Clear Sky Science · zh
FERMam:一种轻量级双源多尺度融合的面部表情识别框架
为什么教计算机“读”面孔很重要
我们的手机、汽车和家用设备在理解我们说话方面越来越好,但在感知我们的情绪时仍然力不从心。面部表情识别旨在改变这一点,使机器能够从照片或视频中的面部“读取”人类情绪。这可以让在线课堂更有反应性、驾驶员监控系统更安全、社交机器人更自然可交互。挑战在于如何在像手机、平板和服务机器人这类没有大型数据中心算力的日常设备上,做到既准确又快速。本文介绍了FERMam,一种旨在在明显减少计算开销的同时仍可靠读取表情的新方法。
从两种互补视角观察面孔
现有大多数系统从两种方式之一观察面部。卷积神经网络擅长捕捉局部细节,如皱纹或眉形,但难以处理面部较远部位之间的关联。基于变换器的模型能很好地捕获长距离关系,但通常很笨重、运行缓慢,不易在小型设备上部署。FERMam 通过一种“双源”设计结合了两者的优点。一条分支关注面部的整体外观,采用高效且能力强的图像编码器;另一条分支跟踪关键的面部标志点——眼周、口周及其他重要区域的点位。这些标志点强调面部几何信息,即使在光照、肤色或背景变化时也比较稳定。通过融合外观与几何信息,FERMam 能聚焦于那些真正显露情绪的微妙区域。
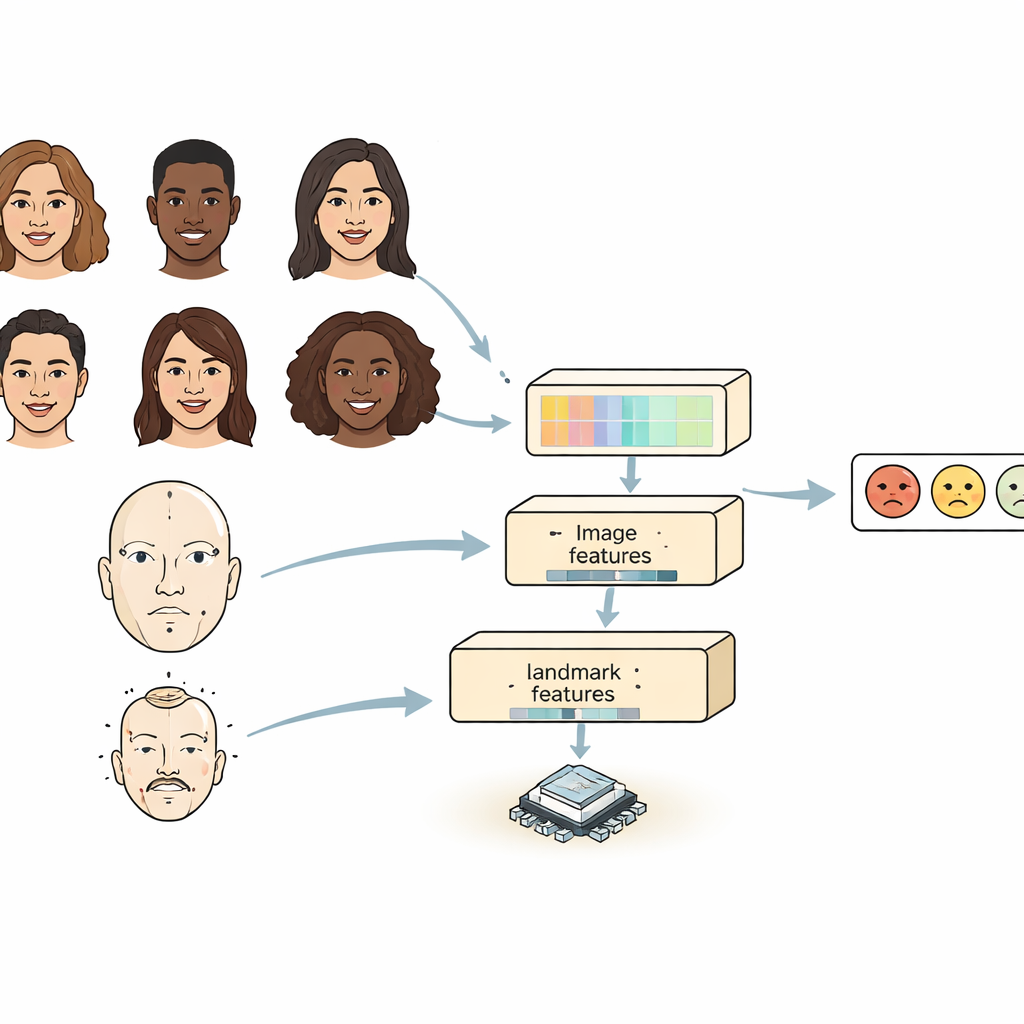
捕捉微小细节与全局格局
在提取出基础特征后,FERMam 将这些特征传入一个称为 Conv-SSM 的特殊模块。该模块中的一条路径行为类似传统卷积网络,强化眼周和口周等处的细微边缘与纹理;另一条路径使用一种较新的模型家族——状态空间模型,特别是一种名为 Mamba 的变体。与逐像素互比的方法不同,Mamba 在面部上以若干方向“扫描”,逐步建立特征随位置变化的记忆。这使系统能够捕获长程关系,例如眉毛上扬和嘴角紧绷共同表征愤怒的组合,同时将计算量控制在合理范围内。这两条路径的输出随后被巧妙重排并重新组合,使局部与全局信息得以交互。
跨不同尺度融合信息
