Clear Sky Science · he
חיזוק מניע התאמות מוטוריות בתוך־אימון ולא בין־אימונים
כיצד תרגול ותגמול מעצבים את תנועותינו
פעולות יומיומיות כמו להושיט יד לכוס קפה או לזרוק כדור נראות ללא מאמץ, אך מוחנו מכוונן את התנועות הללו ללא הרף. המחקר הזה שואל שאלה שמסתירה בפשטותה: כשאנחנו מתאמנים, האם תגמולים ועונשים עוזרים לנו להשתפר בזמן שאנחנו בתנועה אחת, או רק בין ניסיון לניסיון? התשובה חושפת כיצד המוטיבציה ושונות הטבעית בין ניסיונות בשימוש בתנועה משולבים וכיצד הם מעצבים את הלמידה של מיומנויות מוטוריות חדשות.
שתי דרכים שבהן המוח לומד משגיאות תנועה
כשאנחנו נעים בסביבה חדשה או משונה, המוח יכול ללמוד לפחות בשתי דרכים. דרך אחת מעדכנת את התכנון בין ניסיונות: לאחר שמבחינים היכן ההושטה הקודמת נטתה שגויה, אנו משנים בעדינות את המטרה בניסיון הבא. הדרך השנייה מתאמת בזמן אמת בתוך תנועה בודדת: כשהמשוב הוויזואלי מראה שהיד סוטה מהמטרה, מערכות הבקרה מתקנות את התנועה באמצע. החוקרים רצו לדעת האם שתי הדרכים האלה מושפעות באופן שונה מתגמולים ועונשים, והאם השונות הטבעית בתנועות הראשוניות של אנשים מסייעת או מונעת למידה בכל מקרה.
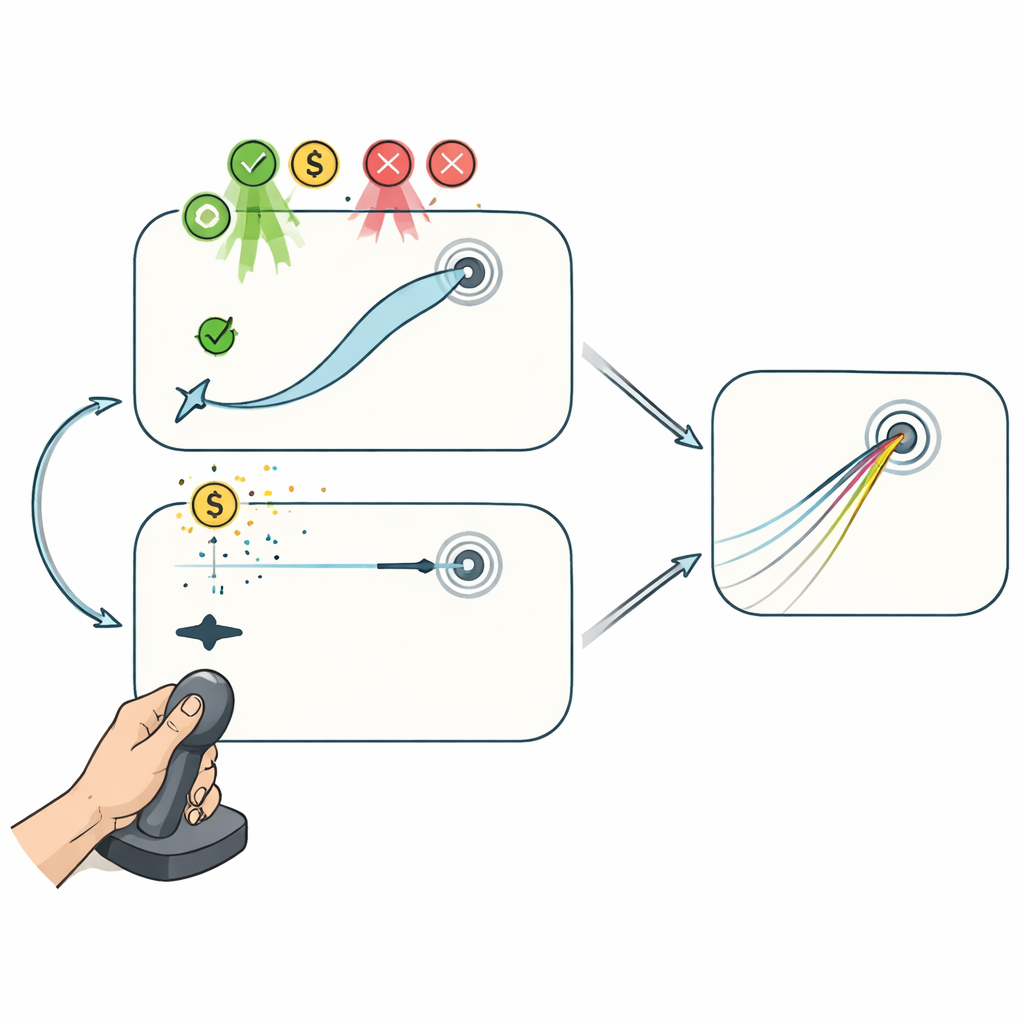
שתי משחקי ג׳ויסטיק: עם ובלי תיקון באמצע הדרך
כדי להפריד בין התהליכים הללו, מתנדבים שיחקו בשני משימות ממוחשבות מבוססות ג׳ויסטיק בעוד הקשר בין תנועת היד לסמןCursor הוסב בסתר. במשימת «ההשגה» (Reaching), הסמן עקב בנאמנות אחר הג׳ויסטיק, מה שאיפשר לשחקנים לעקם את הנתיב במהלך התנועה כדי לנווט אל היעד. תצורה זו מאפשרת הן תכנון בין ניסיונות והן תיקון בתוך־תנועה לתרום לשיפור. במשימת «הקרלינג» (Curling), לעומת זאת, רק תחילת תנועת הג׳ויסטיק השפיעה: ברגע שהסמן עבר מרחק קצר, הוא החלק בקו ישר שלא יכל להיפגע יותר, בדומה לאבן קרלינג על הקרח. כאן, הביצועים יכלו להשתפר רק על ידי התאמת התכנון ההתחלתי מניסיון לניסיון, ולא על ידי תיקון שגיאות בדרך.
