Clear Sky Science · it
La rinforzazione guida l’adattamento motorio durante, non solo tra, i tentativi
Come pratica e ricompense modellano i nostri movimenti
Azioni quotidiane come afferrare una tazza di caffè o lanciare una palla sembrano semplici, eppure il nostro cervello affina costantemente questi movimenti. Questo studio pone una domanda apparentemente semplice: quando ci alleniamo, ricompense e punizioni ci aiutano a migliorare mentre il movimento è in corso o soltanto da un tentativo al successivo? La risposta rivela come la motivazione e le naturali differenze trial‑to‑trial nelle nostre azioni si combinano per modellare l’apprendimento di nuove abilità motorie.
Due modalità con cui il cervello apprende dagli errori di movimento
Quando ci muoviamo in una situazione nuova o modificata, il cervello può imparare almeno in due modi. Una via aggiorna il piano tra i tentativi: dopo aver osservato dove l’ultima raggiunta è andata fuori bersaglio, modifichiamo sottilmente il modo in cui mireremo la volta successiva. L’altra via si aggiusta al volo durante un singolo movimento: mentre il feedback visivo mostra la mano deviare, i sistemi di controllo correggono la traiettoria in corso d’opera. Gli autori hanno voluto capire se queste due vie vengono influenzate in modo diverso da ricompense e punizioni e se la variabilità naturale nei movimenti iniziali delle persone aiuta o ostacola l’apprendimento in ciascun caso.
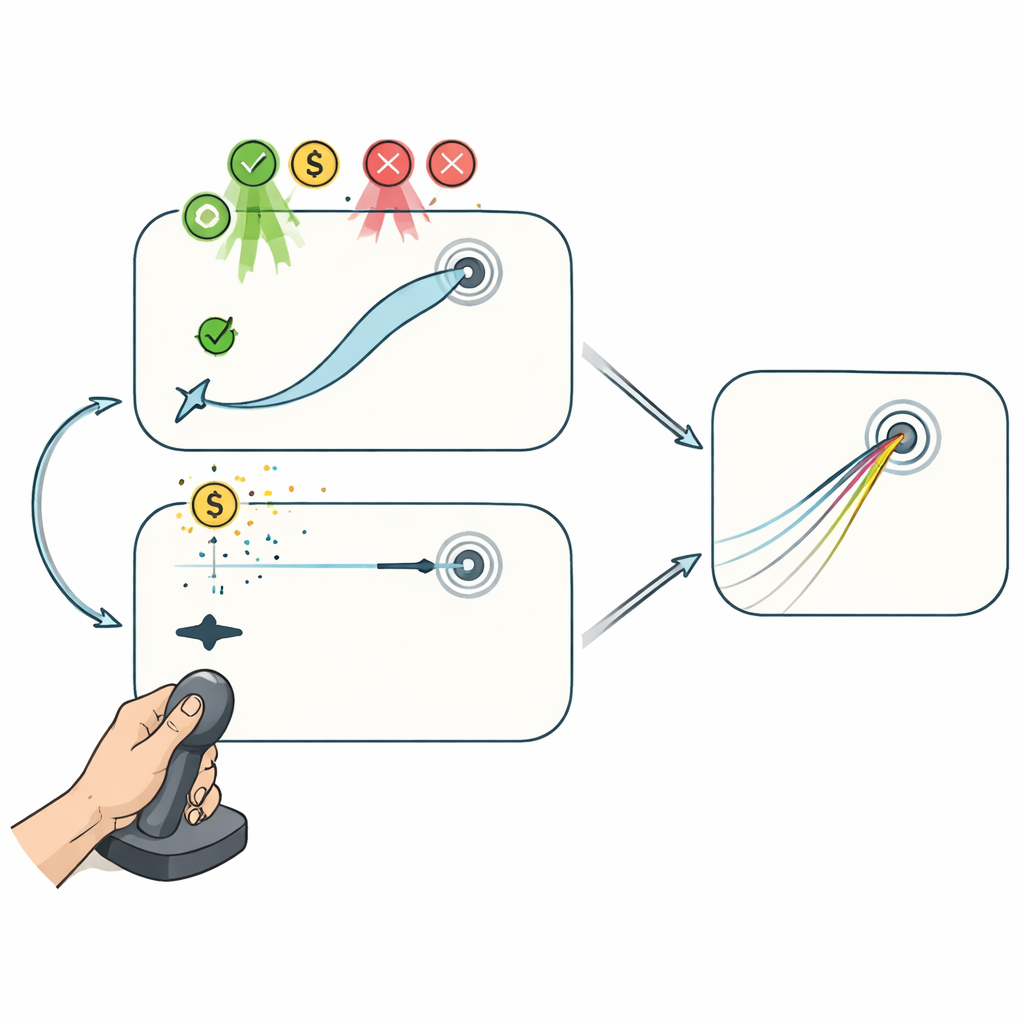
Due giochi con il joystick: con e senza correzione a metà traiettoria
Per separare questi processi, i volontari hanno giocato a due compiti al computer basati su joystick mentre il legame tra il movimento della mano e il cursore veniva ruotato di nascosto. Nel compito “Reaching”, il cursore seguiva fedelmente il joystick, permettendo ai giocatori di modificare la traiettoria a metà movimento per puntare verso l’obiettivo. Questa configurazione lascia spazio sia alla pianificazione tra tentativi sia alla correzione durante il movimento per contribuire al miglioramento. Nel compito “Curling”, invece, contava solo l’inizio del movimento del joystick: una volta che il cursore aveva percorso una breve distanza, scorreva in linea retta senza più poter essere influenzato, proprio come una pietra da curling sul ghiaccio. Qui le prestazioni potevano migliorare solo aggiustando il piano iniziale da un tentativo all’altro, non correggendo gli errori lungo la traiettoria.
