Clear Sky Science · de
FERMam: ein leichtgewichtiges Dual-Source- und Mehrskaliges Fusionsframework zur Gesichtsausdruckserkennung
Warum es wichtig ist, Computern das „Lesen“ von Gesichtern beizubringen
Unsere Telefone, Autos und Heimgeräte werden immer besser darin, zu verstehen, was wir sagen, doch beim Erfassen dessen, wie wir uns fühlen, bleiben sie hinterher. Die Gesichtsausdruckserkennung will das ändern, indem Maschinen lernen, menschliche Emotionen aus Gesichtern in Fotos oder Videos „abzulesen“. Das könnte Online‑Kurse reaktionsfähiger machen, Fahrerüberwachungssysteme sicherer gestalten und den Umgang mit Sozialrobotern natürlicher erscheinen lassen. Die Herausforderung besteht darin, dies genau und schnell auf Alltagsgeräten wie Telefonen, Tablets und Servicerobotern zu leisten, die nicht die Rechenkapazität eines großen Rechenzentrums haben. Dieser Artikel stellt FERMam vor, eine neue Methode, die darauf ausgelegt ist, Ausdrücke zuverlässig zu erkennen und dabei deutlich weniger Rechenleistung zu benötigen als viele aktuelle Systeme.
Das Gesicht aus zwei nützlichen Blickwinkeln sehen
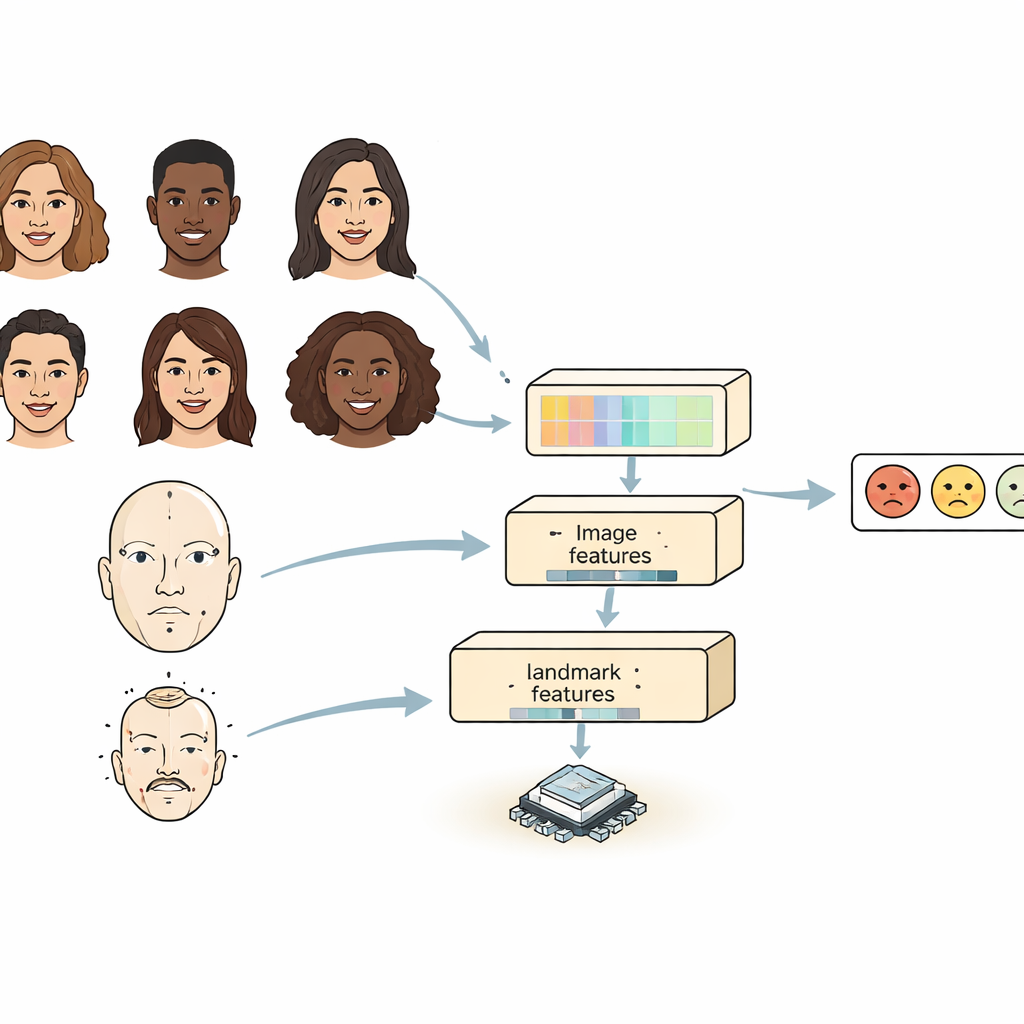
Die meisten bestehenden Systeme betrachten ein Gesicht auf eine von zwei Arten. Konvolutionelle neuronale Netze sind gut darin, lokale Details wie Falten oder Augenbrauenformen zu erfassen, haben aber Schwierigkeiten, Beziehungen zwischen weit entfernten Gesichtspartien zu erfassen. Transformer‑basierte Modelle erfassen langreichweitige Beziehungen gut, sind jedoch schwergewichtig und langsam, weshalb sie sich schlecht für kleine Geräte eignen. FERMam kombiniert die Stärken beider Welten mit einem „Dual‑Source“-Design. Ein Zweig konzentriert sich auf das Gesamtbild des Gesichts und verwendet einen leistungsfähigen, aber effizienten Bildencoder. Der andere Zweig verfolgt wichtige Gesichtslandmarken — Punkte rund um Augen, Mund und andere relevante Regionen. Diese Landmarken betonen die Geometrie des Gesichts, die selbst bei wechselnder Beleuchtung, Hautfarbe oder Hintergrund relativ stabil bleibt. Durch die Verknüpfung von Erscheinungsbild und Geometrie kann FERMam sich auf die subtilen Bereiche konzentrieren, in denen Emotionen wirklich sichtbar werden.