מוטיבציה מחזקת תיקון בתוך־התנועה, לא רק תכנון
בשני המשחקים, אנשים באופן הדרגתי פיצו על הסיבוב הוויזואלי, והראו סימני התאמה מוטורית ברורים, חיסכון (savings) כששבו להפרעה ושימור לאחר הפסקה של חצי שעה. עם זאת, האפשרות לתיקונים באמצע הדרך עשתה הבדל משמעותי: במשימת ההשגה, השגיאות הצטמצמו יותר וקצב הלמידה היה גבוה יותר מאשר במשימת הקרלינג, אף על פי שמהלך ההתאמה הכולל היה דומה. באופן מכריע, תגמולים ועונשים הקשורים לביצועים שיפרו תוצאות רק במשימת ההשגה. בין אם המשתתפים הרוויחו יותר כסף עבור תנועות מדויקות או איבדו כסף עבור שגיאות גדולות, ביצועיהם עלו על קבוצת משוב ניטרלי — אך רק כשהם יכלו לנווט את הסמן באופן רציף. כאשר ההצלחה נשענה אך ורק על תכנון יריה התחלתית טובה, לחיזוק לא היה השפעה ניתנת לזיהוי.
שונות מועילה בתכנון, מדוכאת בזמן תיקון
החוקרים גם בחנו עד כמה תנועות ההתחלה של אנשים שונות בכיוון כשהסיבוב הוצג לראשונה. במשימת הקרלינג, משתתפים שהציגו שונות התחלתית גדולה יותר המשיכו ללמוד יותר, גם לאחר התחשבות בשיפורים התחלתיים מהירים. זה מרמז שכאשר תיקונים בלתי אפשריים, ניסוי בתכנונים מעט שונים — מה שהמחברים קוראים לו «רעש תכנון» — עוזר למוח לחקור ולחדד אסטרטגיות טובות יותר בין ניסיונות. במשימת ההשגה, לעומת זאת, השונות הראשונית שיקפה ברובה הקטנה מהירה של שגיאות בתוך הניסיונות הראשונים ולא חיזתה עד כמה אנשים יסתגלו בסופו של דבר. מכיוון שמשוב ויזואלי רציף מאפשר למערכת לתקן שגיאות בזמן אמת, הערך המידע של ההבדלים הראשוניים הללו נדמה כי הוא מדוכא.
מדוע זה חשוב לאימון ושיקום
ביחד, תוצאות אלה מראות שחיזוק בעיקר מחזק את יכולת המוח לתקן תנועות בזמן שהן מתרחשות, בעוד שהשונות הטבעית בדרך שבה אנו מתחילים את תנועותינו תומכת בעיקר בלמידה שמתרחשת מניסיון לניסיון. לאימון יומיומי, לאימון ספורט ולשיקום, משמעות הדבר היא שתגמולים או עונשים עשויים להיות היעילים ביותר כאשר המשימות מאפשרות משוב והתאמה רציפים, בעוד שניצול מדוד של השונות בניסיונות הראשוניים עשוי להיות בעל ערך מיוחד כאשר רק הדחף ההתחלתי של התנועה קובע את ההצלחה. על ידי הפרדה בין שתי דרכי הלמידה האלה, המחקר מסייע להסביר מדוע מחקרים קודמים דיווחו על השפעות מעורבות של תגמול ועונש על למידה מוטורית, ומצביע על דרכים ממוקדות יותר לעצב תרגול שעובד עם, ולא נגד, מנגנוני הלמידה המובנים של מערכת העצבים שלנו.
ציטוט: Lehnberg, F.M., Paul, T., Wiemer, V.M. et al. Reinforcement drives within- not between-trial motor adaptation. Sci Rep 16, 11605 (2026). https://doi.org/10.1038/s41598-026-45293-8
מילות מפתח: למידה מוטורית, חיזוק, שונות בתנועה, התאמה ויזואו‑מוטורית, בקרת תנועה