Clear Sky Science · fr
La récompense favorise l’adaptation motrice pendant — et non entre — les essais
Comment la pratique et les gains façonnent nos mouvements
Des gestes quotidiens comme attraper une tasse de café ou lancer une balle semblent faciles, mais notre cerveau affine ces mouvements en permanence. Cette étude pose une question apparemment simple : lorsque nous nous entraînons, les récompenses et les punitions nous aident‑elles à nous améliorer pendant l’exécution d’un mouvement, ou seulement d’un essai à l’autre ? La réponse révèle comment la motivation et les variations naturelles d’un essai à l’autre se combinent pour modeler l’apprentissage de nouvelles habiletés motrices.
Deux manières d’apprendre des erreurs de mouvement
Lorsque nous bougeons dans une situation nouvelle ou modifiée, le cerveau peut apprendre au moins de deux façons. Une voie met à jour le plan entre les essais : après avoir vu où la dernière tentative a échoué, on ajuste subtilement la visée pour la suivante. L’autre voie corrige en temps réel pendant un même mouvement : dès que le retour visuel montre la main s’écarter, les systèmes de contrôle ajustent la trajectoire en cours. Les auteurs ont voulu savoir si ces deux voies sont influencées différemment par récompenses et punitions, et si la variabilité naturelle des premiers mouvements aide ou freine l’apprentissage dans chaque cas.
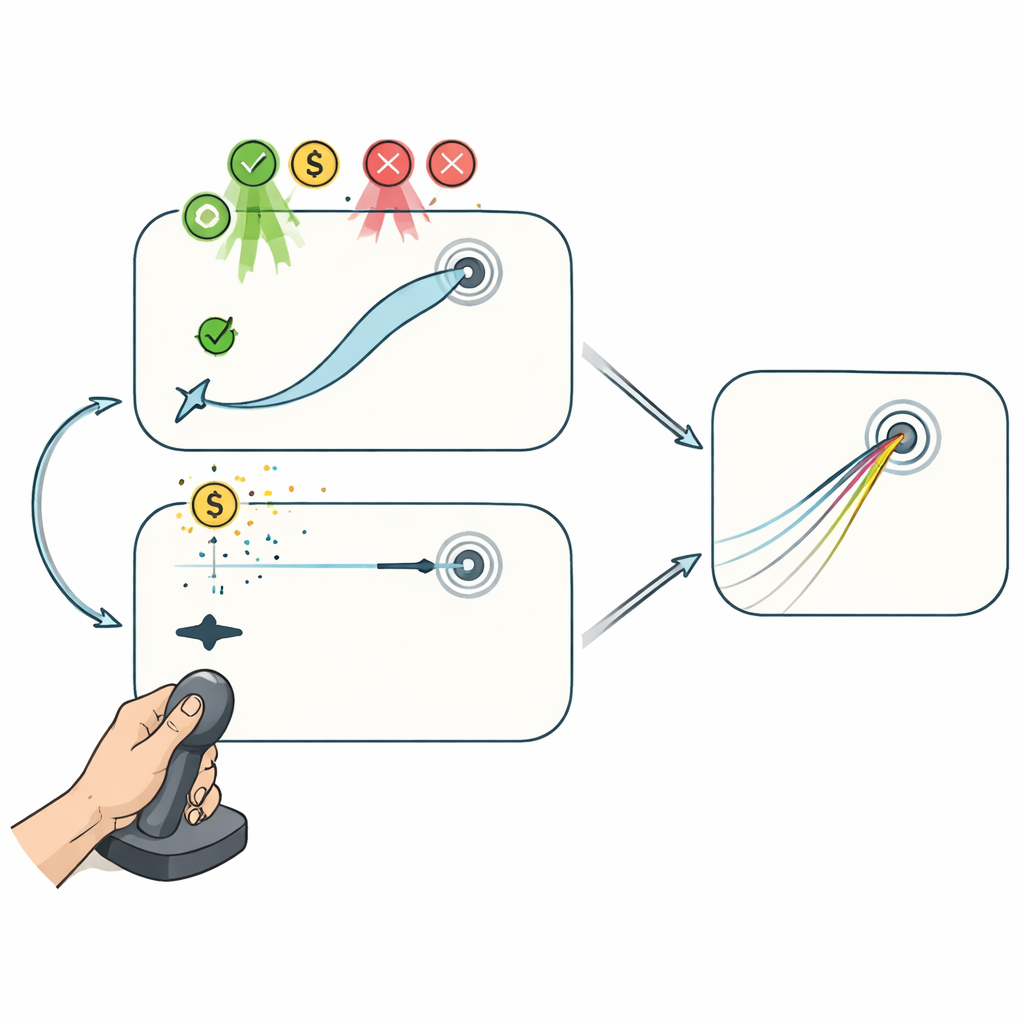
Deux jeux au joystick : avec et sans correction en cours de mouvement
Pour dissocier ces processus, des volontaires ont joué à deux tâches informatiques au joystick pendant que la relation entre le mouvement de la main et le curseur était discrètement tournée. Dans la tâche « Reaching », le curseur suivait fidèlement le joystick, permettant aux joueurs de courber leur trajectoire en plein mouvement pour viser la cible. Ce dispositif laisse à la fois la planification entre essais et la correction pendant l’essai contribuer à l’amélioration. Dans la tâche « Curling », en revanche, seule la toute première partie du mouvement au joystick comptait : une fois le curseur passé une courte distance, il glissait en ligne droite sans pouvoir être influencé, à la manière d’une pierre de curling sur la glace. Ici, l’amélioration ne pouvait venir que d’un ajustement du plan initial d’un essai à l’autre, pas d’une correction en cours de mouvement.
