Clear Sky Science · ar
FERMam: إطار دمج خفيف الوزن بمصدرين ومتعدد المقاييس للتعرف على تعابير الوجه
لماذا يهم تعليم الحواسيب قراءة الوجوه
أجهزتنا المحمولة، والسيارات، وأجهزة المنزل الذكية تحسنت في فهم ما نقول، لكنها لا تزال تواجه صعوبة في استشعار ما نشعر به. يسعى التعرف على تعابير الوجه إلى تغيير ذلك عبر تمكين الآلات من «قراءة» المشاعر البشرية من الوجوه في الصور أو الفيديو. قد يجعل هذا الفصول الدراسية عبر الإنترنت أكثر استجابة، وأنظمة مراقبة السائقين أكثر أمانًا، والروبوتات الاجتماعية أسهل للتفاعل. والتحدي هو تحقيق ذلك بدقة وسرعة على الأجهزة اليومية مثل الهواتف والأجهزة اللوحية وروبوتات الخدمة التي لا تملك قدرة مراكز البيانات الكبيرة. يقدم هذا المقال FERMam، طريقة جديدة مصممة لقراءة التعابير بموثوقية بينما تستهلك طاقة حسابية أقل بكثير من العديد من الأنظمة الحالية.
رؤية الوجه من منظورين مفيدين
النظم الحالية تنظر إلى الوجه عادةً بطريقتين. الشبكات الالتفافية جيدة في كشف التفاصيل المحلية مثل التجاعيد أو أشكال الحواجب، لكنها تواجه صعوبة في إدراك العلاقة بين أجزاء بعيدة من الوجه. نماذج المحول (Transformer) تلتقط العلاقات بعيدة المدى جيدًا لكنها ثقيلة وبطيئة، مما يجعل تشغيلها صعبًا على الأجهزة الصغيرة. يجمع FERMam بين مزايا العالمين بتصميم «مصدرين». فرع واحد يركّز على المظهر العام للوجه باستخدام مُشفّر صور قوي لكن فعّال. والفرع الآخر يتتبع نقاط المعالم الرئيسية في الوجه — نقاط حول العينين والفم ومناطق مهمة أخرى. تؤكد هذه المعالم على هندسة الوجه، التي تظل مستقرة غالبًا حتى مع تغيّر الإضاءة أو لون البشرة أو الخلفية. من خلال مزج المظهر والهندسة، يستطيع FERMam التركيز على المناطق الدقيقة حيث تظهر المشاعر فعلًا.
