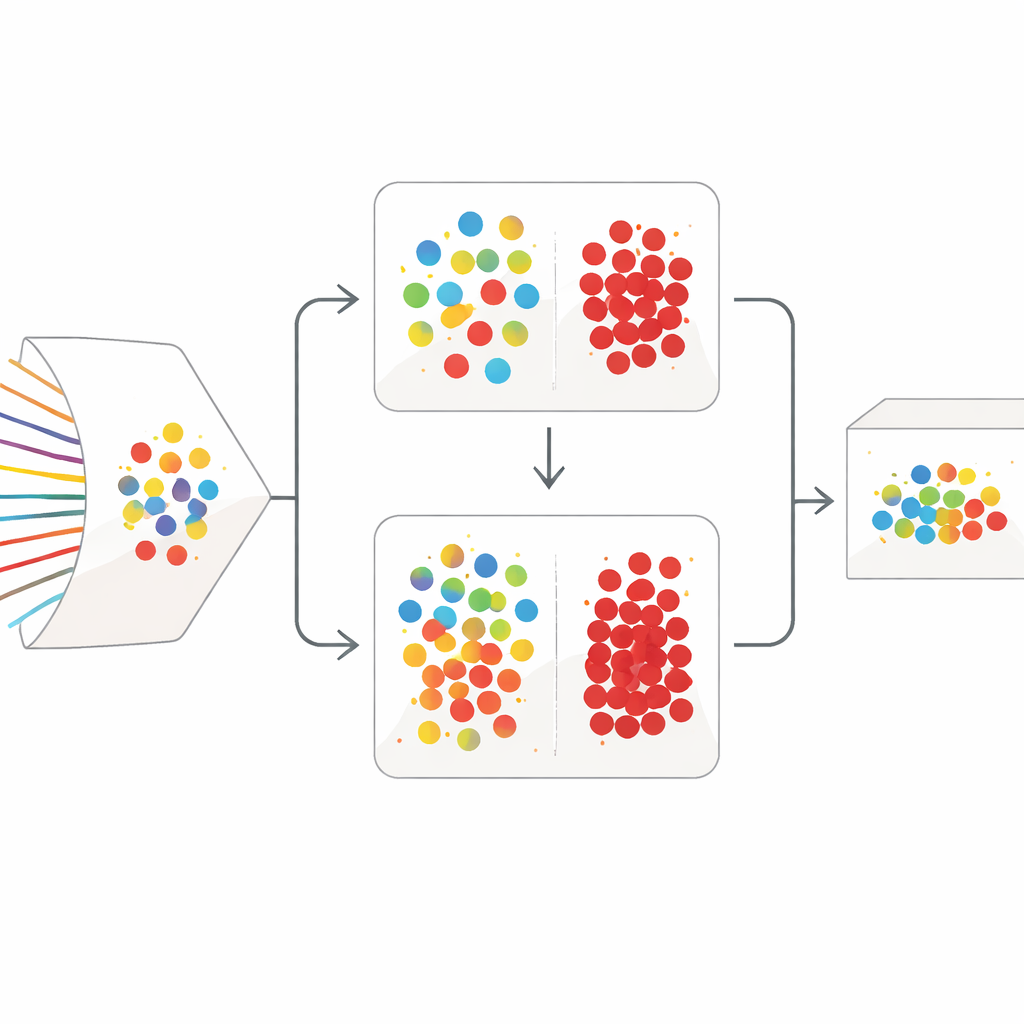
Strategia oczyszczania w dwóch etapach
SilentSentinel rozwiązuje ten problem podejściem skoncentrowanym na danych: zamiast jedynie wzmacniać odporność samego modelu, najpierw pracuje nad poprawą danych treningowych. Kluczowa obserwacja jest taka, że przepływy sieciowe wynikające z tego samego rzeczywistego zachowania mają tendencję do podobieństwa w przestrzeni cech, niezależnie od tego, czy są naprawdę normalne, czy rzeczywiście złośliwe. Pierwszym modułem SilentSentinel jest Normal Sample Discovery (NSD), który wyszukuje próbki ruchu, co do których model jest bardzo pewny, zakłada ich etykiety jako poprawne, a następnie wykorzystuje relacje podobieństwa, by przemianować ich sąsiadów. Robi to, budując graf, w którym każdy punkt to przepływ, a krawędzie łączą przepływy o podobnym zachowaniu. Etykiety z pewnego rdzenia rozprzestrzeniają się po tym grafie i tylko próbki, których nowe etykiety są wysoce spójne, są zachowywane jako „czyste”. Stają się one kotwicami do treningu, zwłaszcza dla licznego ruchu normalnego.
