Clear Sky Science · ja
試行内ではなく試行間の運動適応を駆動する強化学習
練習と報酬が動きを形作る仕組み
コーヒーカップを取る、ボールを投げるといった日常の動作は軽やかに感じられますが、脳は常にこれらの動きを微調整しています。本研究は一見単純な問いを立てます:練習中に報酬や罰は、動作の途中での改善を助けるのか、それとも試行と試行の間だけで効果を発揮するのか?この答えは、動機づけと私たちの行動に自然に生じる試行間の差異が、新しい運動技能の習得にどのように寄与するかを明らかにします。
運動誤差から脳が学ぶ二つの経路
新しい状況や変化した状況で動くとき、脳は少なくとも二つの方法で学べます。一つは試行の間に計画を更新するルートです:前回の到達がどこでずれたかを見て、次の試行で狙いをわずかに変えます。もう一つは単一の動作の最中に即座に調整するルートです:視覚フィードバックが手の軌道のずれを示すと、制御系が動作の途中で修正を加えます。著者らは、これら二つの経路が報酬や罰によって異なる影響を受けるか、そして人々の初期動作に見られる自然な変動がそれぞれの場合に学習を助けるのか妨げるのかを調べました。
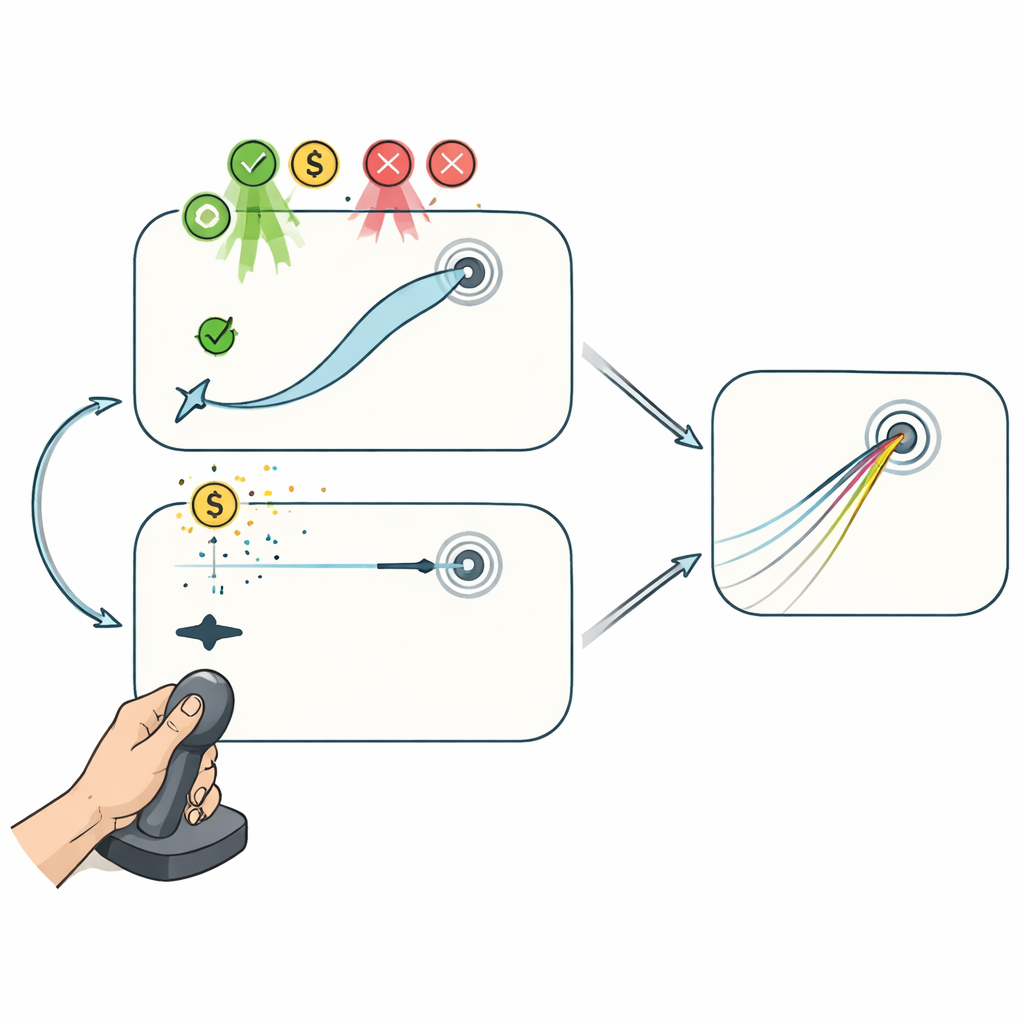
二つのジョイスティック課題:途中修正が可能なものと不可なもの
これらのプロセスを分けて調べるために、参加者は手の動きと画面上のカーソルの対応がこっそり回転される二つのジョイスティック課題を行いました。「Reaching(到達)」課題では、カーソルはジョイスティックに忠実に従い、参加者は動作の途中で軌道を曲げて目標に向かわせることができました。この設定では、試行間の計画変更と試行内での修正の両方が改善に寄与します。対照的に「Curling(カーリング)」課題では、ジョイスティック動作のごく初期の部分だけが結果を決め、それ以降はカーソルが短い距離を過ぎると直線的に滑り続けて影響を受けなくなりました。氷上のカーリングストーンに似た仕組みで、ここでは成績の向上は試行ごとに初期計画を調整することでしか起こりません。
動機づけは主に試行内の修正を高める、計画のみには影響しない
