Clear Sky Science · sv
Förstärkning driver inom‑ inte mellan‑försöks motorisk anpassning
Hur träning och belöning formar våra rörelser
Vardagliga handlingar som att sträcka sig efter en kaffekopp eller kasta en boll känns spontana, men våra hjärnor finjusterar hela tiden dessa rörelser. Denna studie ställer en till synes enkel fråga: när vi övar, hjälper belöningar och bestraffningar oss att förbättras medan rörelsen pågår, eller endast från ett försök till nästa? Svaret visar hur motivation och naturliga försök‑till‑försök‑variationer i våra handlingar samverkar för att forma hur vi lär oss nya motoriska färdigheter.
Två sätt hjärnan lär sig av rörelsefel
När vi rör oss i en ny eller förändrad situation kan hjärnan lära sig på minst två sätt. Den ena vägen uppdaterar planen mellan försök: efter att ha sett var föregående nål missade, ändrar vi subtilt hur vi siktar nästa gång. Den andra vägen justerar i farten under en enskild rörelse: när visuell återkoppling visar att handen driver ur kurs, korrigerar kontrollsystemen rörelsen mitt i utförandet. Författarna ville veta om dessa två vägar påverkas olika av belöningar och bestraffningar, och om den naturliga variabiliteten i människors tidiga rörelser hjälper eller hindrar inlärning i respektive fall.
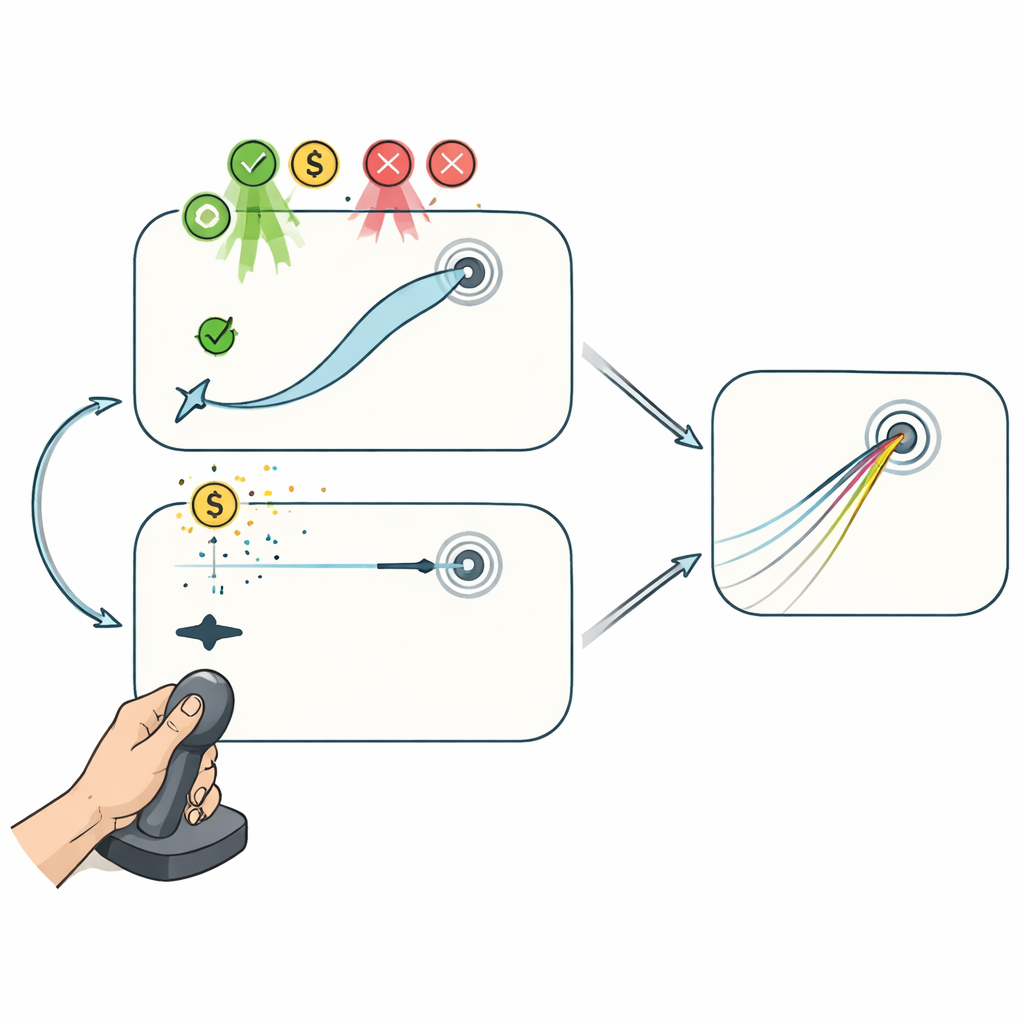
Två joystickspel: med och utan mitt‑bana‑korrigering
För att skilja dessa processer åt fick försökspersoner spela två joystickbaserade datorspel medan sambandet mellan handrörelse och markör hemlighölls genom att roteras. I "Reaching"‑uppgiften följde markören joystickens rörelse troget, vilket tillät spelarna att böja sin bana mitt i rörelsen för att styra mot målet. Denna utformning låter både planering mellan försök och korrigering inom försök bidra till förbättring. I "Curling"‑uppgiften, däremot, spelade endast början av joystickrörelsen någon roll: när markören passerat en kort sträcka gled den i en rak linje som inte längre kunde påverkas, ungefär som en curlingsten på is. Här kunde prestationen förbättras endast genom att justera den initiala planen från försök till försök, inte genom att åtgärda fel under rörelsen.
