Clear Sky Science · zh
强化驱动发生在试内而非试间的运动适应
练习与奖励如何塑造我们的动作
日常动作如伸手拿咖啡杯或投掷球看起来轻而易举,然而我们的脑子一直在微调这些动作。本文研究提出一个看似简单的问题:当我们练习时,奖励与惩罚是帮助我们在一次动作进行中改进,还是只在一次尝试与下一次尝试之间起作用?答案揭示了动机与自然的试次间动作差异如何共同影响我们学习新动作技能的方式。
大脑从运动误差中学习的两条途径
当我们在新的或改变的情境中移动时,大脑至少有两种学习方式可用。一种在尝试之间更新计划:在看到上一次伸手出错后,我们会微调下一次的瞄准。另一种在单次动作进行时在线调整:当视觉反馈显示手偏离轨迹,控制系统会在动作过程中修正。作者想知道这两条途径是否受到奖励与惩罚的不同影响,以及人们在早期动作中的自然变异是如何促进或阻碍每种情况下的学习。
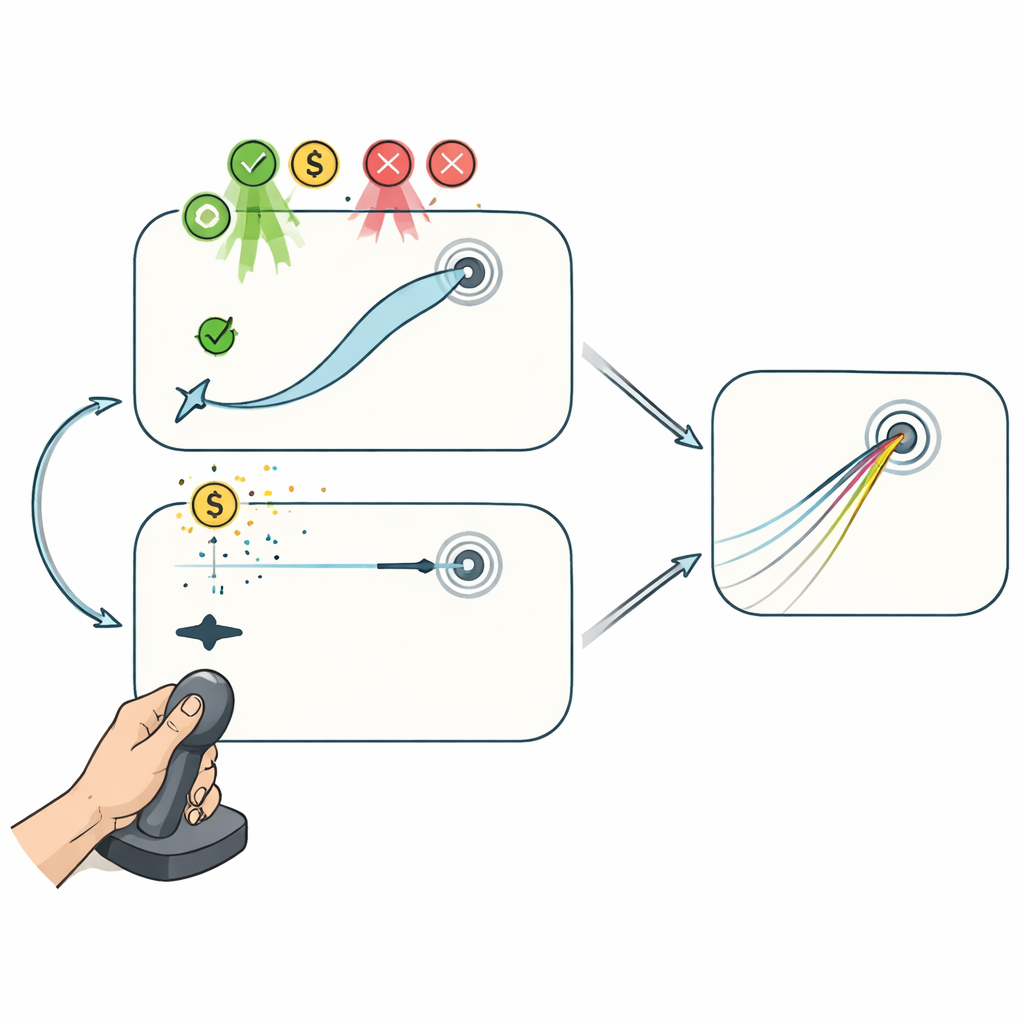
两种操纵杆游戏:有与没有中途修正
为区分这些过程,志愿者在两个基于操纵杆的电脑任务中玩游戏,同时手部运动与光标之间的关联被秘密旋转。在“伸手”任务中,光标忠实地跟随操纵杆,允许玩家在动作过程中弯曲路径以引导光标到目标。这一设置让试间计划和试内修正都能对改进做出贡献。相比之下,在“冰壶”任务中,只有操纵杆动作的最初一段起作用:一旦光标越过短距离,它就沿直线滑行,无法再被影响,类似冰上冰壶的运动。在这里,表现只能通过逐次调整初始计划来改进,而不能通过途中修正错误。
动机提升试内修正,而非仅仅影响计划
在两种游戏中,人们都逐步补偿了视觉旋转,表现出明确的运动适应、重访扰动时的“节省效应”(savings)以及半小时休息后的保持。然而,允许中途修正产生了显著差异:在伸手游戏中,误差缩小更多,学习速率高于冰壶游戏,尽管总体适应的时间进程相似。关键是,与表现相关的奖励与惩罚只改善了伸手任务的结果。不论参与者是因准确动作而获得更多金钱,还是因大误差而失钱,他们的表现都超过了中性反馈组——但仅在能够连续控制光标时如此。当成功纯粹依赖于规划一个良好的初始出手时,强化并未显示出可检测的影响。
规划阶段的有益变异,在修正阶段被抑制
研究者还考察了在首次引入旋转时,参与者早期动作方向的变异程度。在冰壶任务中,早期变异较大的参与者后来学得更多,即使在考虑了快速的初始改进后仍然如此。这表明,当无法修正时,尝试略有不同的计划——作者称之为“规划噪声”——有助于大脑在试次间探索并完善更好的策略。相比之下,在伸手任务中,早期变异主要反映了前几次尝试中的快速误差减少,并不能预测参与者最终的适应程度。由于持续的视觉反馈允许系统实时修正错误,这些早期差异的信息价值似乎被削弱了。
对训练与康复的意义
总体来看,这些结果表明,强化主要增强大脑在动作进行时的修正能力,而我们起始动作的自然变异主要支持发生在试次之间的学习。对于日常训练、运动指导和康复,这意味着当任务允许连续反馈与调整时,奖励或惩罚可能最有效;而在只有初始动作冲动决定成功的情况下,有意识地利用早期尝试中的变异可能尤其有价值。通过分离这两条学习途径,研究有助于解释为何以往关于奖励与惩罚对运动学习影响的研究结果出现不一致,并指向更有针对性的实践设计方式,使其与我们神经系统内建的学习机制协同工作,而非相互抵触。
引用: Lehnberg, F.M., Paul, T., Wiemer, V.M. et al. Reinforcement drives within- not between-trial motor adaptation. Sci Rep 16, 11605 (2026). https://doi.org/10.1038/s41598-026-45293-8
关键词: 运动学习, 强化, 运动变异性, 视运动适应, 运动控制