Clear Sky Science · nl
Bekrachtiging stimuleert binnen‑ en niet tussen‑poging motorische aanpassing
Hoe oefenen en beloning onze bewegingen vormen
Alledaagse handelingen zoals naar een koffiekopje reiken of een bal werpen voelen moeiteloos, maar ons brein scherpt deze bewegingen voortdurend bij. Deze studie stelt een ogenschijnlijk eenvoudige vraag: helpen beloningen en straffen ons vooral om te verbeteren terwijl we midden in een beweging zijn, of alleen van de ene poging naar de volgende? Het antwoord onthult hoe motivatie en natuurlijke proef‑tot‑proef verschillen in onze bewegingen samen bepalen hoe we nieuwe motorische vaardigheden leren.
Twee manieren waarop het brein leert van bewegingsfouten
Wanneer we bewegen in een nieuwe of veranderde situatie, kan ons brein op minstens twee manieren leren. De ene route werkt tussen pogingen: na het zien waar de vorige reikwijdte misging, passen we subtiel aan hoe we de volgende keer mikken. De andere route past onderweg aan tijdens één enkele beweging: als visuele feedback laat zien dat de hand van koers raakt, corrigeren controlesystemen de beweging halverwege. De onderzoekers wilden weten of deze twee routes verschillend worden beïnvloed door beloningen en straffen, en of de natuurlijke variabiliteit in iemands vroege bewegingen het leren in elk geval helpt of belemmert.
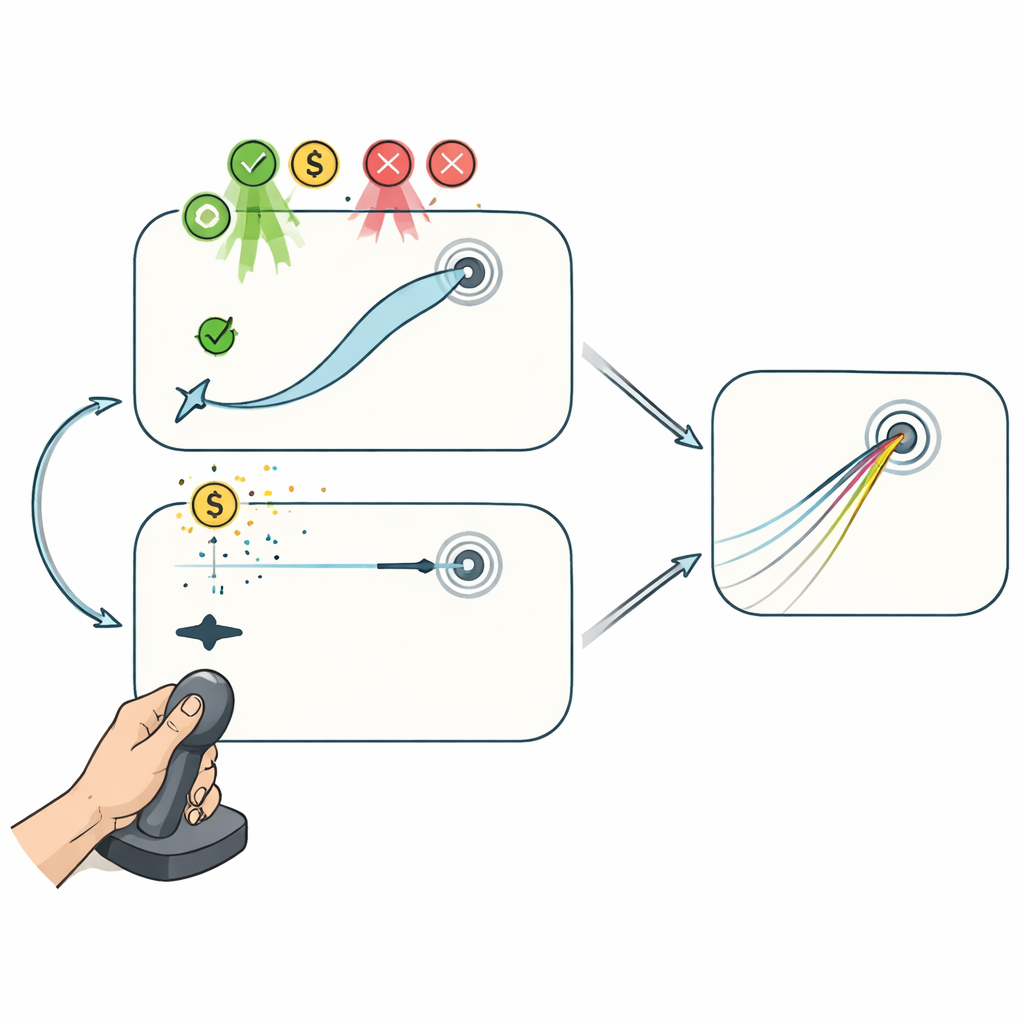
Twee joystickspellen: met en zonder tussenliggende correctie
Om deze processen uit elkaar te houden, speelden vrijwilligers twee computertaken met een joystick terwijl de koppeling tussen handbeweging en cursor stiekem werd geroteerd. In de taak “Reaching” volgde de cursor nauwkeurig de joystick, waardoor spelers hun pad tijdens de beweging konden buigen om naar het doel te sturen. Deze opzet laat zowel planning tussen pogingen als correctie binnen een poging bijdragen aan verbetering. In de taak “Curling” daarentegen, telde alleen het allereerste deel van de joystickbeweging: zodra de cursor een korte afstand had afgelegd, gleed hij in een rechte lijn die niet meer kon worden beïnvloed, vergelijkbaar met een curlingsteen op ijs. Hier kon de prestatie alleen verbeteren door het initiële plan van poging tot poging aan te passen, niet door fouten onderweg te herstellen.