La motivazione potenzia la correzione in movimento, non la sola pianificazione
In entrambi i giochi, i partecipanti si sono gradualmente compensati per la rotazione visiva, mostrando chiari segni di adattamento motorio, risparmi quando la perturbazione è stata riproposta e ritenzione dopo una pausa di mezz’ora. Tuttavia, la possibilità di correggere a metà traiettoria ha fatto una grande differenza: nel gioco Reaching gli errori si sono ridotti di più e i tassi di apprendimento sono stati superiori rispetto al gioco Curling, pur con una curva temporale complessiva di adattamento simile. Fondamentalmente, ricompense e punizioni collegate alla prestazione hanno migliorato i risultati solo nel compito Reaching. Che i partecipanti guadagnassero più denaro per movimenti precisi o ne perdessero in caso di grandi errori, le loro prestazioni hanno superato quelle di un gruppo con feedback neutro — ma solo quando potevano guidare il cursore continuamente. Quando il successo dipendeva soltanto dal pianificare un buon colpo iniziale, il rinforzo non ha avuto un impatto rilevabile.
La variazione utile durante la pianificazione, attenuata durante la correzione
I ricercatori hanno anche esaminato quanto variassero in direzione i movimenti iniziali delle persone quando la rotazione è stata introdotta per la prima volta. Nel compito Curling, i partecipanti che mostravano maggiore variabilità iniziale hanno poi appreso di più, anche tenendo conto dei rapidi miglioramenti iniziali. Questo suggerisce che, quando le correzioni sono impossibili, provare piani leggermente diversi — ciò che gli autori chiamano “rumore di pianificazione” — aiuta il cervello a esplorare e affinare strategie migliori tra i tentativi. Nel compito Reaching, invece, la variabilità iniziale rifletteva per lo più la rapida riduzione degli errori nei primi tentativi e non prevedeva quanto le persone si sarebbero adattate alla fine. Poiché il feedback visivo continuo consente al sistema di correggere gli errori in tempo reale, il valore informativo di queste differenze iniziali sembra essere attenuato.
