Clear Sky Science · ru
Подкрепление приводит к адаптации моторики внутри попытки, а не между попытками
Как практика и вознаграждение формируют наши движения
Повседневные действия, например дотянуться до кружки кофе или бросить мяч, кажутся простыми, но наш мозг постоянно тонко настраивает эти движения. В этом исследовании звучит на первый взгляд простой вопрос: помогают ли награды и наказания улучшать исполнение во время самого движения или лишь между попытками? Ответ показывает, как мотивация и естественные различия между попытками взаимодействуют и формируют освоение новых моторных навыков.
Два пути обучения мозга на ошибках движения
Когда мы действуем в новой или изменённой ситуации, мозг может учиться как минимум двумя способами. Первый путь обновляет план между попытками: увидев, где прошла предыдущая попытка, мы тонко меняем прицел на следующий раз. Второй путь корректирует движение «на ходу»: когда визуальная обратная связь показывает отклонение руки, системы управления исправляют траекторию в процессе движения. Авторы хотели выяснить, по‑разному ли на эти два пути влияют вознаграждения и наказания, и помогает ли или мешает естественная вариабельность ранних движений в каждом из случаев.
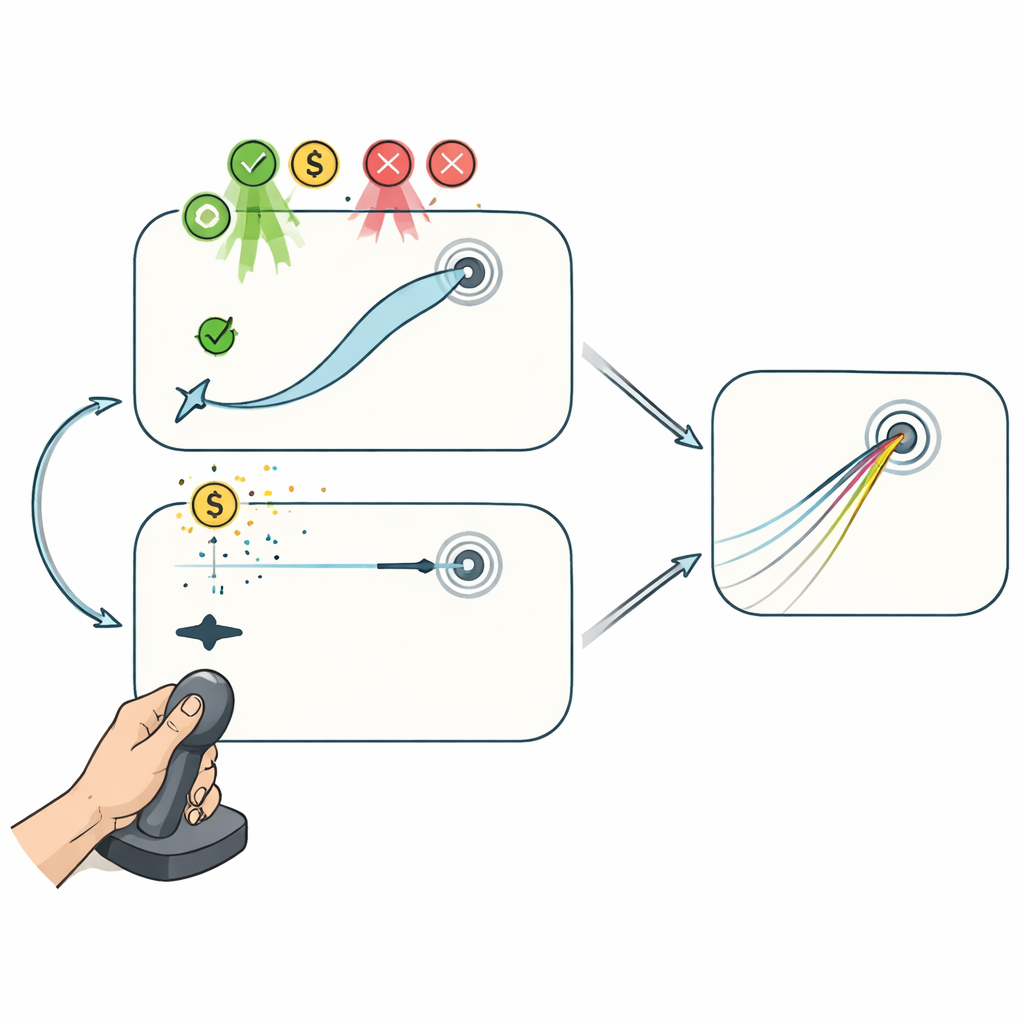
Две джойстиковые игры: с поправкой в полёте и без неё
Чтобы разделить эти процессы, участники выполняли две компьютерные задачи с джойстиком, пока связь между движением руки и курсора тайно поворачивалась. В задании «Reaching» курсор верно следовал за джойстиком, позволяя игрокам менять траекторию в середине движения, чтобы подвести курсор к цели. Такая установка даёт возможность как планированию между попытками, так и корректировке внутри попытки вносить вклад в улучшение. В