Clear Sky Science · es
La reforzamiento impulsa la adaptación motora dentro de, no entre, ensayos
Cómo la práctica y la recompensa moldean nuestros movimientos
Acciones cotidianas como alcanzar una taza de café o lanzar una pelota parecen automáticas, pero nuestro cerebro está constantemente afinando esos movimientos. Este estudio plantea una pregunta aparentemente simple: cuando practicamos, ¿las recompensas y los castigos nos ayudan a mejorar mientras estamos en medio de un movimiento, o solamente entre un intento y el siguiente? La respuesta revela cómo la motivación y las diferencias naturales entre ensayos en nuestras acciones se combinan para moldear el aprendizaje de nuevas habilidades motoras.
Dos maneras en que el cerebro aprende de los errores de movimiento
Cuando nos movemos en una situación nueva o alterada, el cerebro puede aprender al menos de dos maneras. Una vía actualiza el plan entre intentos: después de ver dónde falló el último alcance, cambiamos sutilmente cómo apuntamos la siguiente vez. La otra vía ajusta el movimiento en tiempo real durante una única ejecución: cuando la retroalimentación visual muestra la mano desviándose, los sistemas de control corrigen la trayectoria en pleno movimiento. Los autores querían saber si estas dos vías se ven afectadas de forma distinta por recompensas y castigos, y si la variabilidad natural en los movimientos iniciales de las personas ayuda o dificulta el aprendizaje en cada caso.
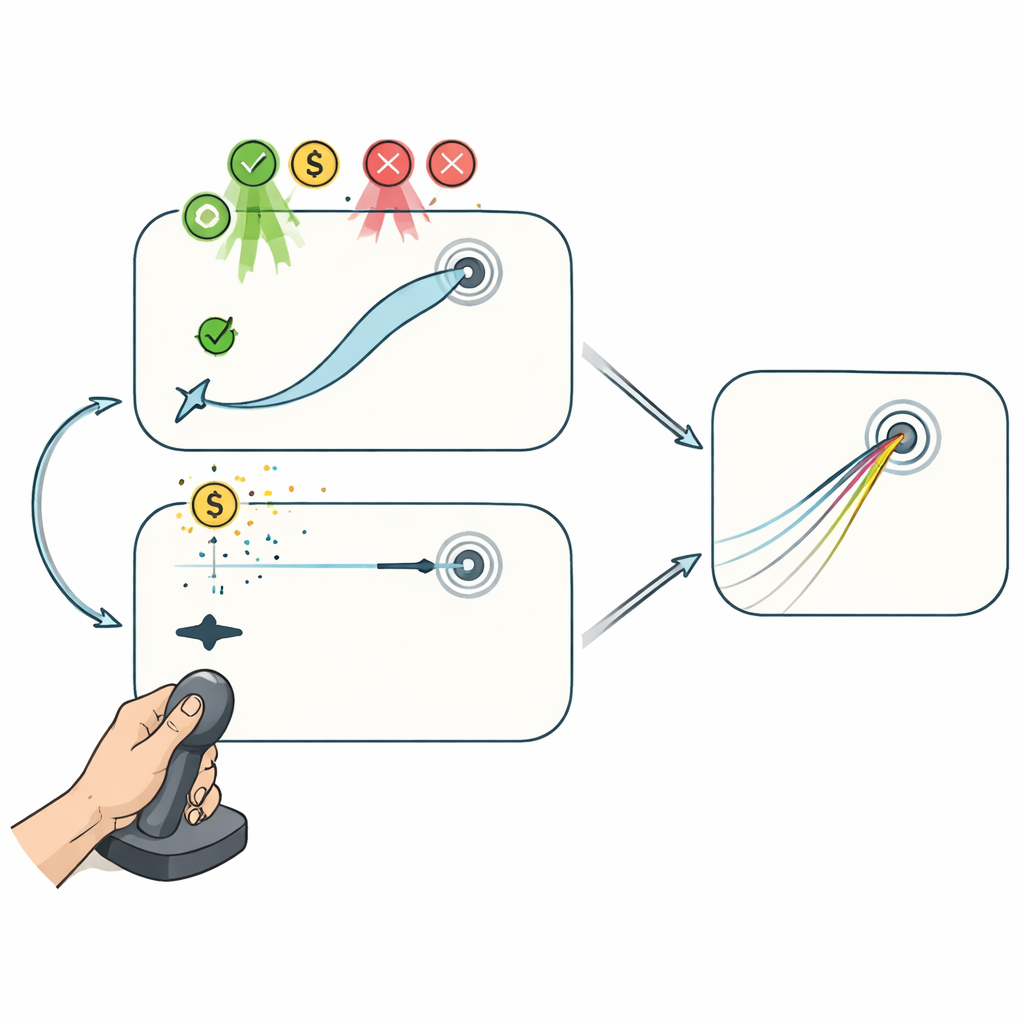
Dos juegos con joystick: con y sin corrección a mitad de trayectoria
Para separar estos procesos, los voluntarios jugaron dos tareas informáticas con joystick mientras la relación entre el movimiento de la mano y el cursor se rotaba de forma encubierta. En la tarea “Reaching” (Alcance), el cursor seguía fielmente al joystick, permitiendo a los jugadores corregir la trayectoria durante el movimiento para dirigir el cursor hacia el objetivo. Esta configuración permite que tanto la planificación entre intentos como la corrección dentro del intento contribuyan a la mejora. En la tarea “Curling”, en cambio, solo importaba el inicio del movimiento del joystick: una vez que el cursor avanzaba una pequeña distancia, deslizaba en línea recta sin posibilidad de influencia, de forma análoga a una piedra de curling sobre el hielo. Aquí, el rendimiento solo podía mejorar ajustando el plan inicial de un ensayo a otro, no corrigiendo errores en el trayecto.