Motivation förbättrar mitt‑rörelse‑korrigering, inte enbart planering
I båda spelen kompenserade deltagarna gradvis för den visuella rotationen, med tydliga tecken på motorisk anpassning, sparade effekter när perturbationen återinfördes, och bibehållande efter en halvtimmes paus. Att tillåta mitt‑bana‑korrigering gjorde dock stor skillnad: i Reaching‑spelet minskade felen mer och inlärningshastigheterna var högre än i Curling‑spelet, även om den övergripande tidskurvan för anpassning var likartad. Avgörande var att belöningar och bestraffningar kopplade till prestation förbättrade resultaten endast i Reaching‑uppgiften. Oavsett om deltagarna tjänade mer pengar för precisa rörelser eller förlorade pengar vid stora fel, överträffade deras prestation den hos en neutral feedback‑grupp — men endast när de kontinuerligt kunde styra markören. När framgången enbart berodde på att planera ett bra inledande skott hade förstärkning ingen påvisbar effekt.
Behjälplig variation vid planering, dämpad under korrigering
Forskarna undersökte också hur mycket deltagarnas tidiga rörelser varierade i riktning när rotationen först infördes. I Curling‑uppgiften lärde sig de deltagare som visade större tidig variation mer, även efter att man tagit hänsyn till snabba initiala förbättringar. Detta tyder på att när korrigering är omöjlig hjälper det hjärnan att pröva olika planer — vad författarna kallar "planeringsbrus" — för att utforska och förfina bättre strategier mellan försök. I Reaching‑uppgiften återspeglade tidig variation däremot mestadels snabb felreduktion under de första försökens gång och förutsade inte hur mycket deltagarna slutligen skulle anpassa sig. Eftersom kontinuerlig visuell återkoppling låter systemet korrigera fel i realtid verkar den informationsmässiga nyttan av dessa tidiga skillnader vara dämpad.
Varför detta är viktigt för träning och rehabilitering
Tillsammans visar resultaten att förstärkning framför allt stärker hjärnans förmåga att korrigera rörelser medan de pågår, medan naturlig variation i hur vi initierar våra rörelser främst stödjer inlärning som sker från ett försök till nästa. För vardaglig träning, idrottscoaching och rehabilitering innebär detta att belöningar eller påföljder sannolikt är mest effektiva när övningarna tillåter kontinuerlig återkoppling och justering, medan en medveten användning av variation i tidiga försök kan vara särskilt värdefull när endast den initiala rörelseimpulsen avgör framgång. Genom att separera dessa två inlärningsvägar hjälper studien till att förklara varför tidigare forskning rapporterat splittrade effekter av belöning och bestraffning på motorisk inlärning, och pekar mot mer målinriktade sätt att utforma övning som arbetar med, snarare än mot, vårt nervsystems inneboende inlärningsmekanismer.
Citering: Lehnberg, F.M., Paul, T., Wiemer, V.M. et al. Reinforcement drives within- not between-trial motor adaptation. Sci Rep 16, 11605 (2026). https://doi.org/10.1038/s41598-026-45293-8
Nyckelord: motorisk inlärning, förstärkning, rörelsevariabilitet, visuomotorisk anpassning, motorisk kontroll