задании «Curling», напротив, значимым был только начальный толчок джойстика: после прохождения небольшой дистанции курсор скользил по прямой и больше не поддавался влиянию, как камень в керлинге. Здесь улучшение могло происходить лишь за счёт изменения начального плана от попытки к попытке, а не за счёт исправления ошибок по ходу.
Мотивация усиливает поправки в полёте, но не одно только планирование
В обеих играх участники постепенно компенсировали визуальную ротацию, проявляя признаки моторной адаптации, усвоения при повторном возвращении к помехе и сохранения навыка после получасового перерыва. Однако возможность корректировать курс в середине движения сыграла важную роль: в игре Reaching ошибки сокращались сильнее, а скорость обучения была выше, чем в Curling, хотя общий временной профиль адаптации был схож. Важный вывод: награды и наказания, связанные с результатом, улучшали показатели лишь в задаче Reaching. Независимо от того, получали ли участники больше денег за точные движения или теряли за крупные ошибки, их результаты превосходили нейтральную группу — но только когда они могли непрерывно управлять курсором. Когда успех зависел исключительно от удачного начального импульса, подкрепление не давало заметного эффекта.
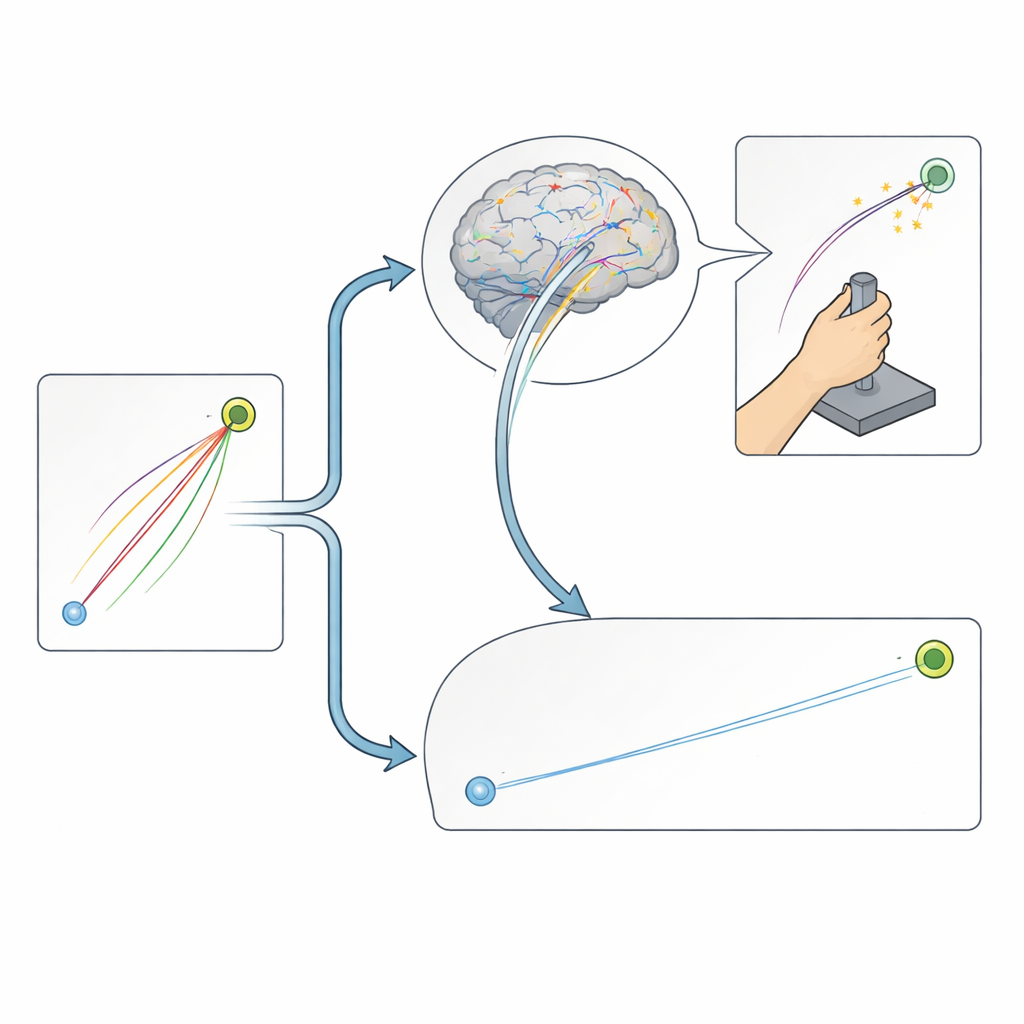
Полезная вариативность при планировании, подавляемая при коррекции
Исследователи также оценили, насколько варьировало направление ранних движений участников при первом введении ротации. В задаче Curling те, у кого наблюдалась большая начальная вариабельность, в итоге обучались лучше, даже с учётом быстрых первоначальных улучшений. Это указывает на то, что когда корректировки невозможны, пробование чуть разных планов — то, что авторы называют «шумом