Motivatie versterkt correctie tijdens de beweging, niet alleen planning
In beide spellen compenseerden mensen geleidelijk voor de visuele rotatie, met duidelijke tekenen van motorische aanpassing, beperkte retentie bij terugkeer naar de verstoring en vasthoudendheid na een halfuur pauze. Het toestaan van tussenliggende correcties maakte echter een groot verschil: in het Reaching‑spel werden fouten sterker kleiner en waren leersnelheden hoger dan in het Curling‑spel, hoewel het algemene tijdsverloop van aanpassing vergelijkbaar was. Cruciaal is dat beloningen en straffen gekoppeld aan prestatie alleen het Reaching‑resultaat verbeterden. Of deelnemers meer geld verdienden voor nauwkeurige bewegingen of geld verloren bij grote fouten, hun prestaties overtroffen die van een neutrale feedbackgroep—maar alleen wanneer ze de cursor continu konden bijsturen. Wanneer succes puur afhing van het plannen van een goede eerste beweging, had bekrachtiging geen waarneembare invloed.
Behulpzame variatie bij planning, gedempt tijdens correctie
De onderzoekers onderzochten ook hoe sterk de richting van vroege bewegingen varieerde toen de rotatie voor het eerst werd ingevoerd. In de Curling‑taak leerden deelnemers met grotere vroege variabiliteit later meer, zelfs na rekening te houden met snelle initiële verbeteringen. Dit suggereert dat wanneer correcties onmogelijk zijn, het uitproberen van licht verschillende plannen—wat de auteurs “planningsruis” noemen—het brein helpt om tussen pogingen betere strategieën te verkennen en te verfijnen. In de Reaching‑taak daarentegen weerspiegelde vroege variabiliteit voornamelijk snelle foutreductie in de eerste paar pogingen en voorspelde het niet hoeveel deelnemers uiteindelijk zouden aanpassen. Omdat continue visuele feedback het systeem in staat stelt fouten in real time te corrigeren, lijkt de informatieve waarde van deze vroege verschillen gedempt te worden.
Waarom dit belangrijk is voor training en revalidatie
Gezamenlijk tonen deze resultaten dat bekrachtiging vooral het vermogen van het brein versterkt om bewegingen te corrigeren terwijl ze zich ontvouwen, terwijl natuurlijke variabiliteit in hoe we onze bewegingen beginnen vooral het leren tussen pogingen ondersteunt. Voor dagelijkse training, sportcoaching en revalidatie betekent dit dat beloningen of straffen het meest effectief kunnen zijn wanneer taken continue feedback en bijstelling toestaan, terwijl het zorgvuldig benutten van variatie in vroege pogingen bijzonder waardevol kan zijn wanneer alleen de initiële bewegingsimpuls het succes bepaalt. Door deze twee leerroutes te scheiden, helpt de studie verklaren waarom eerder onderzoek gemengde effecten van beloning en straf op motorisch leren rapporteerde, en wijst ze op meer gerichte manieren om oefenprogramma’s te ontwerpen die samenwerken met, in plaats van tegen, de ingebouwde leermechanismen van ons zenuwstelsel.
Bronvermelding: Lehnberg, F.M., Paul, T., Wiemer, V.M. et al. Reinforcement drives within- not between-trial motor adaptation. Sci Rep 16, 11605 (2026). https://doi.org/10.1038/s41598-026-45293-8
Trefwoorden: motorisch leren, bekrachtiging, bewegingsvariabiliteit, visuomotorische aanpassing, motorische controle