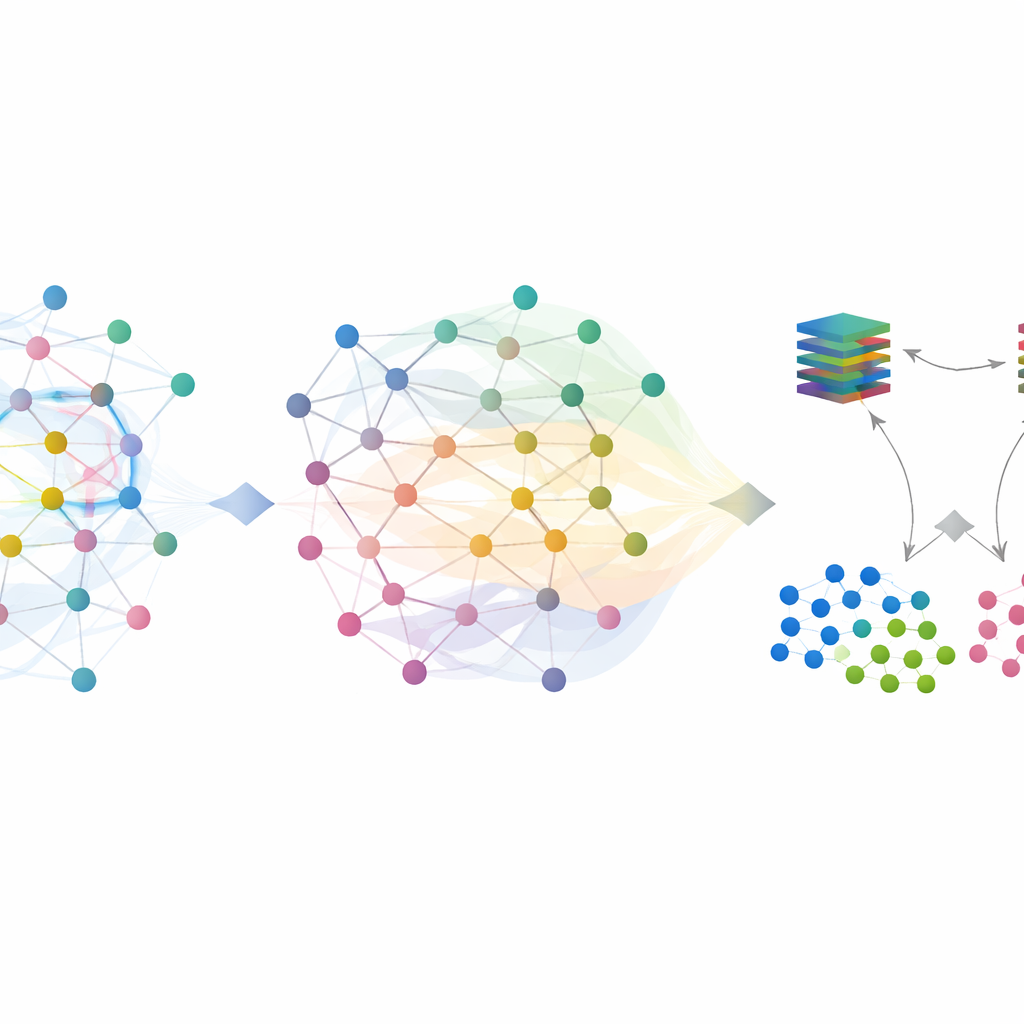
Skupienie na rzadkich atakach
Ruch normalny dominuje w rzeczywistych zbiorach danych, ale to rzadkie, rzeczywiście złośliwe przepływy są najważniejsze. Wiele z nich pozostaje niepewnych po pierwszym, opartym na grafie etapie. Aby sobie z nimi poradzić, SilentSentinel dodaje drugi moduł — Malicious Sample Screening (MSS). Tutaj dwa sieci neuronowe o tej samej strukturze, ale różnych punktach startowych uczą się razem. Każda sieć na każdym kroku treningu wybiera podzbiory próbek, które uważa za najbardziej wiarygodne, i udostępnia je drugiej. Z biegiem czasu to wzajemne nauczanie skupia się na przykładach, co do których obie sieci się zgadzają, i stopniowo filtruje te, które prawdopodobnie są błędnie oznaczone. Specjalnie dobrana funkcja straty pomaga zapobiegać zdominowaniu procesu przez przeważającą klasę większościową, dzięki czemu nieliczne próbki ataków nie zostają zagłuszone, a ostateczny zbiór złośliwych przykładów jest zarówno czystszy, jak i bardziej informatywny.
Testy systemu
Autorzy ocenili SilentSentinel na dwóch powszechnie używanych zbiorach do wykrywania włamań: CIC-IDS2017, obejmującym wiele typów klasycznych ataków, oraz DoHBrw-2020, koncentrującym się na zaszyfrowanym ruchu DNS-over-HTTPS. Zasymulowali realistyczne warunki, celowo zmieniając znaczną część etykiet, aż do 40 procent, i porównali SilentSentinel z kilkoma wiodącymi metodami radzenia sobie z szumem w danych. Zarówno w ustawieniach ze szumem symetrycznym, jak i asymetrycznym, SilentSentinel konsekwentnie osiągał wyższe wartości F1 — miary równowagi precyzji i czułości. Na