情绪既可能在小范围的微小区域出现,也可能表现为整个面部的广泛变化。为此,FERMam 采用金字塔式融合结构。它在不同分辨率上创建若干版本的特征图,从粗到细对每一层使用自适应状态空间特征精炼模块进行处理。在每个尺度上,该模块通过轻量卷积强化重要的局部模式,然后利用简化的状态空间扫描将远端区域关联起来。内置的门控机制可增强来自眼睛和嘴巴等表情丰富区域的信号,同时抑制背景或身份特征带来的干扰。精炼后,各尺度的信息被重新汇聚,形成一个丰富而紧凑的摘要,最终交由一个小型分类器判断所显示的情绪。
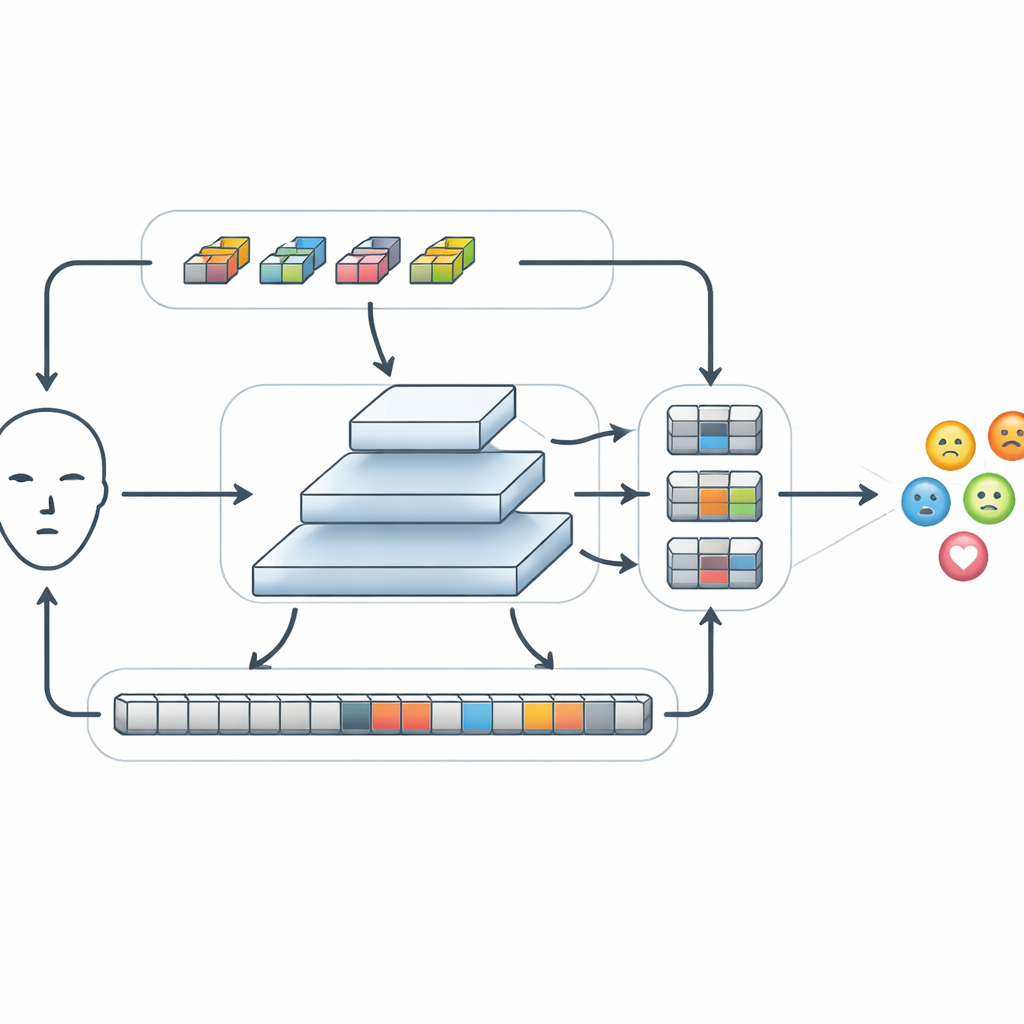
用更少算力匹配强大模型
作者在三个主要的面部表情基准数据集上测试了 FERMam:RAF-DB、AffectNet 和 FERPlus。这些集合包含来自真实世界场景的数万到数十万张面孔,涵盖多种光照、年龄和姿态。在这些数据集上,FERMam 达到了接近或优于许多依赖大型变换器架构的领先方法的准确率。在一个被广泛使用的数据集上,其表现几乎匹配已发表的最佳变换器系统,但参数量仅约为其三分之一到二分之一,计算操作也少得多。实际上,这意味着 FERMam 的运行速度可以超过两倍,在批量处理时每秒可处理更多图像,同时仍保持较高的识别质量。消融研究——通过移除设计的部分组件进行的对照实验——表明从标志点分支到金字塔融合的每个组件在这种平衡中都发挥了重要作用。
对日常技术的意义
简单来说,这项研究表明有可能构建既聪明又节省资源的情感识别系统。通过结合面部的两种视角——外观与形状——并精心组织信息在空间与尺度间的流动,FERMam 在不依赖超级计算机的情况下实现了强大的识别能力。这使其成为手机、家用机器人、驾驶辅助摄像头以及其他需要实时、敏感地响应人类情绪设备的有前景候选方案。尽管未来工作仍需应对遮挡严重或极低分辨率图像等更极端条件,FERMam 为实用、高效且更具人性化的计算指明了方向。
引用: Gao, C., Ji, X., Zhang, Q. et al. FERMam: a lightweight dual-source and multi-scale fusion framework for facial expression recognition. Sci Rep 16, 13826 (2026). https://doi.org/10.1038/s41598-026-44396-6
关键词: 面部表情识别, 情感感知人工智能, 轻量级深度学习, 状态空间模型, 人机交互