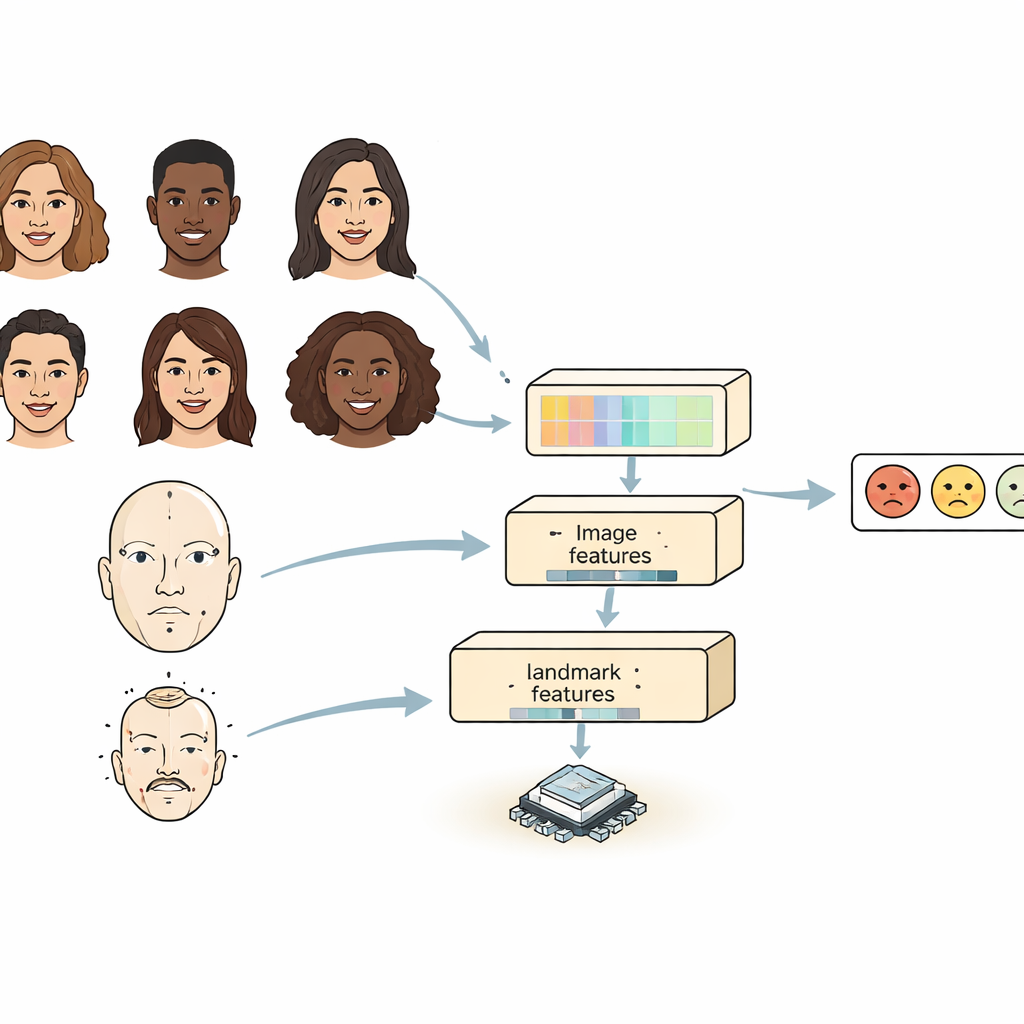
التقاط التفاصيل الصغيرة والصورة الكبيرة معًا
بعد استخراج الميزات الأساسية، يمرر FERMam هذه الميزات عبر وحدة خاصة تسمى Conv-SSM. مسار واحد في هذه الوحدة يتصرف كمثل شبكة التفافية تقليدية، حيث يُحسّن التفاصيل الدقيقة مثل الحواف والملمس حول العينين والفم. أما المسار الآخر فيستخدم فئة أحدث من النماذج المعروفة بنماذج الحالة الزمنية، وعلى وجه الخصوص متغيرًا يُسمى Mamba. بدلاً من مقارنة كل جزء من الصورة بكل جزء آخر، يقوم Mamba «بالمسح» عبر الوجه في عدة اتجاهات، مشكّلًا ذاكرة لكيفية تغير الميزات من مكان لآخر. هذا يمكّن النظام من التقاط العلاقات بعيدة المدى، مثل كيف أن رفع الحاجب وضم الفم معًا قد يشيران إلى الغضب، مع الحفاظ على التحكم في حسابات النظام. ثم تُعاد خلط مخرجات هذين المسارين بذكاء وتُركّب بحيث يمكن للمعلومات المحلية والعالمية أن تتفاعل.
مزج المعلومات عبر مقاييس مختلفة
يمكن أن تظهر المشاعر كتغيرات دقيقة في منطقة صغيرة أو كتحولات واسعة عبر كامل الوجه. للتعامل مع ذلك، يستخدم FERMam بنية دمج هرمية. ينشئ عدة نسخ من خارطة الميزات بدقات مختلفة، من الخشنة إلى الدقيقة، ويعالج كل مستوى بوحدة تنقية ميزات الحالة الزمنية التكيفية. في كل مقياس، تقوّي هذه الوحدة الأنماط المحلية المهمة عبر التفاف خفيف الوزن ثم تستخدم مسحًا بالحالة الزمنية المبسّط لربط المناطق البعيدة. يمكن لآلية بوّابة مدمجة أن تعزز الإشارات الواردة من المناطق الغنية بالتعبير، مثل العينين والفم، مع تقليل تأثير المشتتات من الخلفية أو التفاصيل الخاصة بالهوية. بعد التنقية، تُجمَع المعلومات من جميع المقاييس معًا لتشكّل ملخّصًا غنيًا ومضغوطًا يُمرَّر أخيرًا إلى مُصنِّف صغير ليقرر أي عاطفة تُعرض.