планирования» — помогает мозгу исследовать и уточнять лучшие стратегии между попытками. В задаче Reaching, напротив, ранняя вариабельность в основном отражала быстрое уменьшение ошибок в первые несколько попыток и не предсказывала, насколько сильно участники в конечном счёте адаптируются. Поскольку непрерывная визуальная обратная связь позволяет системе исправлять ошибки в реальном времени, информационная ценность этих ранних различий оказывается ослабленной.
Почему это важно для тренировки и реабилитации
В совокупности результаты показывают, что подкрепление в основном усиливает способность мозга исправлять движения в процессе их выполнения, тогда как естественная вариативность начальных импульсов поддерживает обучение, происходящее между попытками. Для повседневной тренировки, спортивного тренерства и реабилитации это означает: вознаграждения или наказания, вероятно, работают лучше в задачах с непрерывной обратной связью и возможностью корректировки, тогда как сознательное использование вариативности ранних попыток может быть особенно полезным, когда успех определяется только начальным движением. Разделяя эти два пути обучения, исследование помогает объяснить, почему предыдущие работы давали смешанные результаты по эффектам подкрепления на моторное обучение, и указывает на более целевые способы организации практики, которые работают в гармонии с врождёнными механизмами обучения нашей нервной системы.
Цитирование: Lehnberg, F.M., Paul, T., Wiemer, V.M. et al. Reinforcement drives within- not between-trial motor adaptation. Sci Rep 16, 11605 (2026). https://doi.org/10.1038/s41598-026-45293-8
Ключевые слова: обучение движению, подкрепление, вариабельность движений, визуомоторная адаптация, моторное управление