Clear Sky Science · tr
Pekiştirme deneme içi değil - denemeler arası motor adaptasyonu yönlendirir
Pratik ve ödül hareketlerimizi nasıl biçimlendirir
Günlük eylemler, bir kahve fincanına uzanmak veya bir top atmak gibi, zahmetsizce gelir; ancak beynimiz bu hareketleri sürekli ince ayarlıyor. Bu çalışma, görünüşte basit bir soruyu soruyor: pratik yaparken ödüller ve cezalar geliştirmemize hareket ortasında mı yardımcı olur, yoksa sadece bir denemeden diğerine mi? Cevap, motivasyon ile eylemlerimizdeki doğal denemeler arası farklılıkların yeni motor becerileri nasıl öğrenmemizi bir araya getirdiğini gösterir.
Hareket hatalarından öğrenmenin iki yolu
Yeni ya da değişmiş bir durumda hareket ettiğimizde, beynimiz en az iki yolla öğrenebilir. Bir yol denemeler arasında planı günceller: son uzanışın nerede yanlış gittiğini gördükten sonra, bir sonraki sefer nasıl nişan alacağımızı ince bir şekilde değiştiririz. Diğer yol ise tek bir hareket sırasında anlık ayarlama yapar: görsel geri bildirim elin rotadan saptığını gösterdiğinde, kontrol sistemleri hareketi yol ortasında düzeltir. Yazarlar bu iki yolun ödül ve cezalardan farklı şekilde etkilenip etkilenmediğini ve insanların erken hareketlerindeki doğal değişkenliğin her durumda öğrenmeyi kolaylaştırıp kolaylaştırmadığını merak ettiler.
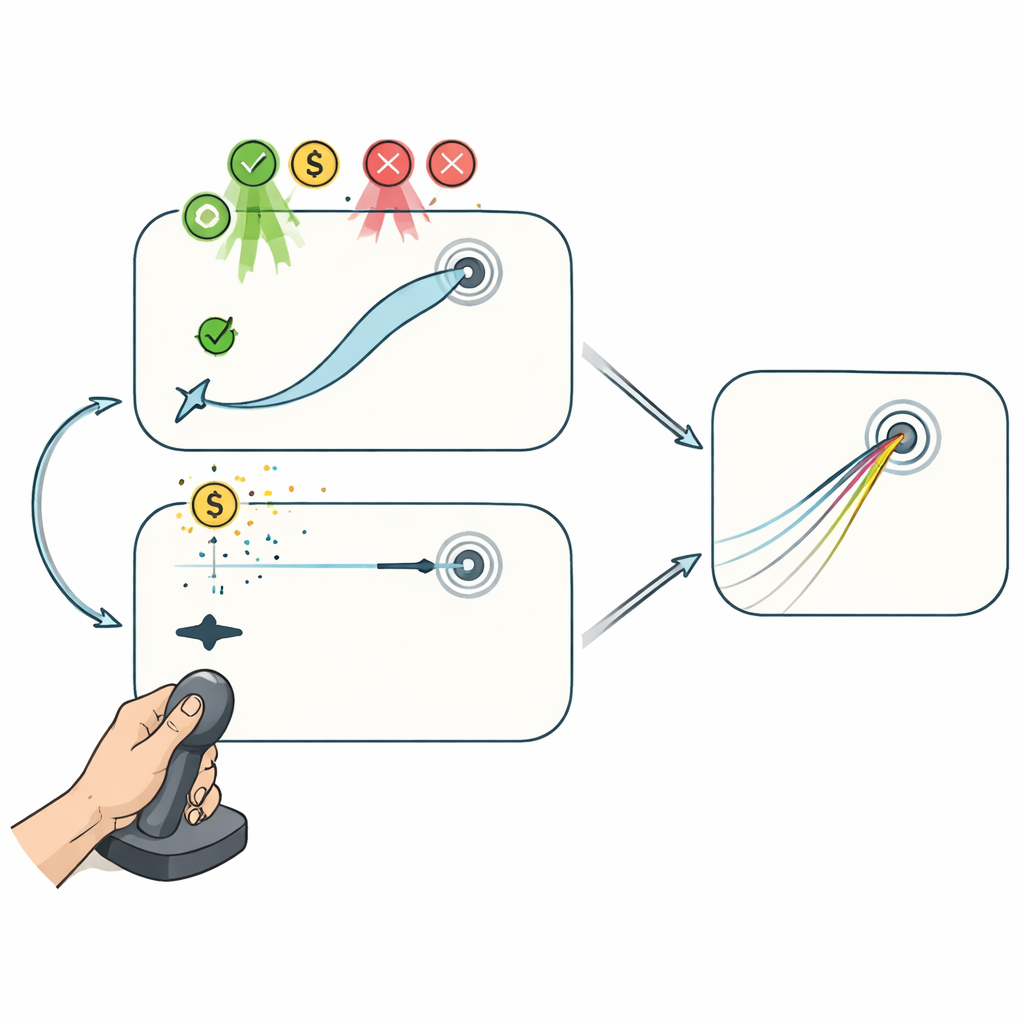
İki joystick oyunu: yol ortası düzeltmeli ve düzeltmesiz
Bu süreçleri ayırmak için gönüllüler, el hareketi ile imleç arasındaki bağlantının gizlice döndürüldüğü iki joystick tabanlı bilgisayar görevi oynadılar. “Uzanma” görevinde imleç joysticki doğru şekilde izleyerek oyuncuların hareket ortasında yolunu büküp hedefe yönlendirmesine izin verdi. Bu düzenleme, denemeler arası planlama ile deneme içi düzeltmenin ikisinin de gelişime katkıda bulunmasına olanak tanır. Buna karşılık “Curling” görevinde yalnızca joystick hareketinin çok başlangıcı önem taşıyordu: imleç kısa bir mesafeyi geçtikten sonra artık etkilenemeyen düz bir çizgide kaydı; buz üzerindeki curling taşına benzer şekilde. Burada performans yalnızca denemeler arasında ilk planı ayarlayarak iyileşebilirdi, yolda hataları düzeltmek mümkün değildi.