Sowohl kleine Details als auch das große Ganze erfassen
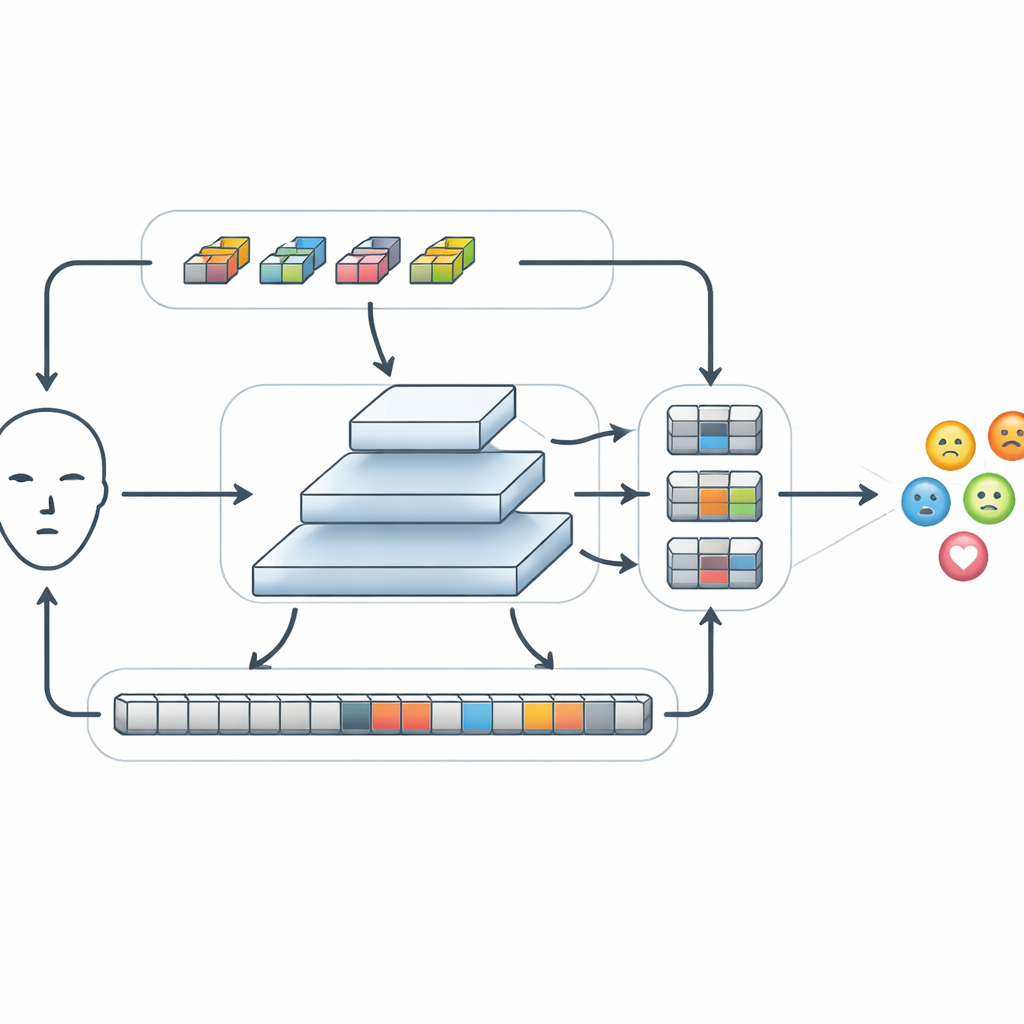
Nachdem grundlegende Merkmale extrahiert wurden, führt FERMam sie durch ein spezielles Modul namens Conv‑SSM. Ein Pfad in diesem Modul verhält sich wie ein traditionelles Konvolutionsnetz und schärft feine Details wie Kanten und Texturen rund um Augen und Mund. Der andere Pfad verwendet eine neuere Modellfamilie, bekannt als Zustandsraum‑Modelle, insbesondere eine Variante namens Mamba. Anstatt jeden Bildteil mit jedem anderen zu vergleichen, „scannt“ Mamba in mehreren Richtungen über das Gesicht und baut so ein Gedächtnis dafür auf, wie sich Merkmale von Stelle zu Stelle verändern. Das ermöglicht dem System, langreichweitige Beziehungen zu erfassen — etwa wie eine hochgezogene Augenbraue in Kombination mit einem angespannten Mund Wut signalisieren kann — und gleichzeitig den Rechenaufwand in Grenzen zu halten. Die Ausgaben beider Pfade werden anschließend geschickt neu angeordnet und wieder kombiniert, sodass lokale und globale Informationen miteinander interagieren können.