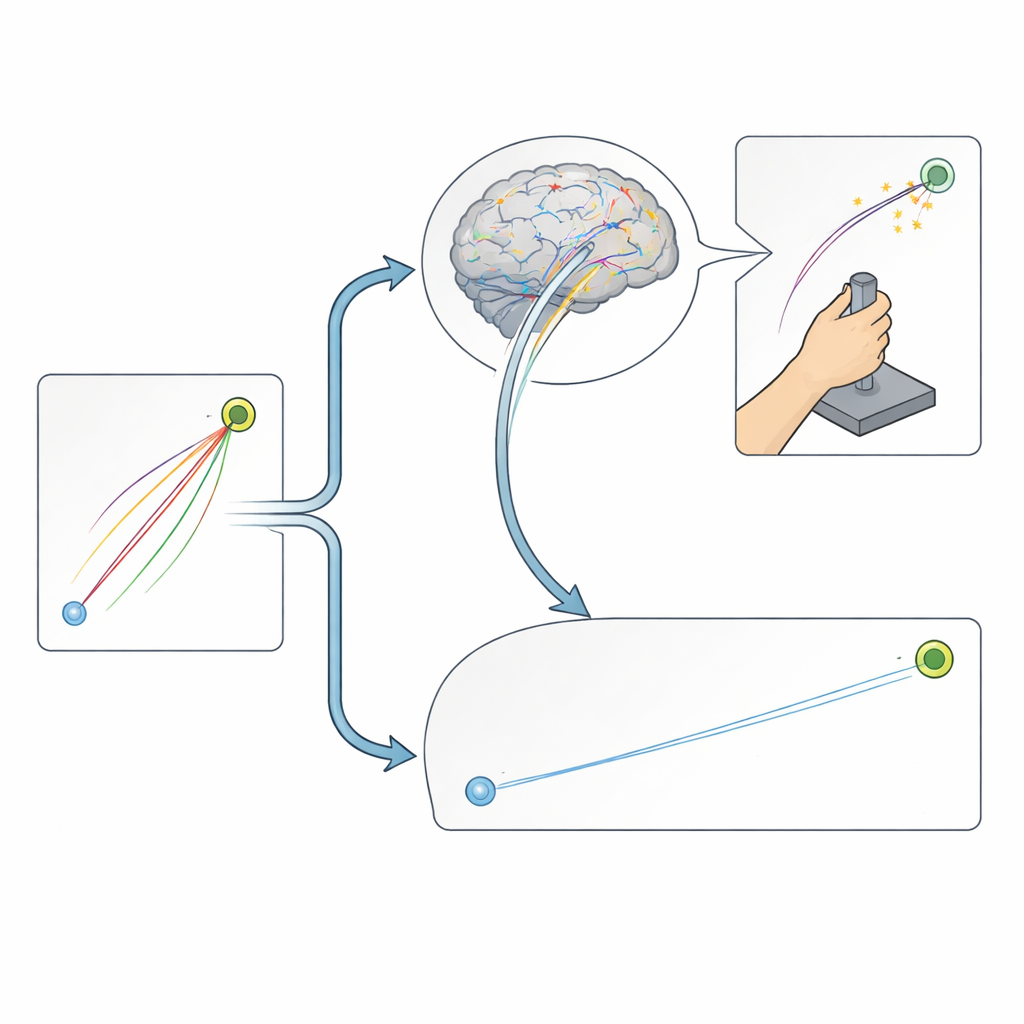
Perché è importante per allenamento e riabilitazione
Nel complesso, questi risultati mostrano che il rinforzo rafforza principalmente la capacità del cervello di correggere i movimenti mentre si svolgono, mentre la variabilità naturale nell’innesco dei nostri movimenti sostiene soprattutto l’apprendimento che avviene da un tentativo all’altro. Per l’allenamento quotidiano, l’allenamento sportivo e la riabilitazione, questo significa che ricompense o penalità possono essere più efficaci quando i compiti consentono feedback e aggiustamenti continui, mentre sfruttare con cura la variazione nei tentativi iniziali potrebbe essere particolarmente prezioso quando è solo l’impulso motorio iniziale a determinare il successo. Separando queste due vie di apprendimento, lo studio aiuta a spiegare perché ricerche precedenti hanno riportato effetti contrastanti di ricompensa e punizione sull’apprendimento motorio e indica modi più mirati per progettare la pratica in sintonia con, anziché contro, i meccanismi di apprendimento intrinseci del nostro sistema nervoso.
Citazione: Lehnberg, F.M., Paul, T., Wiemer, V.M. et al. Reinforcement drives within- not between-trial motor adaptation. Sci Rep 16, 11605 (2026). https://doi.org/10.1038/s41598-026-45293-8
Parole chiave: apprendimento motorio, rinforzo, variabilità del movimento, adattamento visuomotorio, controllo motorio