Clear Sky Science · de
Verstärkung fördert motorische Anpassung innerhalb — nicht zwischen Versuchen
Wie Übung und Belohnung unsere Bewegungen formen
Alltägliche Handlungen wie das Greifen nach einer Kaffeetasse oder das Werfen eines Balls wirken mühelos, doch unser Gehirn verfeinert diese Bewegungen ständig. Diese Studie stellt eine täuschend einfache Frage: Helfen Belohnungen und Bestrafungen uns, während einer Bewegung besser zu werden, oder nur von einem Versuch zum nächsten? Die Antwort zeigt, wie Motivation und die natürlichen Versuch‑zu‑Versuch‑Schwankungen unserer Aktionen zusammenwirken, um das Erlernen neuer motorischer Fähigkeiten zu formen.
Zwei Wege, wie das Gehirn aus Bewegungsfehlern lernt
Wenn wir uns in einer neuen oder veränderten Situation bewegen, kann unser Gehirn auf mindestens zwei Arten lernen. Ein Weg aktualisiert den Plan zwischen den Versuchen: nachdem wir gesehen haben, wo der letzte Zug schiefging, ändern wir das Zielen für den nächsten Versuch leicht. Der andere Weg passt während der laufenden Bewegung in Echtzeit an: wenn visuelle Rückmeldung zeigt, dass die Hand vom Kurs abweicht, korrigieren Steuerungssysteme die Bewegung unterwegs. Die Autor:innen wollten wissen, ob diese beiden Wege unterschiedlich durch Belohnungen und Strafen beeinflusst werden und ob die natürliche Variabilität in frühen Bewegungen das Lernen in jedem Fall fördert oder behindert.
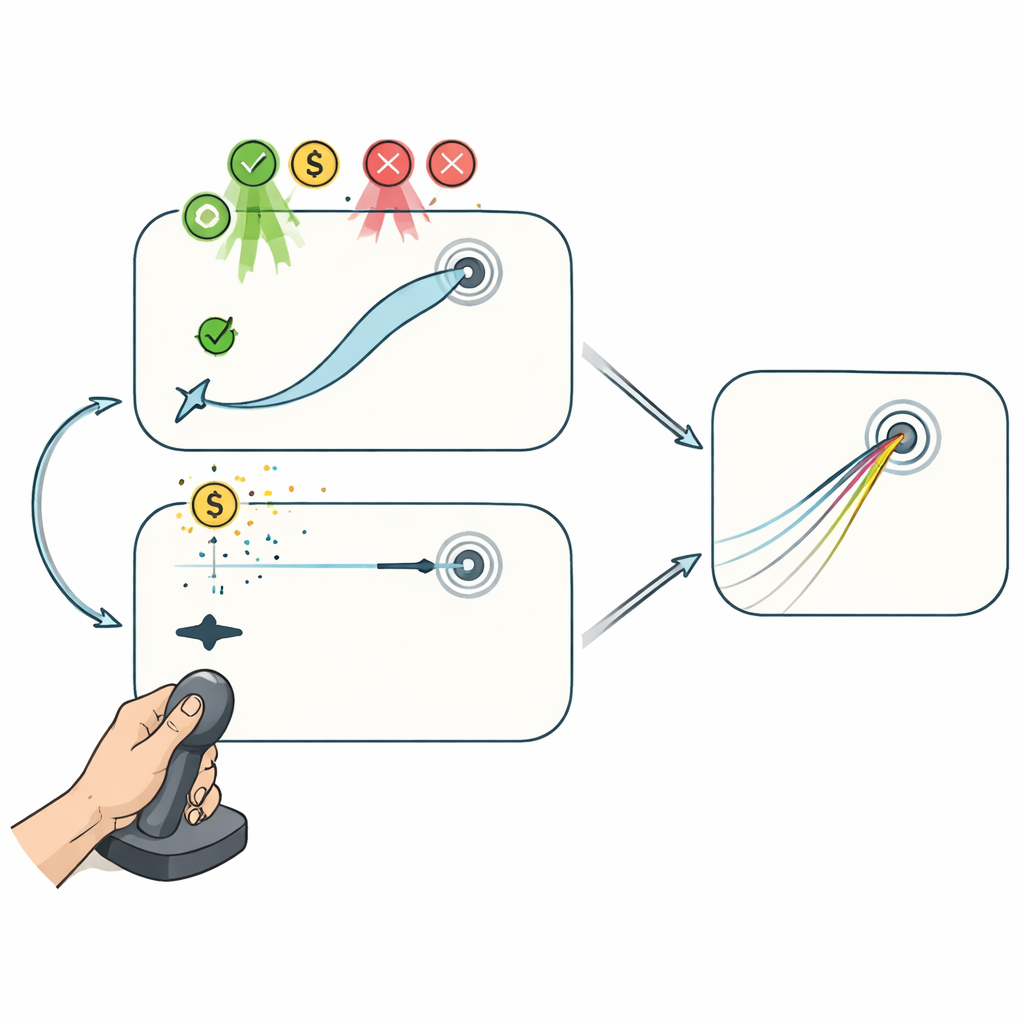
Zwei Joystick‑Spiele: mit und ohne Kurskorrektur unterwegs
Um diese Prozesse zu trennen, führten Freiwillige zwei joystickbasierte Computerspiele aus, während die Verbindung zwischen Handbewegung und Cursor heimlich rotiert wurde. Im "Reaching"‑Task folgte der Cursor dem Joystick treu, sodass die Spielenden ihren Weg während der Bewegung biegen konnten, um auf das Ziel zuzusteuern. Dieses Setup erlaubt sowohl Planänderungen zwischen den Versuchen als auch Korrekturen während eines Versuchs. Im Gegensatz dazu zählte im "Curling"‑Task nur der ganz Anfang der Joystickbewegung: Sobald der Cursor eine kurze Distanz zurückgelegt hatte, glitt er geradlinig weiter und war nicht mehr beeinflussbar, ähnlich einem Curling‑Stein auf dem Eis. Hier konnte die Leistung nur durch Anpassung des Anfangsplans von Versuch zu Versuch besser werden, nicht durch das Beheben von Fehlern unterwegs.