Motivasyon hareket ortası düzeltmeyi güçlendirir, yalnızca planlamayı değil
Her iki oyunda da insanlar görsel rotasyona kademeli olarak uyum gösterdiler; motor adaptasyonun açık işaretleri, bozulmaya geri dönüşte tasarruf (savings) ve yarım saatlik moladan sonra kalıcılık görüldü. Ancak yol ortası düzeltmeye izin verilmesi büyük bir fark yarattı: Uzanma oyununda hatalar daha fazla küçüldü ve öğrenme hızları Curling oyununa göre daha yüksekti; oysa adapte olmanın genel zaman çizelgesi benzerdir. Kritik olarak, performansa bağlı ödül ve cezalar yalnızca Uzanma görevinde sonuçları iyileştirdi. Katılımcılar doğru hareketler için daha fazla para kazandıklarında ya da büyük hatalar için para kaybettiklerinde, performansları nötr geri bildirim grubunun üzerinde oldu—ancak sadece imleci sürekli yönlendirebildiklerinde. Başarının yalnızca iyi bir başlangıç atışını planlamaya dayandığı durumda, pekiştirmenin tespit edilebilir bir etkisi yoktu.
Planlamada faydalı değişkenlik, düzeltme sırasında sönümlenmiş
Araştırmacılar ayrıca rotasyon ilk tanıtıldığında insanların erken hareketlerinin yön bakımından ne kadar değişken olduğunu inceledi. Curling görevinde, erken dönemde daha fazla değişkenlik gösteren katılımcılar, hızlı ilk iyileşmeleri hesaba kattıktan sonra bile daha fazla öğrendi. Bu, düzeltmelerin imkansız olduğu durumlarda, yazarların “planlama gürültüsü” olarak adlandırdığı şekilde hafifçe farklı planları denemenin beynin denemeler arasında daha iyi stratejiler keşfetmesine ve rafine etmesine yardımcı olduğunu düşündürür. Buna karşılık Uzanma görevinde erken değişkenlik çoğunlukla ilk birkaç denemedeki hızlı hata azaltımını yansıtıyor ve insanların nihayetinde ne kadar uyum sağlayacağını öngörmedi. Sürekli görsel geri bildirim sistemin hataları gerçek zamanlı düzeltmesine olanak verdiği için, bu erken farklılıkların bilgi değeri sönümlenmiş gibi görünmektedir.