trudniejszym zbiorze CIC-IDS2017 poprawił wyniki o ponad 17 procent w porównaniu z najlepszym konkurencyjnym podejściem przy dużym poziomie szumu. Na DoHBrw utrzymał wydajność bliską doskonałej nawet wraz ze wzrostem szumu etykiet, podczas gdy metody rywali zauważalnie się pogarszały. Dalsze analizy wykazały, że SilentSentinel pozostawiał znacznie mniej błędnie oznaczonych próbek w ostatecznym zbiorze treningowym niż istniejące techniki.
Co to oznacza dla codziennego bezpieczeństwa
Dla przeciętnego czytelnika przesłanie jest proste: jeśli uczysz system zabezpieczeń na przykładach pełnych błędów, system będzie popełniać błędy w rzeczywistym świecie. SilentSentinel działa jak uważny redaktor, który przegląda zaszumiony zbiór treningowy, porównuje każdy przykład z sąsiadami i dwoma niezależnymi „recenzentami” w postaci sieci, i naprawia lub odrzuca podejrzane wpisy, zanim rozpocznie się właściwe uczenie. Dzięki temu modele wykrywania włamań widzą wyraźniejszy obraz tego, jak naprawdę wygląda ruch normalny i złośliwy, nawet gdy pierwotne etykiety są zawodn e. Efekt końcowy to bardziej stabilny i godny zaufania obrońca na krawędzi sieci — taki, który utrzymuje dobrą skuteczność nawet wtedy, gdy dane, na których się uczy, są dalekie od ideału.
Cytowanie: Zhao, R., Ding, J., Dong, Q. et al. Mitigating label noise in network intrusion detection via graph-based sample selection and purification. Sci Rep 16, 11674 (2026). https://doi.org/10.1038/s41598-026-45988-y
Słowa kluczowe: wykrywanie włamań w sieci, szum etykiet, uczenie oparte na grafach, zanieczyszczone etykiety, wykrywanie złośliwego ruchu