Motivation fördert Korrekturen während der Bewegung, nicht nur die Planung
In beiden Spielen kompensierten die Teilnehmenden die visuelle Rotation allmählich und zeigten deutliche Zeichen motorischer Anpassung, Einsparungen beim erneuten Auftreten der Störung und Behaltensleistung nach einer halben Stunde Pause. Allerdings machte die Möglichkeit zur Kurskorrektur unterwegs einen großen Unterschied: Im Reaching‑Spiel wurden Fehler stärker reduziert und die Lernraten waren höher als im Curling‑Spiel, obwohl der allgemeine Verlauf der Anpassung ähnlich war. Entscheidend war, dass mit der Leistung verknüpfte Belohnungen und Bestrafungen nur im Reaching‑Task die Ergebnisse verbesserten. Ob Teilnehmende mehr Geld für genaue Bewegungen bekamen oder Geld für große Fehler verloren, ihre Leistung übertraf die einer neutralen Feedback‑Gruppe — aber nur, wenn sie den Cursor kontinuierlich steuern konnten. Wenn der Erfolg rein von der Planung eines guten Anfangsschlags abhing, hatte Verstärkung keinen messbaren Effekt.
Nützliche Variation bei der Planung, abgeschwächt bei der Korrektur
Die Forschenden untersuchten außerdem, wie stark die anfänglichen Bewegungen der Teilnehmenden in der Richtung schwankten, als die Rotation erstmals eingeführt wurde. Im Curling‑Task lernten Teilnehmende mit größerer anfänglicher Variabilität später mehr, selbst nachdem schnelle Anfangsverbesserungen berücksichtigt wurden. Das legt nahe, dass, wenn Korrekturen nicht möglich sind, das Ausprobieren leicht unterschiedlicher Pläne — was die Autor:innen als „Planungsrauschen" bezeichnen — dem Gehirn hilft, zwischen den Versuchen besser zu erkunden und Strategien zu verfeinern. Im Reaching‑Task hingegen spiegelte die frühe Variabilität hauptsächlich eine rasche Fehlerreduktion in den ersten Versuchen wider und sagte nicht voraus, wie stark die Teilnehmenden sich letztlich anpassten. Da fortlaufende visuelle Rückmeldung es dem System erlaubt, Fehler in Echtzeit zu korrigieren, scheint der informationswert dieser frühen Unterschiede abgeschwächt zu werden.
Warum das für Training und Rehabilitation wichtig ist
Zusammen zeigen diese Ergebnisse, dass Verstärkung vor allem die Fähigkeit des Gehirns stärkt, Bewegungen im Verlauf zu korrigieren, während die natürliche Variabilität in unserem Bewegungsansatz vor allem das Lernen unterstützt, das von einem Versuch zum nächsten stattfindet. Für alltägliches Training, Sportcoaching und Rehabilitation bedeutet das: Belohnungen oder Sanktionen sind wahrscheinlich am wirksamsten, wenn Aufgaben kontinuierliche Rückmeldung und Anpassung zulassen, während das gezielte Ausnutzen von Variation in frühen Versuchen besonders wertvoll sein kann, wenn nur der anfängliche Bewegungsimpuls über den Erfolg entscheidet. Indem die Studie diese beiden Lernwege trennt, hilft sie zu erklären, warum frühere Forschung gemischte Effekte von Belohnung und Bestrafung auf motorisches Lernen berichtet hat, und weist auf gezieltere Wege hin, Übung so zu gestalten, dass sie mit den eingebauten Lernmechanismen unseres Nervensystems zusammenarbeitet statt gegen sie.
Zitation: Lehnberg, F.M., Paul, T., Wiemer, V.M. et al. Reinforcement drives within- not between-trial motor adaptation. Sci Rep 16, 11605 (2026). https://doi.org/10.1038/s41598-026-45293-8
Schlüsselwörter: motorisches Lernen, Verstärkung, Bewegungsvariabilität, visuomotorische Anpassung, motorische Kontrolle