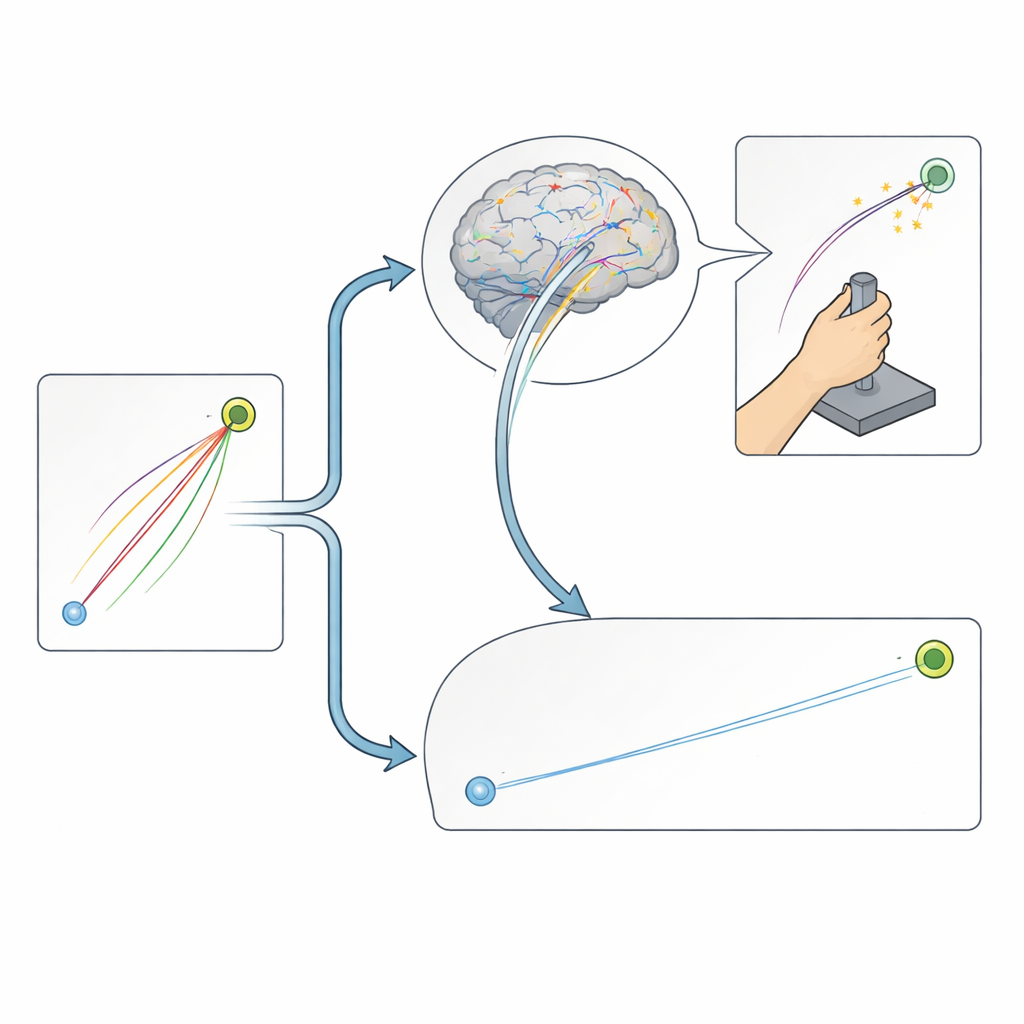
Bu, eğitim ve rehabilitasyon için neden önemli
Birlikte, bu sonuçlar pekiştirmenin esas olarak hareketlerin gerçekleştiği sırada düzeltilmesini güçlendirdiğini, oysa hareketlerimizi başlatma biçimimizdeki doğal değişkenliğin esas olarak bir denemeden diğerine gerçekleşen öğrenmeyi desteklediğini gösterir. Günlük antrenman, spor koçluğu ve rehabilitasyon için bu, ödüller veya cezaların sürekli geri bildirim ve ayarlamaya izin veren görevlerde en etkili olabileceği; yalnızca başlangıç hareket dürtüsünün başarıyı belirlediği durumlarda ise erken denemelerdeki değişkenliği dikkatle kullanmanın özellikle değerli olabileceği anlamına gelir. Bu iki öğrenme yolunu ayırarak çalışma, geçmiş araştırmaların ödül ve cezanın motor öğrenme üzerindeki karışık etkilerini neden raporladığını açıklamaya yardımcı olur ve pratikleri sinir sistemimizin yerleşik öğrenme mekanizmalarıyla uyumlu şekilde tasarlamaya yönelik daha hedefli yolları işaret eder.
Atıf: Lehnberg, F.M., Paul, T., Wiemer, V.M. et al. Reinforcement drives within- not between-trial motor adaptation. Sci Rep 16, 11605 (2026). https://doi.org/10.1038/s41598-026-45293-8
Anahtar kelimeler: motor öğrenme, pekiştirme, hareket değişkenliği, görsel-motor adaptasyon, motor kontrol