La motivation améliore la correction en cours, pas la planification seule
Dans les deux jeux, les participants ont progressivement compensé la rotation visuelle, montrant des signes clairs d’adaptation motrice, d’économies lors d’un retour à la perturbation et de rétention après une pause de trente minutes. Cependant, la possibilité de corriger en cours de route a fait une grande différence : dans le jeu Reaching, les erreurs ont diminué davantage et les taux d’apprentissage ont été plus élevés que dans le jeu Curling, bien que la dynamique globale de l’adaptation soit restée similaire. Surtout, les récompenses et les punitions liées à la performance ont amélioré les résultats uniquement dans la tâche Reaching. Que les participants gagnaient plus d’argent pour des mouvements précis ou perdaient de l’argent pour de grosses erreurs, leurs performances surpassaient celles d’un groupe témoin neutre — mais seulement quand ils pouvaient diriger le curseur en continu. Lorsque le succès dépendait uniquement d’un bon lancement initial, le renforcement n’a eu aucun effet détectable.
Variation utile pour la planification, atténuée pendant la correction
Les chercheurs ont aussi examiné combien les premiers mouvements des participants variaient en direction au moment de l’introduction de la rotation. Dans la tâche Curling, les participants qui montraient une plus grande variabilité initiale ont ensuite davantage appris, même en tenant compte des améliorations rapides initiales. Cela suggère que, quand les corrections sont impossibles, essayer différentes stratégies — ce que les auteurs appellent le « bruit de planification » — aide le cerveau à explorer et à affiner de meilleurs plans entre les essais. Dans la tâche Reaching, en revanche, la variabilité initiale reflétait surtout une réduction rapide des erreurs au cours des premières tentatives et ne prédisait pas l’ampleur finale de l’adaptation. Parce que le retour visuel continu permet de corriger les erreurs en temps réel, la valeur informationnelle de ces différences initiales semble être atténuée.