La motivación potencia la corrección durante el movimiento, no la planificación sola
En ambos juegos, las personas compensaron gradualmente la rotación visual, mostrando signos claros de adaptación motora, ahorro al reencontrarse con la perturbación y retención tras un descanso de media hora. Sin embargo, permitir correcciones a mitad de curso marcó una gran diferencia: en el juego Reaching, los errores se redujeron más y las tasas de aprendizaje fueron mayores que en el juego Curling, aunque el curso temporal global de la adaptación fuera similar. De forma crucial, las recompensas y los castigos vinculados al rendimiento mejoraron los resultados solo en la tarea Reaching. Tanto si los participantes ganaban más dinero por movimientos precisos como si perdían dinero por errores grandes, su rendimiento superó al de un grupo con retroalimentación neutra —pero solo cuando podían dirigir el cursor continuamente. Cuando el éxito dependía únicamente de planificar bien la salida inicial, el reforzamiento no tuvo impacto detectable.
Variación útil al planificar, atenuada durante la corrección
Los investigadores también examinaron cuánto variaban en dirección los movimientos iniciales de los participantes cuando se introdujo la rotación. En la tarea Curling, los participantes que mostraron mayor variabilidad temprana aprendieron más, incluso tras ajustar por mejoras iniciales rápidas. Esto sugiere que, cuando las correcciones son imposibles, probar planes ligeramente distintos—lo que los autores denominan “ruido de planificación”—ayuda al cerebro a explorar y refinar mejores estrategias entre ensayos. En la tarea Reaching, en cambio, la variabilidad temprana reflejaba mayormente una rápida reducción de errores en los primeros intentos y no predijo cuánto se adaptarían finalmente las personas. Debido a que la retroalimentación visual continua permite corregir errores en tiempo real, el valor informativo de esas diferencias tempranas parece verse atenuado.