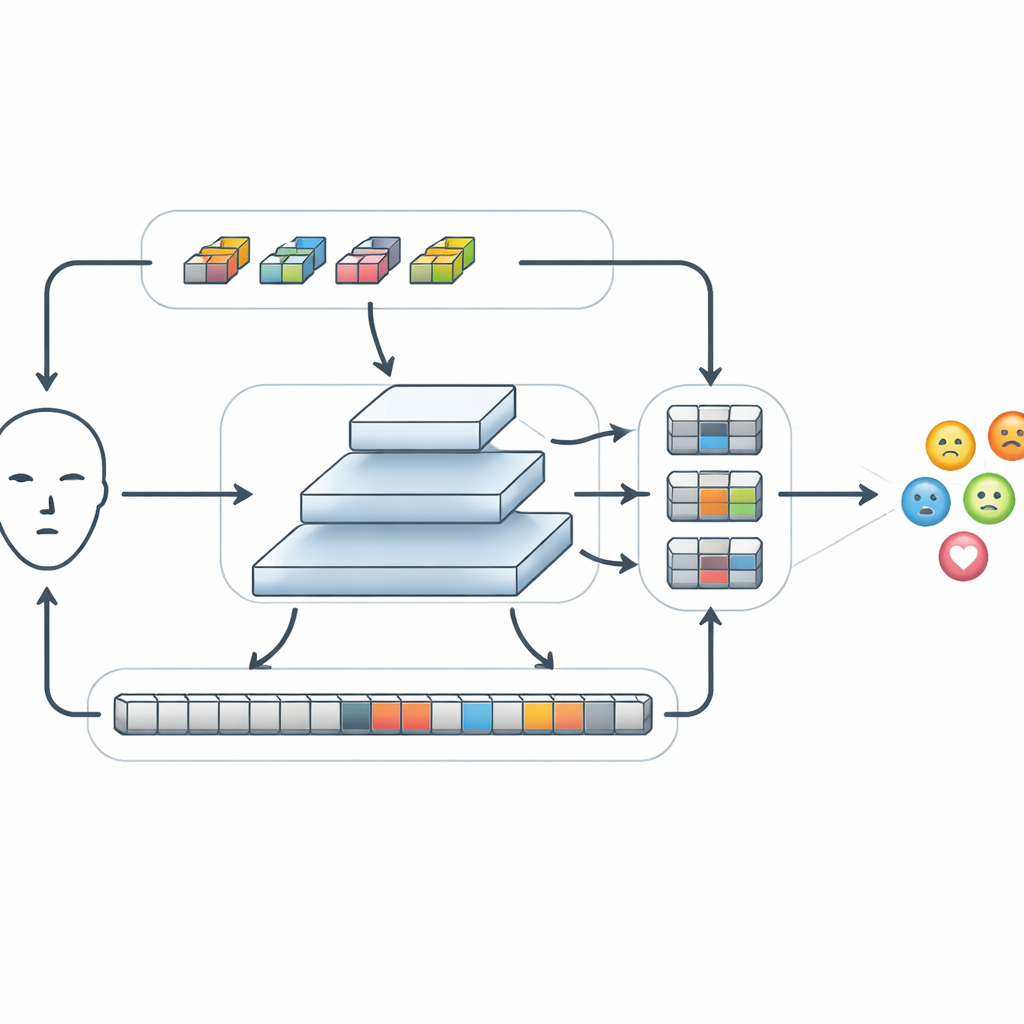
مضاهاة النماذج القوية مع حساب أقل بكثير
اختبر المؤلفون FERMam على ثلاث مجموعات معيارية رئيسية لتعبيرات الوجه: RAF-DB وAffectNet وFERPlus. تحتوي هذه المجموعات على عشرات إلى مئات الآلاف من الوجوه المأخوذة في ظروف العالم الحقيقي، بما في ذلك تفاوت الإضاءة والأعمار والوضعيات. على هذه المجموعات، بلغ FERMam مستويات دقة قريبة من أو أفضل من العديد من الطرق الرائدة التي تعتمد على هندسيات المحول الثقيلة. على مجموعة بيانات مستخدمة على نطاق واسع، يقارب أداؤه أفضل نظام منشور يعتمد على المحول، مع استخدامه تقريبًا ثلث إلى نصف عدد المعلمات وعددًا أقل بكثير من العمليات. عمليًا، يعني هذا أن FERMam يمكن أن يعمل بسرعة تفوق الضعف، ويعالج عددًا أكبر من الصور في الثانية عند التشغيل الدفعية، مع الحفاظ على جودة التعرف عالية. تُظهر دراسات الإقصاء — تجارب محكمة تُزال فيها أجزاء من التصميم — أن كل مكوّن، من فرع المعالم إلى الدمج الهرمي، يلعب دورًا مهمًا في هذا التوازن.
ماذا يعني هذا للتقنيات اليومية
بعبارات بسيطة، تُبيّن الدراسة أنه من الممكن بناء نظام لقراءة العواطف ذكي واقتصادي في آنٍ واحد. من خلال الجمع بين وجهتين للوجه — كيف يبدو وكيف يُشكّل — ومن خلال تنظيم دفق المعلومات عبر المكان والمقياس بعناية، يحقق FERMam تعرفًا قويًا دون طلب حاسوب فائق. هذا يجعله مرشحًا واعدًا للاستخدام في الهواتف، والروبوتات المنزلية، وكاميرات مساعدة السائق، وأجهزة أخرى تحتاج إلى الاستجابة بحساسية لمشاعر البشر في الوقت الفعلي. بينما سيتطلب العمل المستقبلي التعامل مع ظروف أكثر قساوة مثل التغطية الشديدة أو الصور منخفضة الدقة جدًا، يشير FERMam إلى طريق عملي وفعّال نحو حوسبة أكثر وعيًا بالإنسان.
الاستشهاد: Gao, C., Ji, X., Zhang, Q. et al. FERMam: a lightweight dual-source and multi-scale fusion framework for facial expression recognition. Sci Rep 16, 13826 (2026). https://doi.org/10.1038/s41598-026-44396-6
الكلمات المفتاحية: التعرف على تعابير الوجه, الذكاء الاصطناعي الواعي بالعاطفة, التعلّم العميق خفيف الوزن, نماذج الحالة الزمنية, التفاعل بين الإنسان والحاسوب