両課題を通して、参加者は視覚回転に徐々に適応し、明らかな運動適応、摂取効果(再訪時の速い回復)、および30分後の保持を示しました。しかし、試行内での修正を許すか否かは大きな違いを生みました:Reaching課題では、誤差はより小さくなり学習率はCurling課題より高くなりました。全体の適応の時間経過は似ていたにもかかわらず重要な差がありました。決定的なのは、成績に結び付けた報酬や罰はReaching課題でのみ効果を示したことです。正確な動きでより多く報酬を得る場合も、大きな誤差で罰金を失う場合も、参加者の成績は中立フィードバック群より優れました—ただしカーソルを連続的に操作できる場合に限ります。初期のショットの良さだけが成功を決める課題では、強化は検出可能な影響を与えませんでした。
計画時には有益な変動、修正中には抑えられる
研究者らはまた、回転が導入された最初期の段階で参加者の方向のばらつきがどれほどあったかを調べました。Curling課題では、初期の変動が大きい参加者ほど最終的な学習量が多く、初期の急速な改善を考慮に入れてもその相関は残りました。これは、修正が不可能な場合に、少し異なる計画を試すこと(著者が「計画ノイズ」と呼ぶ)が試行間でよりよい戦略を探索し洗練するのに役立つことを示唆します。一方Reaching課題では、初期の変動は主に最初の数試行での急速な誤差低減を反映しており、最終的な適応量を予測しませんでした。継続的な視覚フィードバックがシステムにリアルタイムで誤差を修正させるため、これらの初期差異の情報価値は抑えられるようです。
トレーニングとリハビリへの示唆
総じて、これらの結果は強化が主に動作が展開する間の修正能力を強化する一方で、動作開始時の自然な変動が主に試行間に起こる学習を支えることを示しています。日常の練習、スポーツコーチング、リハビリテーションにおいては、報酬や罰は連続的なフィードバックと調整を許す課題で最も効果的であり、逆に初期の試行での変動を意図的に活用することは、成功が初動のインパルスに依存する場合に特に有用である可能性があります。これら二つの学習経路を分離することで、本研究は過去の研究で報酬や罰の運動学習への効果が混在して報告されてきた理由を説明し、神経系の内在的な学習メカニズムと調和するような練習設計のより的確な方針を示唆します。
引用: Lehnberg, F.M., Paul, T., Wiemer, V.M. et al. Reinforcement drives within- not between-trial motor adaptation. Sci Rep 16, 11605 (2026). https://doi.org/10.1038/s41598-026-45293-8
キーワード: 運動学習, 強化(報酬), 運動の変動性, 視覚運動適応, 運動制御