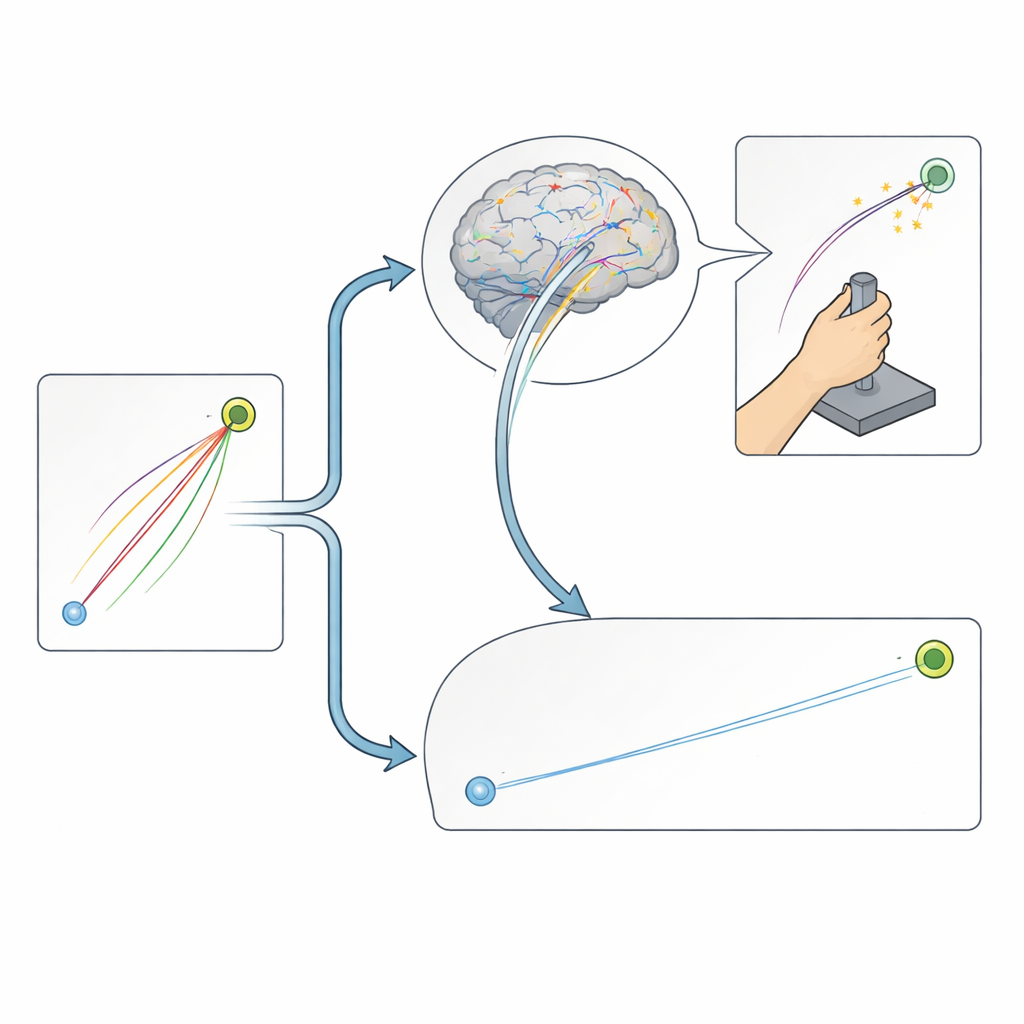
Por qué esto importa para el entrenamiento y la rehabilitación
En conjunto, estos resultados muestran que el reforzamiento fortalece principalmente la capacidad del cerebro para corregir los movimientos a medida que se desarrollan, mientras que la variabilidad natural en cómo iniciamos nuestros movimientos apoya sobre todo el aprendizaje que ocurre de un intento a otro. Para el entrenamiento diario, el entrenamiento deportivo y la rehabilitación, esto significa que las recompensas o sanciones pueden ser más efectivas cuando las tareas permiten retroalimentación y ajuste continuos, mientras que aprovechar cuidadosamente la variación en los intentos iniciales podría ser especialmente valioso cuando solo el impulso inicial determina el éxito. Al separar estas dos vías de aprendizaje, el estudio ayuda a explicar por qué investigaciones previas han informado efectos mixtos de recompensa y castigo sobre el aprendizaje motor, y apunta a formas más específicas de diseñar la práctica que trabajen con, en lugar de contra, los mecanismos de aprendizaje incorporados en nuestro sistema nervioso.
Cita: Lehnberg, F.M., Paul, T., Wiemer, V.M. et al. Reinforcement drives within- not between-trial motor adaptation. Sci Rep 16, 11605 (2026). https://doi.org/10.1038/s41598-026-45293-8
Palabras clave: aprendizaje motor, reforzamiento, variabilidad del movimiento, adaptación visuomotora, control motor