Informationen über verschiedene Skalen hinweg verschmelzen
Emotionen können sich als winzige Veränderungen in einer kleinen Region oder als breite Verschiebungen über das gesamte Gesicht zeigen. Um damit umzugehen, verwendet FERMam eine Pyramid‑Fusionsstruktur. Sie erzeugt mehrere Versionen der Merkmalskarte in unterschiedlichen Auflösungen, von grob bis fein, und verarbeitet jede Ebene mit einem Adaptive State‑space Feature Refinement‑Modul. Auf jeder Skala stärkt dieses Modul wichtige lokale Muster durch leichtgewichtige Faltungen und nutzt dann einen schlanken Zustandsraum‑Scan, um entfernte Regionen zu verknüpfen. Ein eingebauter Gate‑Mechanismus kann Signale aus ausdrucksreichen Bereichen wie Augen und Mund verstärken und gleichzeitig Ablenkungen durch Hintergrund oder identitätsspezifische Details abschwächen. Nach der Verfeinerung werden die Informationen aller Skalen wieder zusammengeführt und bilden eine reichhaltige, dennoch kompakte Zusammenfassung, die schließlich an einen kleinen Klassifikator übergeben wird, der entscheidet, welche Emotion gezeigt wird.
Leistungsfähige Modelle mit deutlich weniger Rechenaufwand erreichen
Die Autoren testeten FERMam auf drei wichtigen Benchmarks zur Gesichtsausdruckserkennung: RAF‑DB, AffectNet und FERPlus. Diese Datensätze enthalten zehntausende bis hunderttausende Gesichter aus realen Bedingungen, inklusive variierender Beleuchtung, Altersstufen und Posen. Auf diesen Datensätzen erreichte FERMam Genauigkeitswerte, die nah an viele führende Methoden mit schweren Transformer‑Architekturen heranreichen oder diese übertreffen. Auf einem weit verbreiteten Datensatz kommt seine Leistung der besten publizierten Transformer‑basierten Lösung nahezu gleich, verwendet dabei jedoch etwa ein Drittel bis die Hälfte der Parameter und deutlich weniger Rechenoperationen. Praktisch bedeutet das, dass FERMam mehr als doppelt so schnell laufen kann, viele mehr Bilder pro Sekunde im Batch‑Modus verarbeiten kann und trotzdem eine hohe Erkennungsqualität beibehält. Ablationsstudien — kontrollierte Experimente, in denen Teile des Designs entfernt werden — zeigen, dass jede Komponente, vom Landmarken‑Zweig bis zur Pyramid‑Fusion, eine sinnvolle Rolle in diesem Kompromiss spielt.
Was das für Alltagstechnologien bedeutet
Kurz gesagt zeigt die Studie, dass es möglich ist, ein Emotionslesesystem zu bauen, das zugleich leistungsfähig und sparsam ist. Indem zwei Sichtweisen auf das Gesicht kombiniert werden — wie es aussieht und wie es geformt ist — und indem die Informationsflüsse über Raum und Skala sorgfältig organisiert werden, erzielt FERMam starke Erkennungsleistung, ohne einen Supercomputer zu verlangen. Das macht es zu einem vielversprechenden Kandidaten für den Einsatz in Telefonen, Heimrobotern, Fahrerassistenzkameras und anderen Geräten, die in Echtzeit sensibel auf menschliche Emotionen reagieren müssen. Während zukünftige Arbeiten extremere Bedingungen wie starke Verdeckungen oder sehr niedrig aufgelöste Bilder angehen müssen, weist FERMam den Weg zu praktischer, effizienter und menschen‑näherer Datenverarbeitung.
Zitation: Gao, C., Ji, X., Zhang, Q. et al. FERMam: a lightweight dual-source and multi-scale fusion framework for facial expression recognition. Sci Rep 16, 13826 (2026). https://doi.org/10.1038/s41598-026-44396-6
Schlüsselwörter: Gesichtsausdruckserkennung, emotionsbewusste KI, leichtgewichtetes Deep Learning, Zustandsraum‑Modelle, Mensch‑Computer‑Interaktion