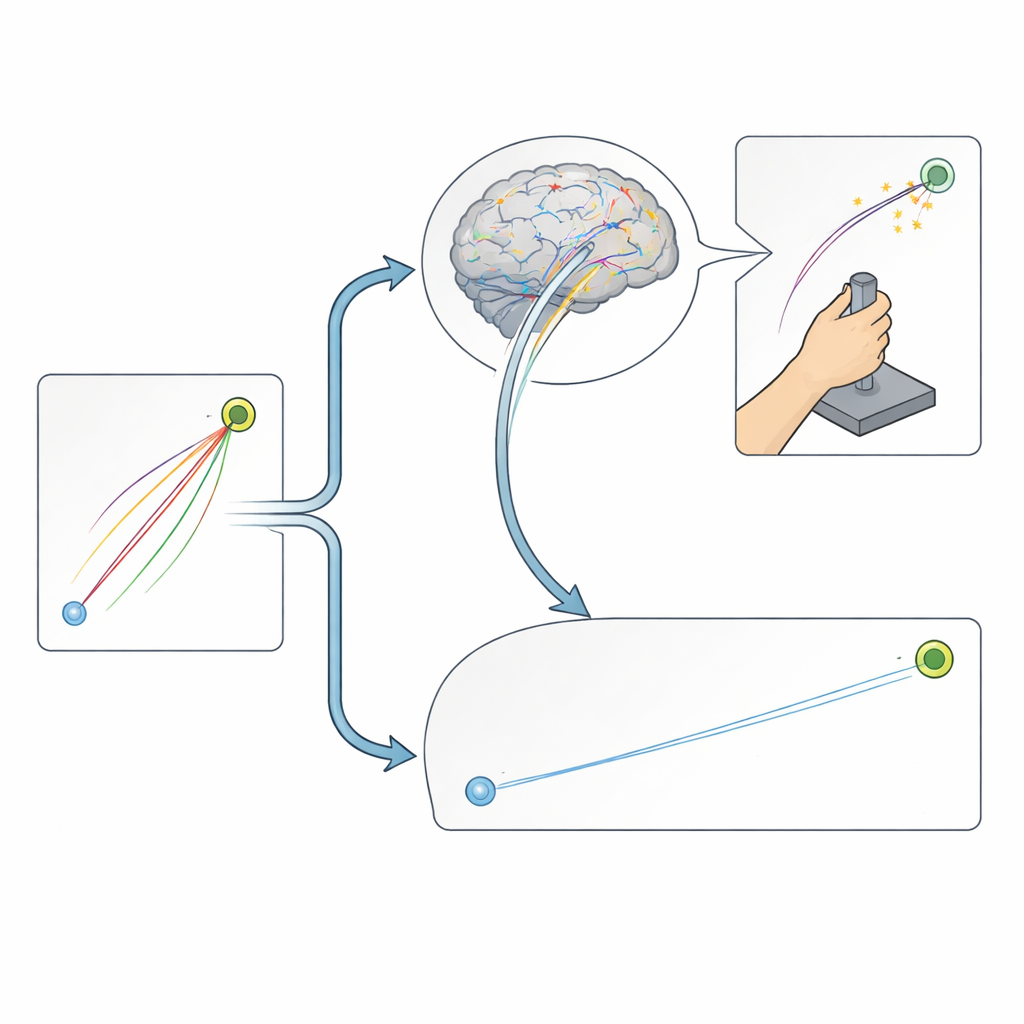
Pourquoi c’est important pour l’entraînement et la rééducation
Pris ensemble, ces résultats montrent que le renforcement renforce principalement la capacité du cerveau à corriger les mouvements au fur et à mesure qu’ils se déroulent, tandis que la variabilité naturelle du départ soutient surtout l’apprentissage qui se produit d’un essai à l’autre. Pour l’entraînement quotidien, le coaching sportif ou la rééducation, cela signifie que les récompenses ou les pénalités pourraient être les plus efficaces lorsque les tâches autorisent un feedback continu et des ajustements, alors qu’une gestion ciblée de la variation lors des premières tentatives pourrait être particulièrement utile quand seul l’impulsion initiale détermine le succès. En séparant ces deux voies d’apprentissage, l’étude aide à expliquer pourquoi des travaux antérieurs ont donné des effets mitigés du renforcement sur l’apprentissage moteur, et indique des pistes pour concevoir des pratiques plus adaptées aux mécanismes d’apprentissage intégrés de notre système nerveux.
Citation: Lehnberg, F.M., Paul, T., Wiemer, V.M. et al. Reinforcement drives within- not between-trial motor adaptation. Sci Rep 16, 11605 (2026). https://doi.org/10.1038/s41598-026-45293-8
Mots-clés: apprentissage moteur, renforcement, variabilité des mouvements, adaptation visuo‑motrice, contrôle moteur